This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new 1435ddb118 [Doc] Relax Deep Dive (#17380)
1435ddb118 is described below
commit 1435ddb118ce4fc6b87c07804e554c2e945053c9
Author: Siyuan Feng <[email protected]>
AuthorDate: Tue Sep 17 22:06:38 2024 +0800
[Doc] Relax Deep Dive (#17380)
* [Doc] Relax Deep Dive
Similar as TensorIR Deep Dive, we also have Relax Deep Dive.
---
docs/conf.py | 7 +-
docs/deep_dive/relax/abstraction.rst | 73 ++++++
docs/deep_dive/{tensor_ir => relax}/index.rst | 17 +-
docs/deep_dive/relax/learning.rst | 272 ++++++++++++++++++++
docs/deep_dive/relax/tutorials/README.txt | 2 +
docs/deep_dive/relax/tutorials/relax_creation.py | 281 +++++++++++++++++++++
.../relax/tutorials/relax_transformation.py | 141 +++++++++++
docs/deep_dive/tensor_ir/abstraction.rst | 1 -
docs/deep_dive/tensor_ir/index.rst | 6 +-
.../tutorials/{creation.py => tir_creation.py} | 0
.../{transformation.py => tir_transformation.py} | 0
docs/index.rst | 1 +
12 files changed, 787 insertions(+), 14 deletions(-)
diff --git a/docs/conf.py b/docs/conf.py
index 12039ebb2c..acc03161e5 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -424,6 +424,7 @@ examples_dirs = [
# New tutorial structure under docs folder
tvm_path.joinpath("docs", "get_started", "tutorials"),
tvm_path.joinpath("docs", "how_to", "tutorials"),
+ tvm_path.joinpath("docs", "deep_dive", "relax", "tutorials"),
tvm_path.joinpath("docs", "deep_dive", "tensor_ir", "tutorials"),
]
@@ -443,6 +444,7 @@ gallery_dirs = [
# New tutorial structure under docs folder
"get_started/tutorials/",
"how_to/tutorials/",
+ "deep_dive/relax/tutorials/",
"deep_dive/tensor_ir/tutorials/",
]
@@ -598,10 +600,10 @@ tvm_alias_check_map = {
## Setup header and other configs
import tlcpack_sphinx_addon
-footer_copyright = "© 2023 Apache Software Foundation | All rights reserved"
+footer_copyright = "© 2024 Apache Software Foundation | All rights reserved"
footer_note = " ".join(
"""
-Copyright © 2023 The Apache Software Foundation. Apache TVM, Apache, the
Apache feather,
+Copyright © 2024 The Apache Software Foundation. Apache TVM, Apache, the
Apache feather,
and the Apache TVM project logo are either trademarks or registered trademarks
of
the Apache Software Foundation.""".split(
"\n"
@@ -614,7 +616,6 @@ header_logo_link = "https://tvm.apache.org/";
header_links = [
("Community", "https://tvm.apache.org/community";),
("Download", "https://tvm.apache.org/download";),
- ("VTA", "https://tvm.apache.org/vta";),
("Blog", "https://tvm.apache.org/blog";),
("Docs", "https://tvm.apache.org/docs";),
("Conference", "https://tvmconf.org";),
diff --git a/docs/deep_dive/relax/abstraction.rst
b/docs/deep_dive/relax/abstraction.rst
new file mode 100644
index 0000000000..2b9ee8b5d7
--- /dev/null
+++ b/docs/deep_dive/relax/abstraction.rst
@@ -0,0 +1,73 @@
+.. Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+.. http://www.apache.org/licenses/LICENSE-2.0
+
+.. Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+.. _relax-abstraction:
+
+Graph Abstraction for ML Models
+-------------------------------
+Graph abstraction is a key technique used in machine learning (ML) compilers
+to represent and reason about the structure and data flow of ML models. By
+abstracting the model into a graph representation, the compiler can perform
+various optimizations to improve performance and efficiency. This tutorial will
+cover the basics of graph abstraction, its key elements of Relax IR, and how
it enables optimization in ML compilers.
+
+What is Graph Abstraction?
+~~~~~~~~~~~~~~~~~~~~~~~~~~
+Graph abstraction is the process of representing an ML model as a directed
graph,
+where the nodes represent computational operations (e.g., matrix
multiplication,
+convolution) and the edges represent the flow of data between these operations.
+This abstraction allows the compiler to analyze the dependencies and
+relationships between different parts of the model.
