This is an automated email from the ASF dual-hosted git repository.
kabhwan pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 27c34bd978f [SPARK-42591][SS][DOCS] Add examples of unblocked
workloads after SPARK-42376
27c34bd978f is described below
commit 27c34bd978f976b509cdefff7f179b2779012eae
Author: Jungtaek Lim <[email protected]>
AuthorDate: Wed Mar 8 05:23:25 2023 +0900
[SPARK-42591][SS][DOCS] Add examples of unblocked workloads after
SPARK-42376
### What changes were proposed in this pull request?
This PR proposes to add examples of unblocked workloads after SPARK-42376,
which unblocks stream-stream time interval join followed by stateful operator.
### Why are the changes needed?
We'd like to remove the description of limitations which no longer exist,
as well as provide some code examples so that users can get some sense how to
use the functionality.
### Does this PR introduce _any_ user-facing change?
Yes, documentation change.
### How was this patch tested?
Created a page via SKIP_API=1 bundle exec jekyll serve --watch and
confirmed.
Screenshots:
> Scala
> Java
> Python
Closes #40215 from HeartSaVioR/SPARK-42591.
Authored-by: Jungtaek Lim <[email protected]>
Signed-off-by: Jungtaek Lim <[email protected]>
---
docs/structured-streaming-programming-guide.md | 130 ++++++++++++++++++++++++-
1 file changed, 126 insertions(+), 4 deletions(-)
diff --git a/docs/structured-streaming-programming-guide.md
b/docs/structured-streaming-programming-guide.md
index cf7f0ab6e15..a71c774f328 100644
--- a/docs/structured-streaming-programming-guide.md
+++ b/docs/structured-streaming-programming-guide.md
@@ -1928,12 +1928,134 @@ Additional details on supported joins:
- As of Spark 2.4, you can use joins only when the query is in Append output
mode. Other output modes are not yet supported.
-- As of Spark 2.4, you cannot use other non-map-like operations before joins.
Here are a few examples of
- what cannot be used.
+- You cannot use mapGroupsWithState and flatMapGroupsWithState before and
after joins.
- - Cannot use streaming aggregations before joins.
+In append output mode, you can construct a query having non-map-like
operations e.g. aggregation, deduplication, stream-stream join before/after
join.
- - Cannot use mapGroupsWithState and flatMapGroupsWithState in Update mode
before joins.
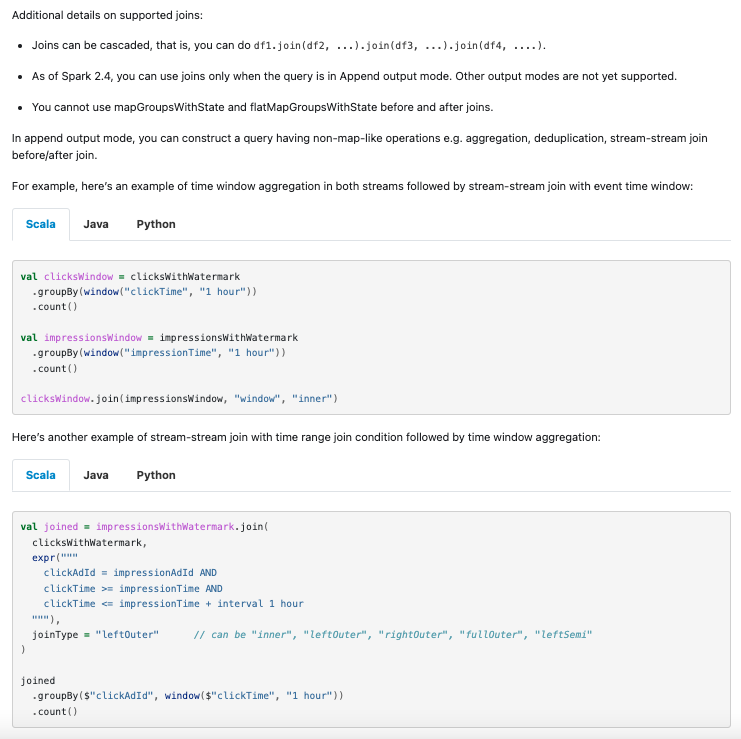
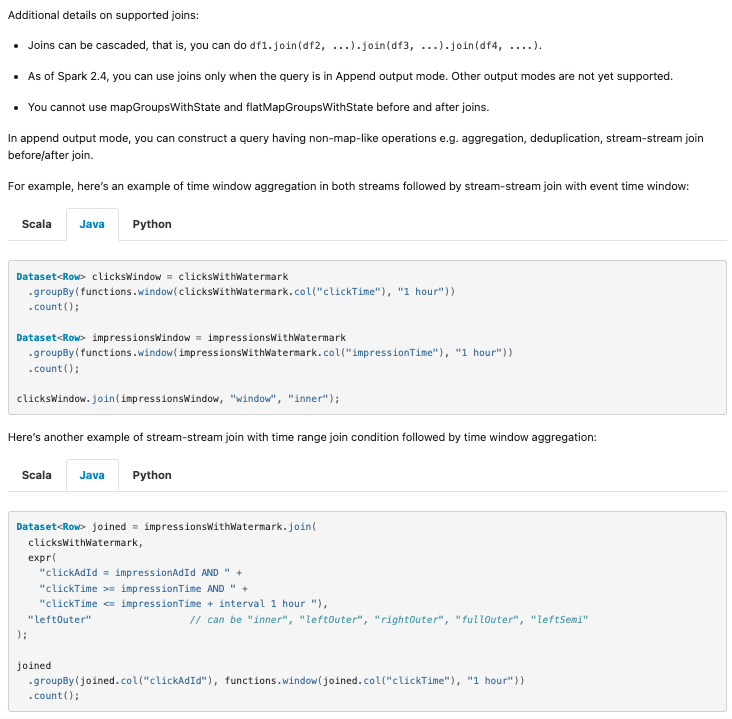
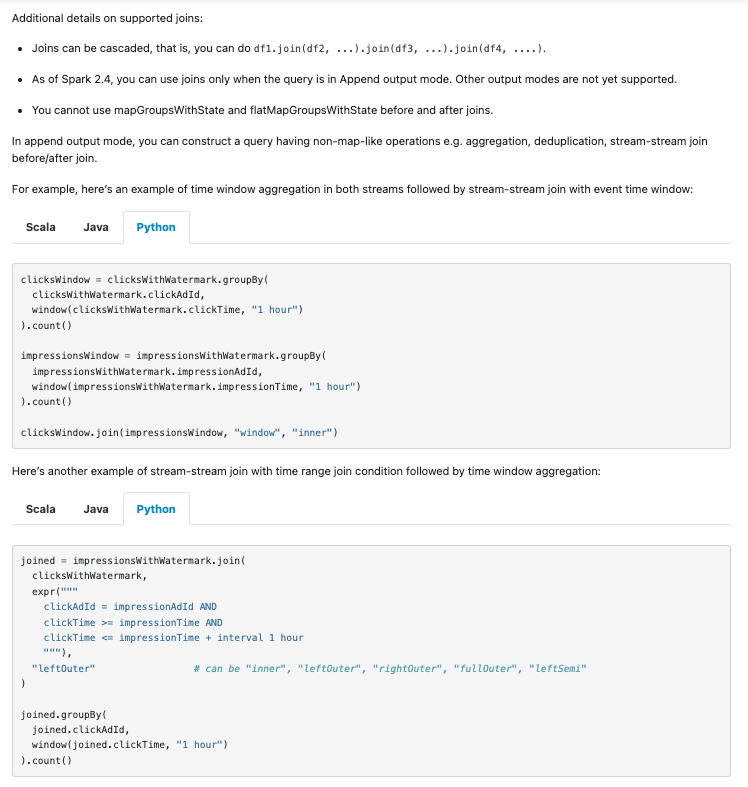
+For example, here's an example of time window aggregation in both streams
followed by stream-stream join with event time window:
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+
