This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-tvm-site.git
The following commit(s) were added to refs/heads/master by this push:
new a56360b Migrate everything to https
a56360b is described below
commit a56360b632e51873660d9554622ca8ed0754b434
Author: tqchen <[email protected]>
AuthorDate: Mon Mar 30 15:45:36 2020 -0700
Migrate everything to https
---
_config.yml | 2 +-
_posts/2018-07-12-vta-release-announcement.markdown | 10 +++++-----
_posts/2019-03-18-tvm-apache-announcement.md | 2 +-
scripts/task_deploy_asf_site.sh | 8 +++++---
scripts/task_docs_update.sh | 1 -
vta.md | 4 ++--
6 files changed, 14 insertions(+), 13 deletions(-)
diff --git a/_config.yml b/_config.yml
index 6862049..38adc71 100644
--- a/_config.yml
+++ b/_config.yml
@@ -1,5 +1,5 @@
# This is the default format.
-# For more see: http://jekyllrb.com/docs/permalinks/
+# For more see: https://jekyllrb.com/docs/permalinks/
permalink: /:categories/:year/:month/:day/:title
exclude: [".rvmrc",
diff --git a/_posts/2018-07-12-vta-release-announcement.markdown
b/_posts/2018-07-12-vta-release-announcement.markdown
index 107cf10..440d484 100644
--- a/_posts/2018-07-12-vta-release-announcement.markdown
+++ b/_posts/2018-07-12-vta-release-announcement.markdown
@@ -21,7 +21,7 @@ We are excited to announce the launch of the Versatile Tensor
Accelerator (VTA,
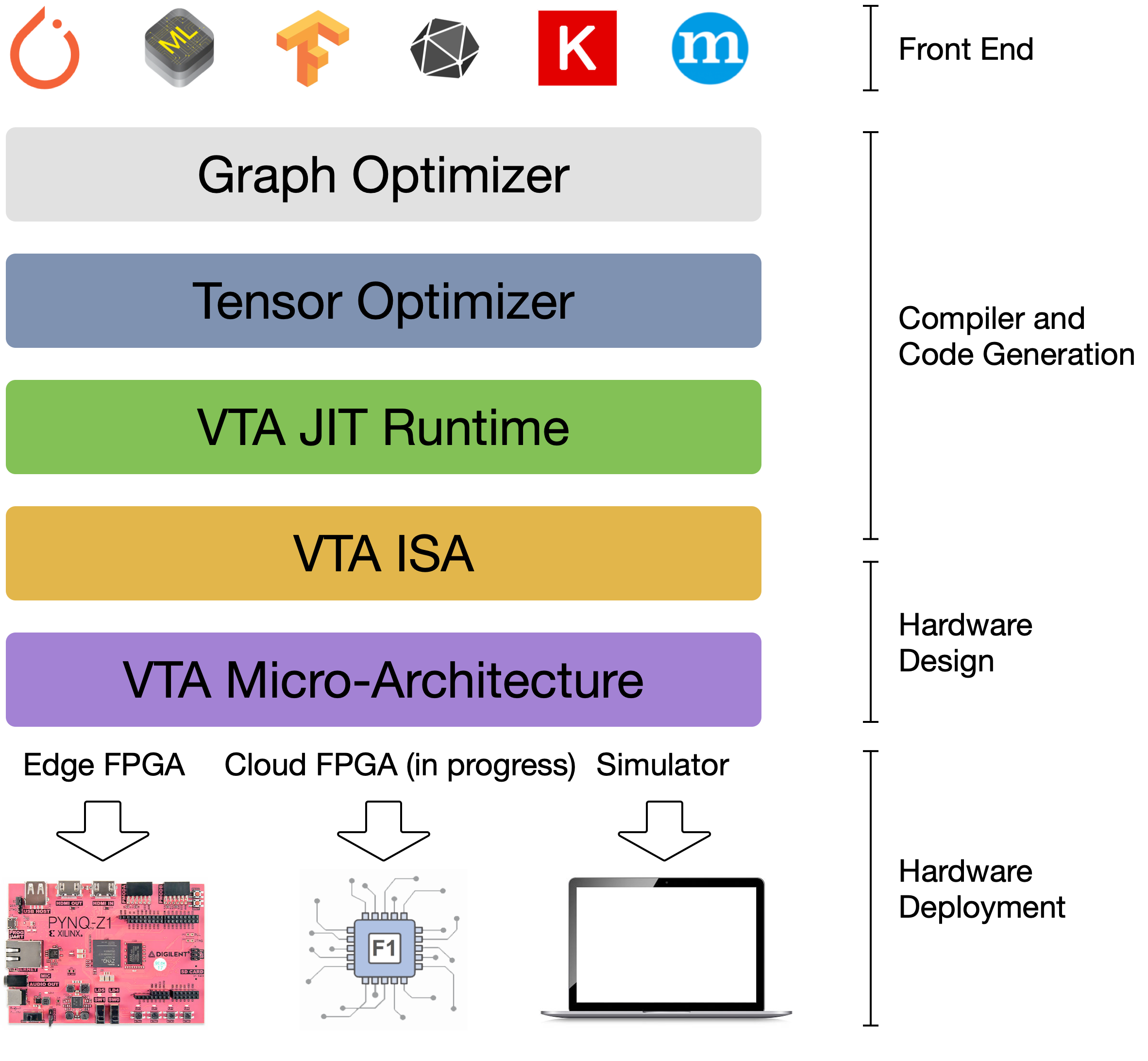
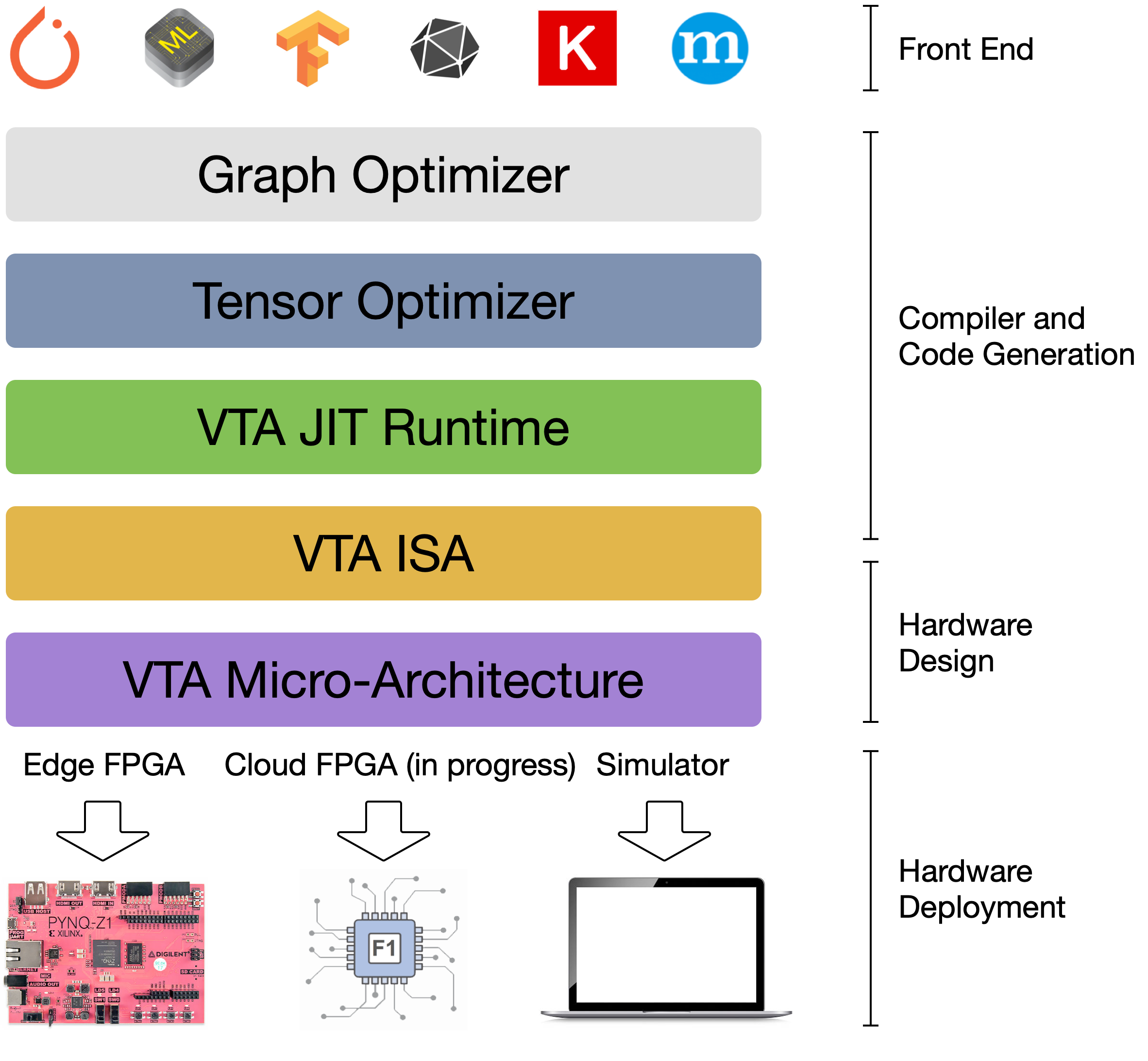
VTA is more than a standalone accelerator design: it’s an end-to-end solution
that includes drivers, a JIT runtime, and an optimizing compiler stack based on
TVM. The current release includes a behavioral hardware simulator, as well as
the infrastructure to deploy VTA on low-cost FPGA hardware for fast
prototyping. By extending the TVM stack with a customizable, and open source
deep learning hardware accelerator design, we are exposing a transparent
end-to-end deep learning stack from th [...]