+
+.. code:: python
+
+ from tvm.script import relax as R
+
+ @R.function
+ def main(
+ x: R.Tensor((1, 784), dtype="float32"),
+ weight: R.Tensor((784, 256), dtype="float32"),
+ bias: R.Tensor((256,), dtype="float32"),
+ ) -> R.Tensor((1, 256), dtype="float32"):
+ with R.dataflow():
+ lv0 = R.matmul(x, weight)
+ lv1 = R.add(lv0, bias)
+ gv = R.nn.relu(lv1)
+ R.output(gv)
+ return gv
+
+Key Features of Relax
+~~~~~~~~~~~~~~~~~~~~~
+Relax, the graph representation utilized in Apache TVM's Unity strategy,
+facilitates end-to-end optimization of ML models through several crucial
+features:
+
+- **First-class symbolic shape**: Relax employs symbolic shapes to represent
+ tensor dimensions, enabling global tracking of dynamic shape relationships
+ across tensor operators and function calls.
+
+- **Multi-level abstractions**: Relax supports cross-level abstractions, from
+ high-level neural network layers to low-level tensor operations, enabling
+ optimizations that span different hierarchies within the model.
+
+- **Composable transformations**: Relax offers a framework for composable
+ transformations that can be selectively applied to different model
components.
+ This includes capabilities such as partial lowering and partial
specialization,
+ providing flexible customization and optimization options.
+
+These features collectively empower Relax to offer a powerful and adaptable
approach
+to ML model optimization within the Apache TVM ecosystem.
diff --git a/docs/deep_dive/tensor_ir/index.rst b/docs/deep_dive/relax/index.rst
similarity index 68%
copy from docs/deep_dive/tensor_ir/index.rst
copy to docs/deep_dive/relax/index.rst
index 432d47116a..f891eb2793 100644
--- a/docs/deep_dive/tensor_ir/index.rst
+++ b/docs/deep_dive/relax/index.rst
@@ -15,17 +15,20 @@
specific language governing permissions and limitations
under the License.
-.. _tensor-ir:
+.. _relax:
+
+Relax
+=====
+Relax is a high-level abstraction for graph optimization and transformation in
Apache TVM stack.
+Additionally, Apache TVM combine Relax and TensorIR together as a unity
strategy for cross-level
+optimization. Hence, Relax is usually working closely with TensorIR for
representing and optimizing
+the whole IRModule
-TensorIR
-========
-TensorIR is one of the core abstraction in Apache TVM Unity stack, which is
used to
-represent and optimize the primitive tensor functions.
.. toctree::
:maxdepth: 2
abstraction
learning
- tutorials/creation
- tutorials/transformation
+ tutorials/relax_creation
+ tutorials/relax_transformation
diff --git a/docs/deep_dive/relax/learning.rst
b/docs/deep_dive/relax/learning.rst
new file mode 100644
index 0000000000..702b0e0a9f
--- /dev/null
+++ b/docs/deep_dive/relax/learning.rst
@@ -0,0 +1,272 @@
+.. Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+.. http://www.apache.org/licenses/LICENSE-2.0
+
+.. Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+.. _relax-learning:
+
+Understand Relax Abstraction
+============================
+Relax is a graph abstraction used in Apache TVM Unity strategy, which
+helps to end-to-end optimize ML models. The principal objective of Relax
+is to depict the structure and data flow of ML models, including the
+dependencies and relationships between different parts of the model, as
+well as how to execute the model on hardware.
+
+End to End Model Execution
+--------------------------
+
+In this chapter, we will use the following model as an example. This is
+a two-layer neural network that consists of two linear operations with
+relu activation.
+
+.. image:: https://mlc.ai/_images/e2e_fashionmnist_mlp_model.png
+ :width: 85%
+ :align: center
+
+
+High-Level Operations Representation
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+Let us begin by reviewing a Numpy implementation of the model.
+
+.. code:: python
+
+ def numpy_mlp(data, w0, b0, w1, b1):
+ lv0 = data @ w0 + b0
+ lv1 = np.maximum(lv0, 0)
+ lv2 = lv1 @ w1 + b1
+ return lv2
+
+The above example code shows the high-level array operations to perform the
end-to-end model
+execution. Of course, we can rewrite the above code using Relax as follows:
+
+.. code:: python
+
+ from tvm.script import relax as R
+
+ @R.function
+ def relax_mlp(
+ data: R.Tensor(("n", 784), dtype="float32"),
+ w0: R.Tensor((784, 128), dtype="float32"),
+ b0: R.Tensor((128,), dtype="float32"),
+ w1: R.Tensor((128, 10), dtype="float32"),
+ b1: R.Tensor((10,), dtype="float32"),
+ ) -> R.Tensor(("n", 10), dtype="float32"):
+ with R.dataflow():
+ lv0 = R.matmul(data, w0) + b0
+ lv1 = R.nn.relu(lv0)
+ lv2 = R.matmul(lv1, w1) + b1
+ R.output(lv2)
+ return lv2
+
+Low-Level Integration
+~~~~~~~~~~~~~~~~~~~~~
+
+However, again from the pov of machine learning compilation (MLC), we would
like to see
+through the details under the hood of these array computations.
