This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 76e4425efc2 [SPARK-42753] ReusedExchange refers to non-existent nodes
76e4425efc2 is described below
commit 76e4425efc22218fba04ad0aba8e6c1f6bb4954a
Author: Steven Chen <[email protected]>
AuthorDate: Wed Mar 22 09:28:18 2023 +0800
[SPARK-42753] ReusedExchange refers to non-existent nodes
### What changes were proposed in this pull request?
This PR addresses a rare bug with the EXPLAIN function and Spark UI that
can happen when AQE takes effect with multiple ReusedExchange nodes. The bug
causes the ReusedExchange to point to an unknown child since that child subtree
was "pruned" in a previous AQE iteration.
This PR fixes the issue by finding all the ReusedExchange nodes in the tree
that have a `child` node that has NOT been processed in the final plan (meaning
it has no ID or it has an incorrect ID generated from the previous AQE
iteration). It then traverses the child subtree and generates correct IDs for
them. We print this missing subtree in a new section called `Adaptively
Optimized Out Exchanges`.
### Why are the changes needed?
Below is an example to demonstrate the root cause:
> AdaptiveSparkPlan
> |-- SomeNode X (subquery xxx)
> |-- Exchange A
> |-- SomeNode Y
> |-- Exchange B
>
> Subquery:Hosting operator = SomeNode Hosting Expression = xxx
dynamicpruning#388
> AdaptiveSparkPlan
> |-- SomeNode M
> |-- Exchange C
> |-- SomeNode N
> |-- Exchange D
>
Step 1: Exchange B is materialized and the QueryStage is added to stage
cache
Step 2: Exchange D reuses Exchange B
Step 3: Exchange C is materialized and the QueryStage is added to stage
cache
Step 4: Exchange A reuses Exchange C
Then the final plan looks like:
> AdaptiveSparkPlan
> |-- SomeNode X (subquery xxx)
> |-- Exchange A -> ReusedExchange (reuses Exchange C)
>
>
> Subquery:Hosting operator = SomeNode Hosting Expression = xxx
dynamicpruning#388
> AdaptiveSparkPlan
> |-- SomeNode M
> |-- Exchange C -> PhotonShuffleMapStage ....
> |-- SomeNode N
> |-- Exchange D -> ReusedExchange (reuses Exchange B)
>
As a result, the ReusedExchange (reuses Exchange B) will refer to a
non-exist node.
### Does this PR introduce _any_ user-facing change?
**Explain Text Before and After**
**Before:**
```
+- ReusedExchange (105)
(105) ReusedExchange [Reuses operator id: unknown]
Output [3]: [sr_customer_sk#303, sr_store_sk#307, sum#413L]
```
**After:**
```
+- ReusedExchange (105)
+- Exchange (132)
+- * HashAggregate (131)
+- * Project (130)
+- * BroadcastHashJoin Inner BuildRight (129)