{:center}
-{:
width="50%"}
+{:
width="50%"}
{:center}
The VTA and TVM stack together constitute a blueprint for end-to-end,
accelerator-centric deep learning system that can:
@@ -76,7 +76,7 @@ The Vanilla Tensor Accelerator (VTA) is a generic deep
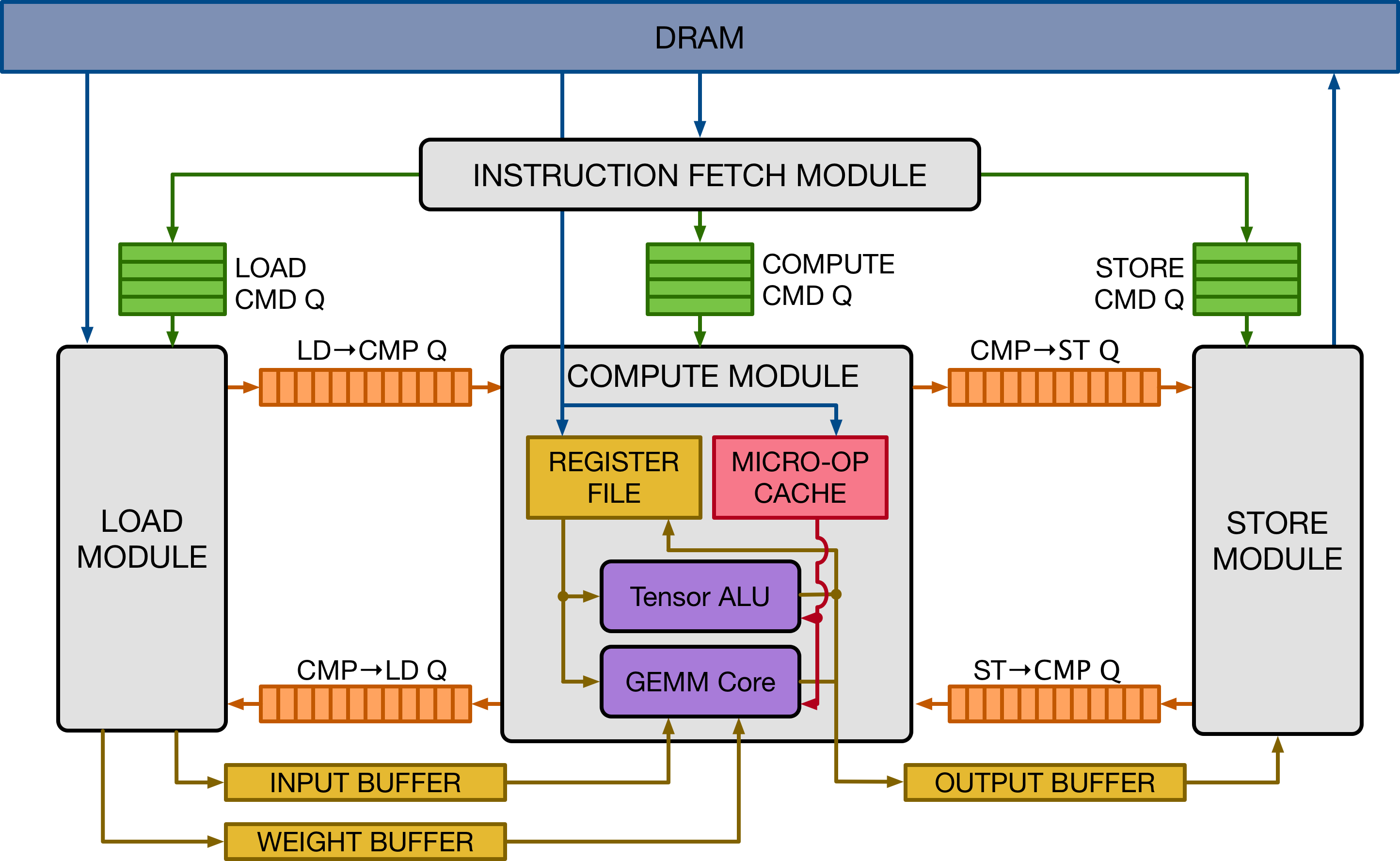
learning accelerator buil
The design is inspired by mainstream deep learning accelerators, of the likes
of Google's TPU accelerator. The design adopts decoupled access-execute to hide
memory access latency and maximize utilization of compute resources. To a
broader extent, VTA can serve as a template deep learning accelerator design,
exposing a clean tensor computation abstraction to the compiler stack.