+
+For the purpose of illustrating details under the hood, we will again write
examples in low-level numpy:
+
+We will use a loop instead of array functions when necessary to demonstrate
the possible loop computations.
+When possible, we always explicitly allocate arrays via numpy.empty and pass
them around.
+The code block below shows a low-level numpy implementation of the same model.
+
+.. code:: python
+
+ def lnumpy_linear(X: np.ndarray, W: np.ndarray, B: np.ndarray, Z:
np.ndarray):
+ n, m, K = X.shape[0], W.shape[1], X.shape[1]
+ Y = np.empty((n, m), dtype="float32")
+ for i in range(n):
+ for j in range(m):
+ for k in range(K):
+ if k == 0:
+ Y[i, j] = 0
+ Y[i, j] = Y[i, j] + X[i, k] * W[k, j]
+
+ for i in range(n):
+ for j in range(m):
+ Z[i, j] = Y[i, j] + B[j]
+
+
+ def lnumpy_relu0(X: np.ndarray, Y: np.ndarray):
+ n, m = X.shape
+ for i in range(n):
+ for j in range(m):
+ Y[i, j] = np.maximum(X[i, j], 0)
+
+ def lnumpy_mlp(data, w0, b0, w1, b1):
+ n = data.shape[0]
+ lv0 = np.empty((n, 128), dtype="float32")
+ lnumpy_matmul(data, w0, b0, lv0)
+
+ lv1 = np.empty((n, 128), dtype="float32")
+ lnumpy_relu(lv0, lv1)
+
+ out = np.empty((n, 10), dtype="float32")
+ lnumpy_matmul(lv1, w1, b1, out)
+ return out
+
+With the low-level NumPy example in mind, now we are ready to introduce an
Relax abstraction
+for the end-to-end model execution. The code block below shows a TVMScript
implementation of the model.
+
+.. code:: python
+
+ @I.ir_module
+ class Module:
+ @T.prim_func(private=True)
+ def linear(x: T.handle, w: T.handle, b: T.handle, z: T.handle):
+ M, N, K = T.int64(), T.int64(), T.int64()
+ X = T.match_buffer(x, (M, K), "float32")
+ W = T.match_buffer(w, (K, N), "float32")
+ B = T.match_buffer(b, (N,), "float32")
+ Z = T.match_buffer(z, (M, N), "float32")
+ Y = T.alloc_buffer((M, N), "float32")
+ for i, j, k in T.grid(M, N, K):
+ with T.block("Y"):
+ v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
+ with T.init():
+ Y[v_i, v_j] = T.float32(0.0)
+ Y[v_i, v_j] = Y[v_i, v_j] + X[v_i, v_k] * W[v_k, v_j]
+ for i, j in T.grid(M, N):
+ with T.block("Z"):
+ v_i, v_j = T.axis.remap("SS", [i, j])
+ Z[v_i, v_j] = Y[v_i, v_j] + B[v_j]
+
+ @T.prim_func(private=True)
+ def relu(x: T.handle, y: T.handle):
+ M, N = T.int64(), T.int64()
+ X = T.match_buffer(x, (M, N), "float32")
+ Y = T.match_buffer(y, (M, N), "float32")
+ for i, j in T.grid(M, N):
+ with T.block("Y"):
+ v_i, v_j = T.axis.remap("SS", [i, j])
+ Y[v_i, v_j] = T.max(X[v_i, v_j], T.float32(0.0))
+
+ @R.function
+ def main(
+ x: R.Tensor(("n", 784), dtype="float32"),
+ w0: R.Tensor((784, 256), dtype="float32"),
+ b0: R.Tensor((256,), dtype="float32"),
+ w1: R.Tensor((256, 10), dtype="float32"),
+ b1: R.Tensor((10,), dtype="float32")
+ ) -> R.Tensor(("n", 10), dtype="float32"):
+ cls = Module
+ n = T.int64()
+ with R.dataflow():
+ lv = R.call_tir(cls.linear, (x, w0, b0),
out_sinfo=R.Tensor((n, 256), dtype="float32"))
+ lv1 = R.call_tir(cls.relu, (lv0,), out_sinfo=R.Tensor((n,
256), dtype="float32"))
+ lv2 = R.call_tir(cls.linear, (lv1, w1, b1),
out_sinfo=R.Tensor((b, 10), dtype="float32"))
+ R.output(lv2)
+ return lv2
+
+The above code contains kinds of functions: the primitive tensor functions
(``T.prim_func``) and a
+``R.function`` (relax function). Relax function is a new type of abstraction
representing
+high-level neural network executions.