:- * Filter (128)
: +- * ColumnarToRow (127)
: +- Scan parquet
hive_metastore.tpcds_sf1000_delta.store_returns (126)
+- ShuffleQueryStage (115), Statistics(sizeInBytes=5.7 KiB,
rowCount=366, [d_date_sk#234 ->
ColumnStat(Some(362),Some(2415022),Some(2488070),Some(0),Some(4),Some(4),None,2)],
isRuntime=true)
+- ReusedExchange (114)
(105) ReusedExchange [Reuses operator id: 132]
Output [3]: [sr_customer_sk#217, sr_store_sk#221, sum#327L]
(126) Scan parquet hive_metastore.tpcds_sf1000_delta.store_returns
Output [4]: [sr_customer_sk#217, sr_store_sk#221, sr_return_amt#225,
sr_returned_date_sk#214]
Batched: true
Location: PreparedDeltaFileIndex
[dbfs:/mnt/performance-datasets/2018TPC/tpcds-2.4/sf1000_delta/store_returns]
PartitionFilters: [isnotnull(sr_returned_date_sk#214),
dynamicpruningexpression(sr_returned_date_sk#214 IN dynamicpruning#329)]
PushedFilters: [IsNotNull(sr_store_sk)]
ReadSchema:
struct<sr_customer_sk:int,sr_store_sk:int,sr_return_amt:decimal(7,2)>
(127) ColumnarToRow
Input [4]: [sr_customer_sk#217, sr_store_sk#221, sr_return_amt#225,
sr_returned_date_sk#214]
(128) Filter
Input [4]: [sr_customer_sk#217, sr_store_sk#221, sr_return_amt#225,
sr_returned_date_sk#214]
Condition : isnotnull(sr_store_sk#221)
(114) ReusedExchange [Reuses operator id: 8]
Output [1]: [d_date_sk#234]
(115) ShuffleQueryStage
Output [1]: [d_date_sk#234]
Arguments: 2, Statistics(sizeInBytes=5.7 KiB, rowCount=366, [d_date_sk#234
->
ColumnStat(Some(362),Some(2415022),Some(2488070),Some(0),Some(4),Some(4),None,2)],
isRuntime=true)
(129) BroadcastHashJoin
Left keys [1]: [sr_returned_date_sk#214]
Right keys [1]: [d_date_sk#234]
Join type: Inner
Join condition: None
(130) Project
Output [3]: [sr_customer_sk#217, sr_store_sk#221, sr_return_amt#225]
Input [5]: [sr_customer_sk#217, sr_store_sk#221, sr_return_amt#225,
sr_returned_date_sk#214, d_date_sk#234]
(131) HashAggregate
Input [3]: [sr_customer_sk#217, sr_store_sk#221, sr_return_amt#225]
Keys [2]: [sr_customer_sk#217, sr_store_sk#221]
Functions [1]: [partial_sum(UnscaledValue(sr_return_amt#225)) AS sum#327L]
Aggregate Attributes [1]: [sum#326L]
Results [3]: [sr_customer_sk#217, sr_store_sk#221, sum#327L]
(132) Exchange
Input [3]: [sr_customer_sk#217, sr_store_sk#221, sum#327L]
Arguments: hashpartitioning(sr_store_sk#221, 200), ENSURE_REQUIREMENTS,
[plan_id=1791]
```
**Spark UI Before and After**
**Before:**
<img width="339" alt="Screenshot 2023-03-10 at 10 52 46 AM"
src="https://user-images.githubusercontent.com/83618776/224406011-e622ad11-37e6-48c6-b556-cd5c7708e237.png";>