{:center}
-{:
width="60%"}
+{:
width="60%"}
{:center}
The figure above presents a high-level overview of the VTA hardware
organization. VTA is composed of four modules that communicate between each
other via FIFO queues and single-writer/single-reader SRAM memory blocks, to
allow for task-level pipeline parallelism.
@@ -95,7 +95,7 @@ This simulator back-end is readily available for developers
to experiment with.
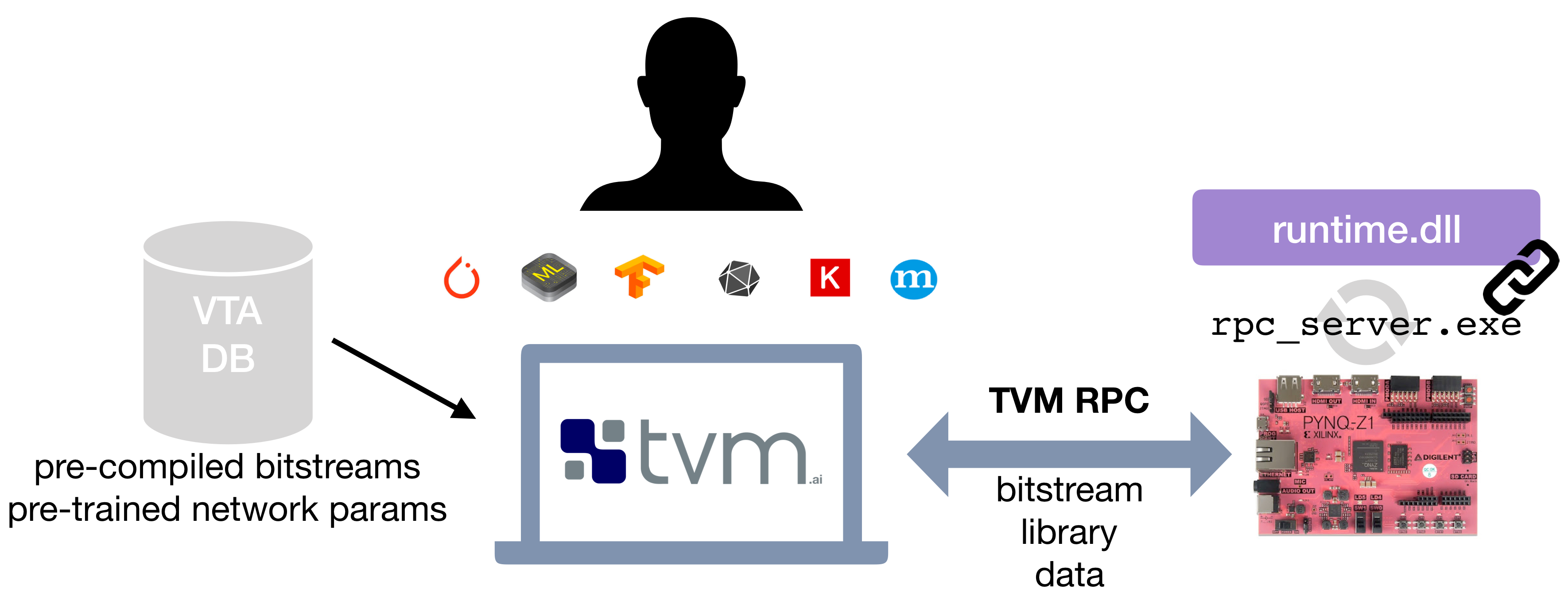
The second approach relies on an off-the-shelf and low-cost FPGA development
board -- the [Pynq board](http://www.pynq.io/), which exposes a reconfigurable
FPGA fabric and an ARM SoC.