+
+Note that the above relax module natively supports symbolic shapes, see the
``"n"`` in the
+tensor shapes in ``main`` function and ``M``, ``N``, ``K`` in the ``linear``
function. This is
+a key feature of Relax abstraction, which enables the compiler to track
dynamic shape relations
+globally across tensor operators and function calls.
+
+Again it is helpful to see the TVMScript code and low-level numpy code
side-by-side and check the
+corresponding elements, and we are going to walk through each of them in
detail. Since we already
+learned about primitive tensor functions, we are going to focus on the
high-level execution part.
+
+Key Elements of Relax
+---------------------
+This section will introduce the key elements of Relax abstraction and how it
enables optimization
+in ML compilers.
+
+Structure Info
+~~~~~~~~~~~~~~
+Structure info is a new concept in Relax that represents the type of relax
expressions. It can
+be ``TensorStructInfo``, ``TupleStructInfo``, etc. In the above example, we
use ``TensorStructInfo``
+(short in ``R.Tensor`` in TVMScript) to represent the shape and dtype of the
tensor of the inputs,
+outputs, and intermediate results.
+
+R.call_tir
+~~~~~~~~~~
+The ``R.call_tir`` function is a new abstraction in Relax that allows calling
primitive tensor
+functions in the same IRModule. This is a key feature of Relax that enables
cross-level
+abstractions, from high-level neural network layers to low-level tensor
operations.
+Taking one line from the above code as an example:
+
+.. code:: python
+
+ lv = R.call_tir(cls.linear, (x, w0, b0), out_sinfo=R.Tensor((n, 256),
dtype="float32"))
+
+To explain what does ``R.call_tir`` work, let us review an equivalent
low-level numpy
+implementation of the operation, as follows:
+
+.. code:: python
+
+ lv0 = np.empty((n, 256), dtype="float32")
+ lnumpy_linear(x, w0, b0, lv0)
+
+Specifically, ``call_tir`` allocates an output tensor res, then pass the
inputs and the output
+to the prim_func. After executing prim_func the result is populated in res,
then we can return
+the result.
+
+This convention is called **destination passing**, The idea is that input and
output are explicitly
+allocated outside and passed to the low-level primitive function. This style
is commonly used
+in low-level library designs, so higher-level frameworks can handle that
memory allocation
+decision. Note that not all tensor operations can be presented in this style
(specifically,
+there are operations whose output shape depends on the input). Nevertheless,
in common practice,
+it is usually helpful to write the low-level function in this style when
possible.
+
+Dataflow Block
+~~~~~~~~~~~~~~
+Another important element in a relax function is the R.dataflow() scope
annotation.
+
+.. code:: python
+
+ with R.dataflow():
+ lv = R.call_tir(cls.linear, (x, w0, b0), out_sinfo=R.Tensor((n, 256),
dtype="float32"))
+ lv1 = R.call_tir(cls.relu, (lv0,), out_sinfo=R.Tensor((n, 256),
dtype="float32"))
+ lv2 = R.call_tir(cls.linear, (lv1, w1, b1), out_sinfo=R.Tensor((b,
10), dtype="float32"))
+ R.output(lv2)
+
+Before we talk about the dataflow block, let us first introduce the concept of
**pure** and
+**side-effect**. A function is **pure** or **side-effect free** if:
+
+- it only reads from its inputs and returns the result via its output
+- it will not change other parts of the program (such as incrementing a global
counter).
+
+For example, all ``R.call_tir`` functions are pure functions, as they only
read from their inputs
+and write the output to another new allocated tensor. However, the **inplace
operations** are not
+pure functions, in other words, they are side-effect functions, because they
will change the existing
+intermediate or input tensors.
+
+A dataflow block is a way for us to mark the computational graph regions of
the program.
+Specifically, within a dataflow block, all the operations need to be
**side-effect free**.
+Outside a dataflow block, the operations can contain side-effect.