**After:**
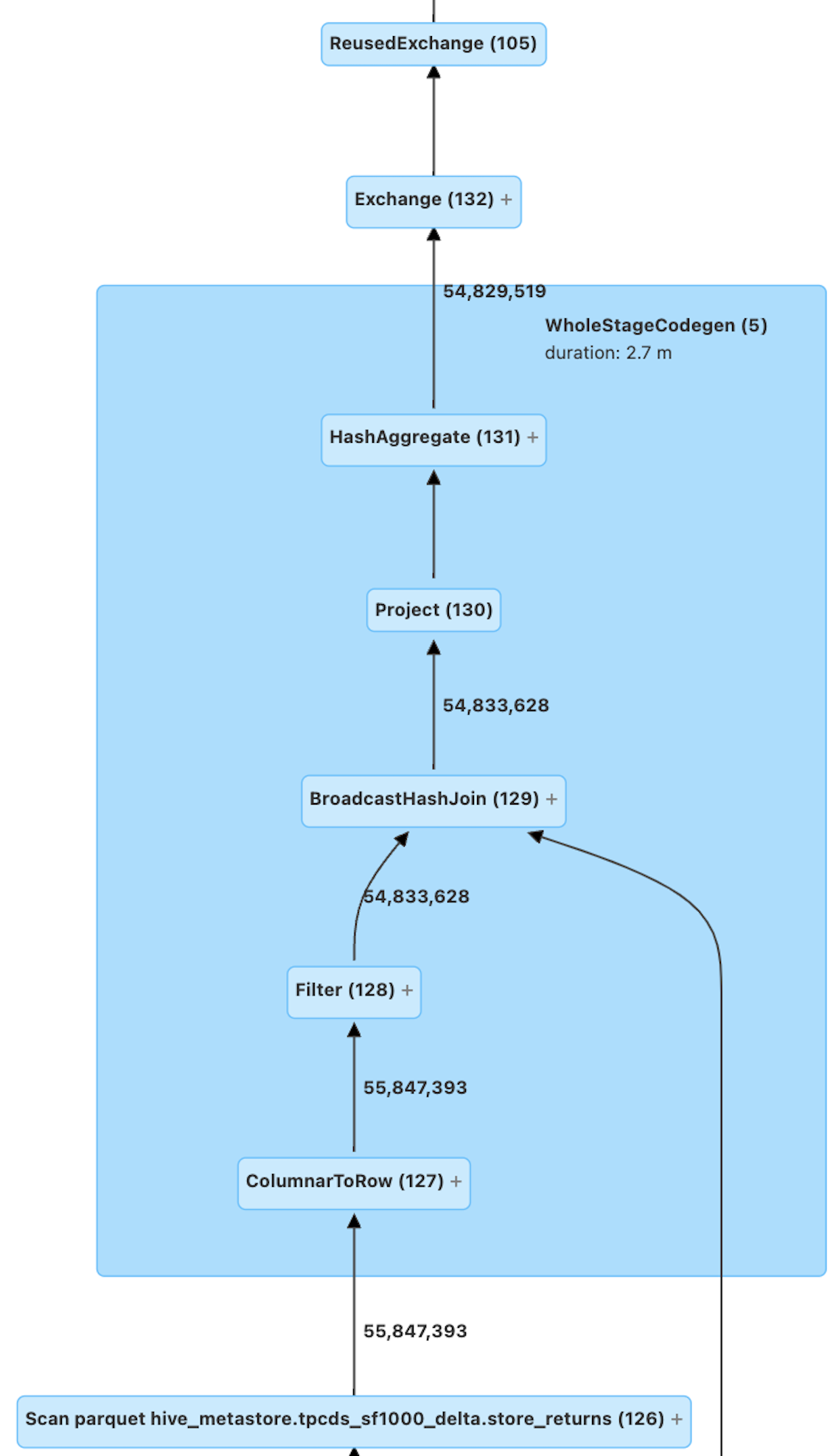
### How was this patch tested?
Unit tests were added to `ExplainSuite`. And manually tested with
ExplainSuite.
Closes #40385 from StevenChenDatabricks/fix-reused.
Authored-by: Steven Chen <[email protected]>
Signed-off-by: Wenchen Fan <[email protected]>
---
.../apache/spark/sql/execution/ExplainUtils.scala | 81 ++++++++--
.../scala/org/apache/spark/sql/ExplainSuite.scala | 165 +++++++++++++++++++++
2 files changed, 237 insertions(+), 9 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
index 12ffbc8554e..3da3e646f36 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/execution/ExplainUtils.scala
@@ -17,12 +17,17 @@
package org.apache.spark.sql.execution
+import java.util.Collections.newSetFromMap
+import java.util.IdentityHashMap
+import java.util.Set
+
import scala.collection.mutable.{ArrayBuffer, BitSet}
import org.apache.spark.sql.AnalysisException
import org.apache.spark.sql.catalyst.expressions.{Expression, PlanExpression}
import org.apache.spark.sql.catalyst.plans.QueryPlan
import org.apache.spark.sql.execution.adaptive.{AdaptiveSparkPlanExec,
AdaptiveSparkPlanHelper, QueryStageExec}
+import org.apache.spark.sql.execution.exchange.{Exchange, ReusedExchangeExec}
object ExplainUtils extends AdaptiveSparkPlanHelper {
/**
@@ -73,14 +78,34 @@ object ExplainUtils extends AdaptiveSparkPlanHelper {
*/
def processPlan[T <: QueryPlan[T]](plan: T, append: String => Unit): Unit = {
try {
+ // Initialize a reference-unique set of Operators to avoid accdiental
overwrites and to allow
+ // intentional overwriting of IDs generated in previous AQE iteration
+ val operators = newSetFromMap[QueryPlan[_]](new IdentityHashMap())
+ // Initialize an array of ReusedExchanges to help find Adaptively
Optimized Out
+ // Exchanges as part of SPARK-42753
+ val reusedExchanges = ArrayBuffer.empty[ReusedExchangeExec]
+
var currentOperatorID = 0
- currentOperatorID = generateOperatorIDs(plan, currentOperatorID)
+ currentOperatorID = generateOperatorIDs(plan, currentOperatorID,
operators, reusedExchanges,
+ true)
val subqueries = ArrayBuffer.empty[(SparkPlan, Expression,
BaseSubqueryExec)]
getSubqueries(plan, subqueries)
- subqueries.foldLeft(currentOperatorID) {
- (curId, plan) => generateOperatorIDs(plan._3.child, curId)
+ currentOperatorID = subqueries.foldLeft(currentOperatorID) {
+ (curId, plan) => generateOperatorIDs(plan._3.child, curId, operators,
reusedExchanges,
+ true)
+ }
+
