Orion34C opened a new pull request #4546: support cuda tensorcore subbyte int data type in auto tensorcore URL: https://github.com/apache/incubator-tvm/pull/4546 In our former RFC [Auto TensorCore CodeGen](https://github.com/apache/incubator-tvm/issues/4105),we have present the performance of fp16/int8 gemm based on auto tensor-core implementation. However, cuda's wmma instructions support more data types in the [experimental namespace](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#wmma-subbyte) since cuda10, which can be useful when combining with low bit quantizations. Several hacks still remain in the code which needs to discussion with you guys, because we have not found an elegant solution to deal with newly added data type int4/int1 in the arg bind pass. In our implementation, we store 8 int4/uint4 data or 32 int1 data into one int32,because int4/int1 is not a basic data type in cuda c or even numpy. We implement support for int4/int1 tensor-core codegen based on auto tensor-core pass and provide an example on how to use it to generate gemm kernels. The command to run the sample int4/int1 gemm schedule is: python tutorials/autotvm/tensor_core_matmul_subbyte_int.py $M $N $K $dtype Supported data types are int4, int1. Only TN layout is supported for int4/int since it is the only layout supported by wmma's sub-byte fragments. # Perf on T4, CUDA10.1, Driver 418.39 The baseline data is cuBLASLt for int8 tensor-core gemm since no impls for int4/int1 were provided by cublas so far. |M, N, K| cuBLASLt int8 | TVM TensorCore int4 | TVM TensorCore int1 | |-------|---------------|----------------------|---------------------| |512, 128, 512|10.844us|7.200us|3.633us| |512, 64, 512|8.6300us|4.2560us|2.2720us| |512, 32, 512|8.3660us|2.7990us|2.0760us| |512, 16, 512|8.3750us|2.0330us|1.5590us| |256, 256, 256|8.0650us|4.2030us|2.5690us| |1024, 32, 512|8.3460us|4.255us|2.3370us| |2048, 32, 512|8.4680us|5.956us|3.6890us| 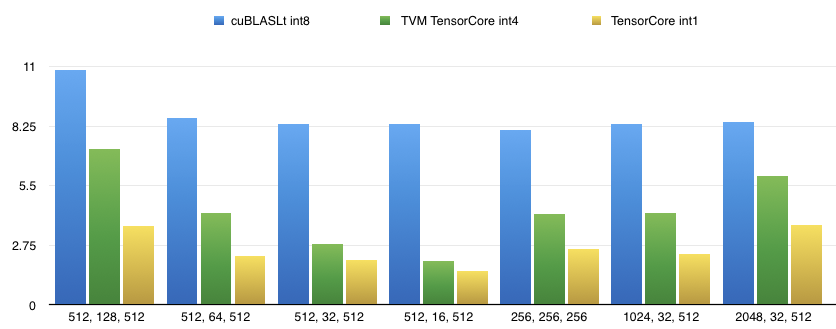 The performance tuning is still on-going. Thanks! -- Lanbo Li, Minmin Sun, Chenfan Jia and Jun Yang of Alibaba PAI team
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services