{:center}
-{:
width="70%"}
+{:
width="70%"}
{:center}
The VTA release offers a simple compilation and deployment flow of the VTA
hardware design and TVM workloads on the Pynq platform, with the help of an RPC
server interface.
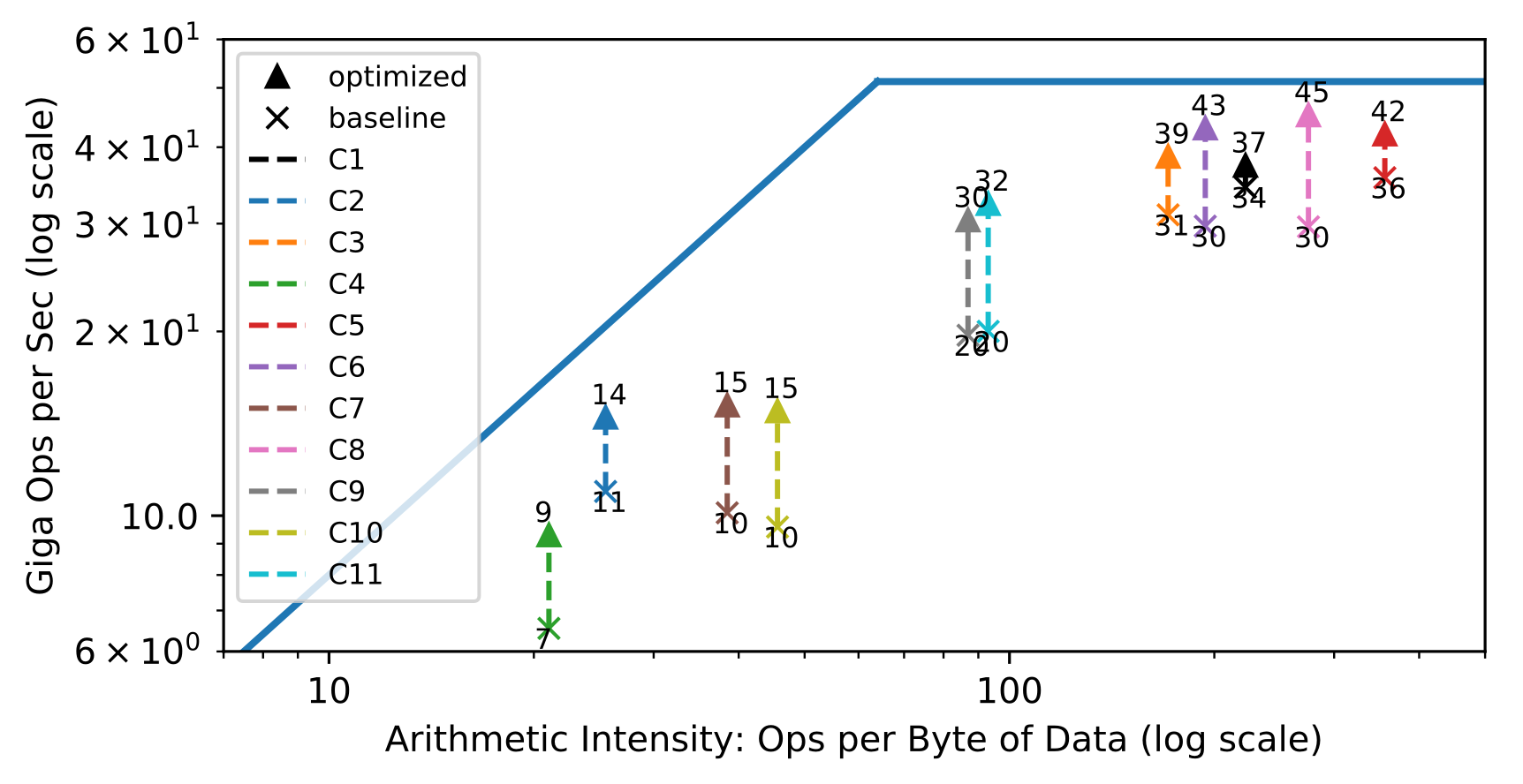
@@ -120,7 +120,7 @@ A popular method used to assess the efficient use of
hardware are roofline diagr
In the left half, convolution layers are bandwidth limited, whereas on the
right half, they are compute limited.