+ // SPARK-42753: Process subtree for a ReusedExchange with unknown child
+ val optimizedOutExchanges = ArrayBuffer.empty[Exchange]
+ reusedExchanges.foreach{ reused =>
+ val child = reused.child
+ if (!operators.contains(child)) {
+ optimizedOutExchanges.append(child)
+ currentOperatorID = generateOperatorIDs(child, currentOperatorID,
operators,
+ reusedExchanges, false)
+ }
}
val collectedOperators = BitSet.empty
@@ -103,6 +128,17 @@ object ExplainUtils extends AdaptiveSparkPlanHelper {
}
append("\n")
}
+
+ i = 0
+ optimizedOutExchanges.foreach{ exchange =>
+ if (i == 0) {
+ append("\n===== Adaptively Optimized Out Exchanges =====\n\n")
+ }
+ i = i + 1
+ append(s"Subplan:$i\n")
+ processPlanSkippingSubqueries[SparkPlan](exchange, append,
collectedOperators)
+ append("\n")
+ }
} finally {
removeTags(plan)
}
@@ -119,17 +155,40 @@ object ExplainUtils extends AdaptiveSparkPlanHelper {
* @param plan Input query plan to process
* @param startOperatorID The start value of operation id. The subsequent
operations will be
* assigned higher value.
+ * @param visited A unique set of operators visited by generateOperatorIds.
The set is scoped
+ * at the callsite function processPlan. It serves two
purpose: Firstly, it is
+ * used to avoid accidentally overwriting existing IDs that
were generated in
+ * the same processPlan call. Secondly, it is used to allow
for intentional ID
+ * overwriting as part of SPARK-42753 where an Adaptively
Optimized Out Exchange
+ * and its subtree may contain IDs that were generated in a
previous AQE
+ * iteration's processPlan call which would result in
incorrect IDs.
+ * @param reusedExchanges A unique set of ReusedExchange nodes visited which
will be used to
+ * idenitfy adaptively optimized out exchanges in
SPARK-42753.
+ * @param addReusedExchanges Whether to add ReusedExchange nodes to
reusedExchanges set. We set it
+ * to false to avoid processing more nested
ReusedExchanges nodes in the
+ * subtree of an Adpatively Optimized Out Exchange.
* @return The last generated operation id for this input plan. This is to
ensure we always
* assign incrementing unique id to each operator.
*/
- private def generateOperatorIDs(plan: QueryPlan[_], startOperatorID: Int):
Int = {
+ private def generateOperatorIDs(
+ plan: QueryPlan[_],
+ startOperatorID: Int,
+ visited: Set[QueryPlan[_]],
+ reusedExchanges: ArrayBuffer[ReusedExchangeExec],
+ addReusedExchanges: Boolean): Int = {
var currentOperationID = startOperatorID
// Skip the subqueries as they are not printed as part of main query block.
