This is an automated email from the ASF dual-hosted git repository.
yumwang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e683fe880fb [SPARK-39217][SQL] Makes DPP support the pruning side has
Union
e683fe880fb is described below
commit e683fe880fb5599a0089f79170896971e8887e49
Author: Kun Wan <[email protected]>
AuthorDate: Fri Jan 13 21:44:24 2023 +0800
[SPARK-39217][SQL] Makes DPP support the pruning side has Union
### What changes were proposed in this pull request?
Makes DPP support the pruning side has `Union`. For example:
```sql
SELECT f.store_id,
f.date_id,
s.state_province
FROM (SELECT 4 AS store_id,
date_id,
product_id
FROM fact_sk
WHERE date_id >= 1300
UNION ALL
SELECT store_id,
date_id,
product_id
FROM fact_stats
WHERE date_id <= 1000) f
JOIN dim_store s
ON f.store_id = s.store_id
WHERE s.country IN ('US', 'NL')
```
After this PR:
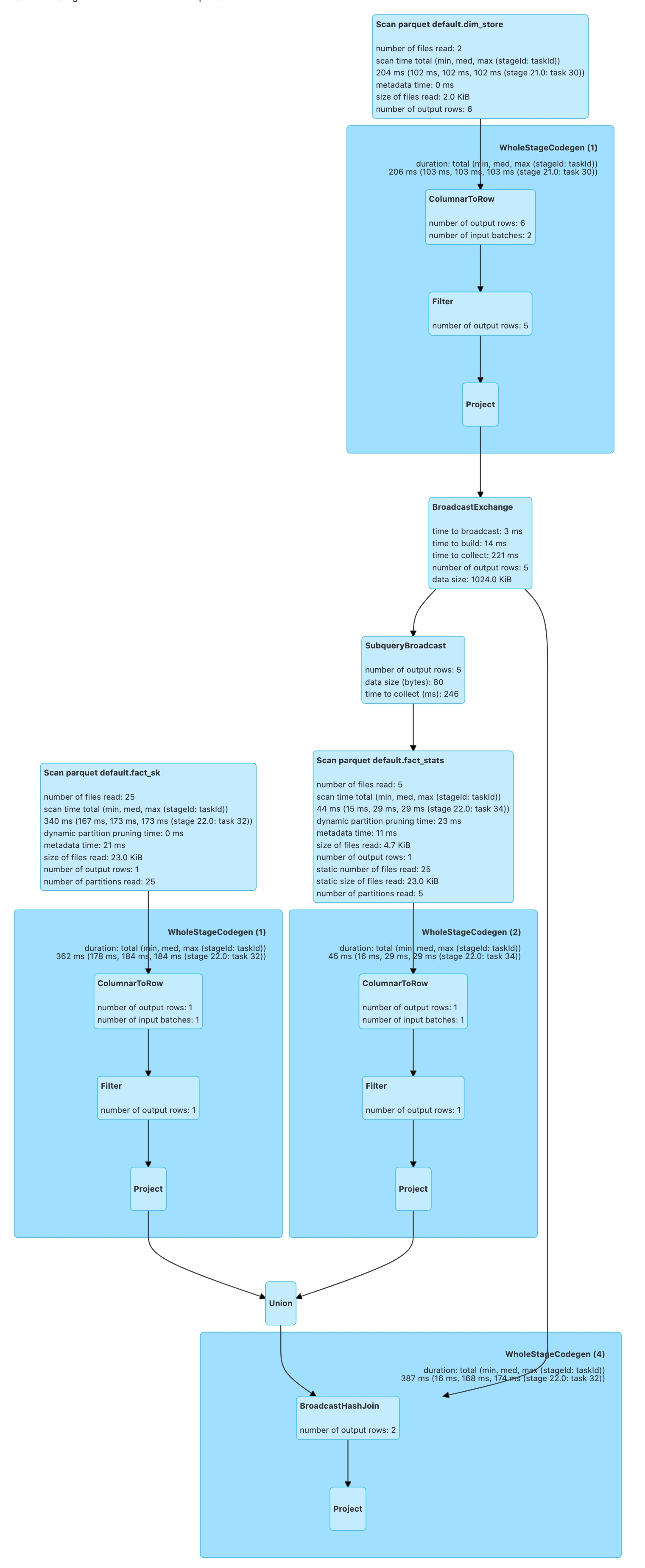
### Why are the changes needed?
Improve query performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes #39460 from wankunde/SPARK-39217.