{:center}
-{:
width="60%"}
+{:
width="60%"}
{:center}
The goal behind designing a hardware architecture, and a compiler stack is to
bring each workload as close as possible to the roofline of the target hardware.
@@ -131,7 +131,7 @@ The result is an overall higher utilization of the
available compute and memory
### End to end ResNet-18 evaluation
{:center}
-{:
width="60%"}
+{:
width="60%"}
{:center}
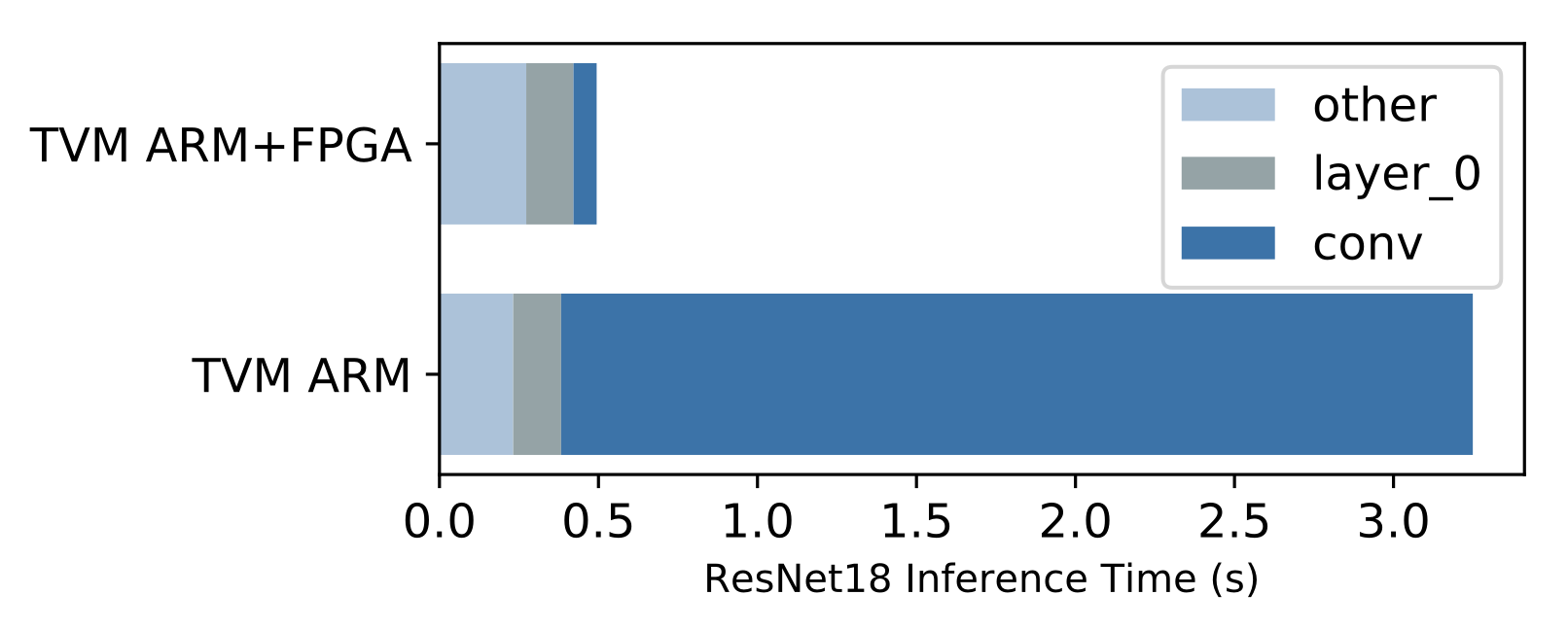
A benefit of having a complete compiler stack built for VTA is the ability to
run end-to-end workloads. This is compelling in the context of hardware
acceleration because we need to understand what performance bottlenecks, and
Amdahl limitations stand in the way to obtaining faster performance.