if (plan.isInstanceOf[BaseSubqueryExec]) {
return currentOperationID
}
- def setOpId(plan: QueryPlan[_]): Unit = if
(plan.getTagValue(QueryPlan.OP_ID_TAG).isEmpty) {
+ def setOpId(plan: QueryPlan[_]): Unit = if (!visited.contains(plan)) {
+ plan match {
+ case r: ReusedExchangeExec if addReusedExchanges =>
+ reusedExchanges.append(r)
+ case _ =>
+ }
+ visited.add(plan)
currentOperationID += 1
plan.setTagValue(QueryPlan.OP_ID_TAG, currentOperationID)
}
@@ -138,18 +197,22 @@ object ExplainUtils extends AdaptiveSparkPlanHelper {
case _: WholeStageCodegenExec =>
case _: InputAdapter =>
case p: AdaptiveSparkPlanExec =>
- currentOperationID = generateOperatorIDs(p.executedPlan,
currentOperationID)
+ currentOperationID = generateOperatorIDs(p.executedPlan,
currentOperationID, visited,
+ reusedExchanges, addReusedExchanges)
if (!p.executedPlan.fastEquals(p.initialPlan)) {
- currentOperationID = generateOperatorIDs(p.initialPlan,
currentOperationID)
+ currentOperationID = generateOperatorIDs(p.initialPlan,
currentOperationID, visited,
+ reusedExchanges, addReusedExchanges)
}
setOpId(p)
case p: QueryStageExec =>
- currentOperationID = generateOperatorIDs(p.plan, currentOperationID)
+ currentOperationID = generateOperatorIDs(p.plan, currentOperationID,
visited,
+ reusedExchanges, addReusedExchanges)
setOpId(p)
case other: QueryPlan[_] =>
setOpId(other)
currentOperationID = other.innerChildren.foldLeft(currentOperationID) {
- (curId, plan) => generateOperatorIDs(plan, curId)
+ (curId, plan) => generateOperatorIDs(plan, curId, visited,
reusedExchanges,
+ addReusedExchanges)
}
}
currentOperationID
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
index a6b295578d6..3ed989c4035 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
@@ -17,9 +17,13 @@
package org.apache.spark.sql
+import org.apache.spark.sql.catalyst.plans.Inner
+import org.apache.spark.sql.catalyst.plans.physical.RoundRobinPartitioning
import org.apache.spark.sql.execution._
import org.apache.spark.sql.execution.adaptive.{DisableAdaptiveExecutionSuite,
EnableAdaptiveExecutionSuite}
import org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand
+import org.apache.spark.sql.execution.exchange.{ReusedExchangeExec,
ShuffleExchangeExec}
+import org.apache.spark.sql.execution.joins.SortMergeJoinExec
import org.apache.spark.sql.functions._
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.sources.TestOptionsSource
@@ -771,6 +775,167 @@ class ExplainSuiteAE extends ExplainSuiteHelper with
EnableAdaptiveExecutionSuit
FormattedMode,
statistics)
}
+
+ test("SPARK-42753: Process subtree for ReusedExchange with unknown child") {
+ // Simulate a simplified subtree with a ReusedExchange pointing to an
Exchange node that has
+ // no ID. This is a rare edge case that could arise during AQE if there
are multiple
+ // ReusedExchanges. We check to make sure the child Exchange gets an ID
and gets printed
+ val exchange = ShuffleExchangeExec(RoundRobinPartitioning(10),
+ RangeExec(org.apache.spark.sql.catalyst.plans.logical.Range(0, 1000, 1,
10)))
+ val reused = ReusedExchangeExec(exchange.output, exchange)
+ var results = ""
+ def appendStr(str: String): Unit = {
+ results = results + str
+ }
+ ExplainUtils.processPlan[SparkPlan](reused, appendStr(_))
+
+ val expectedTree = """|ReusedExchange (1)
+ |
+ |
+ |(1) ReusedExchange [Reuses operator id: 3]
+ |Output [1]: [id#xL]
+ |
+ |===== Adaptively Optimized Out Exchanges =====
+ |
+ |Subplan:1
+ |Exchange (3)
+ |+- Range (2)
+ |
+ |
+ |(2) Range
+ |Output [1]: [id#xL]
+ |Arguments: Range (0, 1000, step=1, splits=Some(10))
+ |
+ |(3) Exchange
+ |Input [1]: [id#xL]
+ |Arguments: RoundRobinPartitioning(10),
ENSURE_REQUIREMENTS, [plan_id=x]
+ |
+ |""".stripMargin
+