Authored-by: Kun Wan <[email protected]>
Signed-off-by: Yuming Wang <[email protected]>
---
.../sql/catalyst/expressions/predicates.scala | 11 +++++++-
.../spark/sql/DynamicPartitionPruningSuite.scala | 30 ++++++++++++++++++++++
2 files changed, 40 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/predicates.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/predicates.scala
index 6a58f8d3416..b7d7c5e700e 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/predicates.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/predicates.scala
@@ -27,7 +27,7 @@ import
org.apache.spark.sql.catalyst.expressions.BindReferences.bindReference
import org.apache.spark.sql.catalyst.expressions.Cast._
import org.apache.spark.sql.catalyst.expressions.codegen._
import org.apache.spark.sql.catalyst.expressions.codegen.Block._
-import org.apache.spark.sql.catalyst.plans.logical.{Aggregate, LeafNode,
LogicalPlan, Project}
+import org.apache.spark.sql.catalyst.plans.logical.{Aggregate, LeafNode,
LogicalPlan, Project, Union}
import org.apache.spark.sql.catalyst.trees.TreePattern._
import org.apache.spark.sql.catalyst.util.TypeUtils
import org.apache.spark.sql.internal.SQLConf
@@ -124,6 +124,15 @@ trait PredicateHelper extends AliasHelper with Logging {
findExpressionAndTrackLineageDown(replaceAlias(exp, aliasMap), a.child)
case l: LeafNode if exp.references.subsetOf(l.outputSet) =>
Some((exp, l))
+ case u: Union =>
+ val index = u.output.indexWhere(_.semanticEquals(exp))
+ if (index > -1) {
+ u.children
+ .flatMap(child =>
findExpressionAndTrackLineageDown(child.output(index), child))
+ .headOption
+ } else {
+ None
+ }
case other =>
other.children.flatMap {
child => if (exp.references.subsetOf(child.outputSet)) {
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
index ff78af7e636..f33432ddb6f 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
@@ -1616,6 +1616,36 @@ abstract class DynamicPartitionPruningSuiteBase
assert(collectDynamicPruningExpressions(df.queryExecution.executedPlan).size
=== 1)
}
}
+
+ test("SPARK-39217: Makes DPP support the pruning side has Union") {
+ withSQLConf(SQLConf.DYNAMIC_PARTITION_PRUNING_ENABLED.key -> "true") {
+ val df = sql(
+ """
+ |SELECT f.store_id,
+ | f.date_id,
+ | s.state_province
+ |FROM (SELECT 4 AS store_id,
+ | date_id,
+ | product_id
+ | FROM fact_sk
+ | WHERE date_id >= 1300
+ | UNION ALL
+ | SELECT store_id,
+ | date_id,
+ | product_id
+ | FROM fact_stats
+ | WHERE date_id <= 1000) f
+ |JOIN dim_store s
+ |ON f.store_id = s.store_id
+ |WHERE s.country IN ('US', 'NL')
+ |""".stripMargin)
+
+ checkPartitionPruningPredicate(df, withSubquery = false, withBroadcast =
true)
+ checkAnswer(df, Row(4, 1300, "California") :: Row(1, 1000,
"North-Holland") :: Nil)
+ // CleanupDynamicPruningFilters should remove DPP in first child of union
+
assert(collectDynamicPruningExpressions(df.queryExecution.executedPlan).size
=== 1)
+ }
+ }
}
abstract class DynamicPartitionPruningDataSourceSuiteBase
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}