diff --git a/_posts/2019-03-18-tvm-apache-announcement.md
b/_posts/2019-03-18-tvm-apache-announcement.md
index 6fe0f60..5d63789 100644
--- a/_posts/2019-03-18-tvm-apache-announcement.md
+++ b/_posts/2019-03-18-tvm-apache-announcement.md
@@ -12,7 +12,7 @@ TVM is an open source deep learning compiler stack that
closes the gap between t
{: width="70%"}
{:center}
-TVM stack began as a research project at the [SAMPL
group](https://sampl.cs.washington.edu/) of Paul G. Allen School of Computer
Science & Engineering, University of Washington. The project uses the
loop-level IR and several optimizations from the [Halide
project](http://halide-lang.org/), in addition to [a full deep learning
compiler stack](https://tvm.ai/about) to support machine learning workloads for
diverse hardware backends.
+TVM stack began as a research project at the [SAMPL
group](https://sampl.cs.washington.edu/) of Paul G. Allen School of Computer
Science & Engineering, University of Washington. The project uses the
loop-level IR and several optimizations from the [Halide
project](http://halide-lang.org/), in addition to [a full deep learning
compiler stack](https://tvm.apache.org/about) to support machine learning
workloads for diverse hardware backends.
Since its introduction, the project was driven by an open source community
involving multiple industry and academic institutions. Currently, the TVM stack
includes a high-level differentiable programming IR for high-level
optimization, a machine learning driven program optimizer and VTA -- a fully
open sourced deep learning accelerator. The community brings innovations from
machine learning, compiler systems, programming languages, and computer
architecture to build a full-stack open sou [...]
diff --git a/scripts/task_deploy_asf_site.sh b/scripts/task_deploy_asf_site.sh
index 90f8180..20b48c9 100755
--- a/scripts/task_deploy_asf_site.sh
+++ b/scripts/task_deploy_asf_site.sh
@@ -6,13 +6,15 @@ set -u
echo "Start to generate and deploy site ..."
jekyll b
cp .gitignore .gitignore.bak
-git checkout asf-site
+
+# copy new files into the current site
+git fetch
+git checkout -B asf-site origin/asf-site
# remove all existing files, excluding the docs
git ls-files | grep -v ^docs| xargs rm -f
-
-# copy new files into the current site
cp .gitignore.bak .gitignore
+
cp -rf _site/* .
DATE=`date`
git add --all && git commit -am "Build at ${DATE}"
diff --git a/scripts/task_docs_update.sh b/scripts/task_docs_update.sh
index fcce5f5..bef6c6b 100755
--- a/scripts/task_docs_update.sh
+++ b/scripts/task_docs_update.sh
@@ -17,7 +17,6 @@ if [ ! -f "$DOCS_TGZ" ]; then
echo "$DOCS_TGZ does not exist!!"
exit 255
fi
-
cp .gitignore .gitignore.bak
git fetch
git checkout -B asf-site origin/asf-site
diff --git a/vta.md b/vta.md
index 29994b6..dfd02e5 100644
--- a/vta.md
+++ b/vta.md
@@ -18,7 +18,7 @@ By extending the TVM stack with a customizable, and open
source deep learning ha
This forms a truly end-to-end, from software-to-hardware open source stack for
deep learning systems.
{:center: style="text-align: center"}
-{:
width="50%"}
+{:
width="50%"}
{:center}
The VTA and TVM stack together constitute a blueprint for end-to-end,
accelerator-centric deep learning system that can:
@@ -33,4 +33,4 @@ TVM is now an effort undergoing incubation at The Apache
Software Foundation (AS
driven by an open source community involving multiple industry and academic
institutions
under the Apache way.
-Read more about VTA in the [TVM blog
post](https://tvm.ai/2018/07/12/vta-release-announcement.html), or in the [VTA
techreport](https://arxiv.org/abs/1807.04188).
+Read more about VTA in the [TVM blog
post](https://tvm.apache.org/2018/07/12/vta-release-announcement.html), or in
the [VTA techreport](https://arxiv.org/abs/1807.04188).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}