+ results = results.replaceAll("#\\d+", "#x").replaceAll("plan_id=\\d+",
"plan_id=x")
+ assert(results == expectedTree)
+ }
+
+ test("SPARK-42753: Two ReusedExchange Sharing Same Subtree") {
+ // Simulate a simplified subtree with a two ReusedExchange reusing the
same exchange
+ // Only one exchange node should be printed
+ val exchange = ShuffleExchangeExec(RoundRobinPartitioning(10),
+ RangeExec(org.apache.spark.sql.catalyst.plans.logical.Range(0, 1000, 1,
10)))
+ val reused1 = ReusedExchangeExec(exchange.output, exchange)
+ val reused2 = ReusedExchangeExec(exchange.output, exchange)
+ val join = SortMergeJoinExec(reused1.output, reused2.output, Inner, None,
reused1, reused2)
+
+ var results = ""
+ def appendStr(str: String): Unit = {
+ results = results + str
+ }
+
+ ExplainUtils.processPlan[SparkPlan](join, appendStr(_))
+
+ val expectedTree = """|SortMergeJoin Inner (3)
+ |:- ReusedExchange (1)
+ |+- ReusedExchange (2)
+ |
+ |
+ |(1) ReusedExchange [Reuses operator id: 5]
+ |Output [1]: [id#xL]
+ |
+ |(2) ReusedExchange [Reuses operator id: 5]
+ |Output [1]: [id#xL]
+ |
+ |(3) SortMergeJoin
+ |Left keys [1]: [id#xL]
+ |Right keys [1]: [id#xL]
+ |Join type: Inner
+ |Join condition: None
+ |
+ |===== Adaptively Optimized Out Exchanges =====
+ |
+ |Subplan:1
+ |Exchange (5)
+ |+- Range (4)
+ |
+ |
+ |(4) Range
+ |Output [1]: [id#xL]
+ |Arguments: Range (0, 1000, step=1, splits=Some(10))
+ |
+ |(5) Exchange
+ |Input [1]: [id#xL]
+ |Arguments: RoundRobinPartitioning(10),
ENSURE_REQUIREMENTS, [plan_id=x]
+ |
+ |""".stripMargin
+ results = results.replaceAll("#\\d+", "#x").replaceAll("plan_id=\\d+",
"plan_id=x")
+ assert(results == expectedTree)
+ }
+
+ test("SPARK-42753: Correctly separate two ReusedExchange not sharing
subtree") {
+ // Simulate two ReusedExchanges reusing two different Exchanges that
appear similar
+ // The two exchanges should have separate IDs and printed separately
+ val exchange1 = ShuffleExchangeExec(RoundRobinPartitioning(10),
+ RangeExec(org.apache.spark.sql.catalyst.plans.logical.Range(0, 1000, 1,
10)))
+ val reused1 = ReusedExchangeExec(exchange1.output, exchange1)
+ val exchange2 = ShuffleExchangeExec(RoundRobinPartitioning(10),
+ RangeExec(org.apache.spark.sql.catalyst.plans.logical.Range(0, 1000, 1,
10)))
+ val reused2 = ReusedExchangeExec(exchange2.output, exchange2)
+ val join = SortMergeJoinExec(reused1.output, reused2.output, Inner, None,
reused1, reused2)
+
+ var results = ""
+ def appendStr(str: String): Unit = {
+ results = results + str
+ }
+
+ ExplainUtils.processPlan[SparkPlan](join, appendStr(_))
+
+ val expectedTree = """|SortMergeJoin Inner (3)
+ |:- ReusedExchange (1)
+ |+- ReusedExchange (2)
+ |
+ |
+ |(1) ReusedExchange [Reuses operator id: 5]
+ |Output [1]: [id#xL]
+ |
+ |(2) ReusedExchange [Reuses operator id: 7]
+ |Output [1]: [id#xL]
+ |
+ |(3) SortMergeJoin
+ |Left keys [1]: [id#xL]
+ |Right keys [1]: [id#xL]
+ |Join type: Inner
+ |Join condition: None
+ |
+ |===== Adaptively Optimized Out Exchanges =====
+ |
+ |Subplan:1
+ |Exchange (5)
+ |+- Range (4)
+ |
+ |
+ |(4) Range
+ |Output [1]: [id#xL]
+ |Arguments: Range (0, 1000, step=1, splits=Some(10))
+ |
+ |(5) Exchange
+ |Input [1]: [id#xL]
+ |Arguments: RoundRobinPartitioning(10),
ENSURE_REQUIREMENTS, [plan_id=x]
+ |
+ |Subplan:2
+ |Exchange (7)
+ |+- Range (6)
+ |
+ |
+ |(6) Range
+ |Output [1]: [id#xL]
+ |Arguments: Range (0, 1000, step=1, splits=Some(10))
+ |
+ |(7) Exchange
+ |Input [1]: [id#xL]
+ |Arguments: RoundRobinPartitioning(10),
ENSURE_REQUIREMENTS, [plan_id=x]
+ |
+ |""".stripMargin
+ results = results.replaceAll("#\\d+", "#x").replaceAll("plan_id=\\d+",
"plan_id=x")
+ assert(results == expectedTree)
+ }
}
case class ExplainSingleData(id: Int)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}