+val clicksWindow = clicksWithWatermark
+ .groupBy(window("clickTime", "1 hour"))
+ .count()
+
+val impressionsWindow = impressionsWithWatermark
+ .groupBy(window("impressionTime", "1 hour"))
+ .count()
+
+clicksWindow.join(impressionsWindow, "window", "inner")
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+
+Dataset<Row> clicksWindow = clicksWithWatermark
+ .groupBy(functions.window(clicksWithWatermark.col("clickTime"), "1 hour"))
+ .count();
+
+Dataset<Row> impressionsWindow = impressionsWithWatermark
+ .groupBy(functions.window(impressionsWithWatermark.col("impressionTime"), "1
hour"))
+ .count();
+
+clicksWindow.join(impressionsWindow, "window", "inner");
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+clicksWindow = clicksWithWatermark.groupBy(
+ clicksWithWatermark.clickAdId,
+ window(clicksWithWatermark.clickTime, "1 hour")
+).count()
+
+impressionsWindow = impressionsWithWatermark.groupBy(
+ impressionsWithWatermark.impressionAdId,
+ window(impressionsWithWatermark.impressionTime, "1 hour")
+).count()
+
+clicksWindow.join(impressionsWindow, "window", "inner")
+
+{% endhighlight %}
+
+</div>
+</div>
+
+Here's another example of stream-stream join with time range join condition
followed by time window aggregation:
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+
+val joined = impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """),
+ joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter",
"fullOuter", "leftSemi"
+)
+
+joined
+ .groupBy($"clickAdId", window($"clickTime", "1 hour"))
+ .count()
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+Dataset<Row> joined = impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "),
+ "leftOuter" // can be "inner", "leftOuter", "rightOuter",
"fullOuter", "leftSemi"
+);
+
+joined
+ .groupBy(joined.col("clickAdId"), functions.window(joined.col("clickTime"),
"1 hour"))
+ .count();
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+joined = impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """),
+ "leftOuter" # can be "inner", "leftOuter", "rightOuter",
"fullOuter", "leftSemi"
+)
+
+joined.groupBy(
+ joined.clickAdId,
+ window(joined.clickTime, "1 hour")
+).count()
+
+{% endhighlight %}
+
+</div>
+</div>
### Streaming Deduplication
You can deduplicate records in data streams using a unique identifier in the
events. This is exactly same as deduplication on static using a unique
identifier column. The query will store the necessary amount of data from
previous records such that it can filter duplicate records. Similar to
aggregations, you can use deduplication with or without watermarking.
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}