+
+.. note::
+
+ A common question that arises is why we need to manually mark dataflow
blocks instead of
+ automatically inferring them. There are two main reasons for this approach:
+
+ - Automatic inference of dataflow blocks can be challenging and imprecise,
particularly
+ when dealing with calls to packed functions (such as cuBLAS
integrations). By manually
+ marking dataflow blocks, we enable the compiler to accurately understand
and optimize
+ the program's dataflow.
+ - Many optimizations can only be applied within dataflow blocks. For
instance, fusion
+ optimization is limited to operations within a single dataflow block. If
the compiler
+ were to incorrectly infer dataflow boundaries, it might miss crucial
optimization
+ opportunities, potentially impacting the program's performance.
+
+By allowing manual marking of dataflow blocks, we ensure that the compiler has
the most
+accurate information to work with, leading to more effective optimizations.
diff --git a/docs/deep_dive/relax/tutorials/README.txt
b/docs/deep_dive/relax/tutorials/README.txt
new file mode 100644
index 0000000000..b532ae9386
--- /dev/null
+++ b/docs/deep_dive/relax/tutorials/README.txt
@@ -0,0 +1,2 @@
+Deep Dive: Relax
+----------------
diff --git a/docs/deep_dive/relax/tutorials/relax_creation.py
b/docs/deep_dive/relax/tutorials/relax_creation.py
new file mode 100644
index 0000000000..f6278e3b65
--- /dev/null
+++ b/docs/deep_dive/relax/tutorials/relax_creation.py
@@ -0,0 +1,281 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""
+.. _relax-creation:
+
+Relax Creation
+==============
+This tutorial demonstrates how to create Relax functions and programs.
+We'll cover various ways to define Relax functions, including using TVMScript,
+and relax NNModule API.
+"""
+
+
+######################################################################
+# Create Relax programs using TVMScript
+# -------------------------------------
+# TVMScript is a domain-specific language for representing Apache TVM's
+# intermediate representation (IR). It is a Python dialect that can be used
+# to define an IRModule, which contains both TensorIR and Relax functions.
+#
+# In this section, we will show how to define a simple MLP model with only
+# high-level Relax operators using TVMScript.
+
+from tvm import relax, topi
+from tvm.script import ir as I
+from tvm.script import relax as R
+from tvm.script import tir as T
+
+
[email protected]_module
+class RelaxModule:
+ @R.function
+ def forward(
+ data: R.Tensor(("n", 784), dtype="float32"),
+ w0: R.Tensor((128, 784), dtype="float32"),
+ b0: R.Tensor((128,), dtype="float32"),
+ w1: R.Tensor((10, 128), dtype="float32"),
+ b1: R.Tensor((10,), dtype="float32"),
+ ) -> R.Tensor(("n", 10), dtype="float32"):
+ with R.dataflow():
+ lv0 = R.matmul(data, R.permute_dims(w0)) + b0
+ lv1 = R.nn.relu(lv0)
+ lv2 = R.matmul(lv1, R.permute_dims(w1)) + b1
+ R.output(lv2)
+ return lv2
+
+
+RelaxModule.show()
+
+######################################################################
+# Relax is not only a graph-level IR, but also supports cross-level
+# representation and transformation. To be specific, we can directly call
+# TensorIR functions in Relax function.
+
+
[email protected]_module
+class RelaxModuleWithTIR:
+ @T.prim_func
+ def relu(x: T.handle, y: T.handle):
+ n, m = T.int64(), T.int64()
+ X = T.match_buffer(x, (n, m), "float32")
+ Y = T.match_buffer(y, (n, m), "float32")
+ for i, j in T.grid(n, m):
+ with T.block("relu"):
+ vi, vj = T.axis.remap("SS", [i, j])
+ Y[vi, vj] = T.max(X[vi, vj], T.float32(0))
+
+ @R.function
+ def forward(
+ data: R.Tensor(("n", 784), dtype="float32"),
+ w0: R.Tensor((128, 784), dtype="float32"),
+ b0: R.Tensor((128,), dtype="float32"),
+ w1: R.Tensor((10, 128), dtype="float32"),
+ b1: R.Tensor((10,), dtype="float32"),
+ ) -> R.Tensor(("n", 10), dtype="float32"):
+ n = T.int64()
+ cls = RelaxModuleWithTIR
+ with R.dataflow():
+ lv0 = R.matmul(data, R.permute_dims(w0)) + b0
+ lv1 = R.call_tir(cls.relu, lv0, R.Tensor((n, 128),
dtype="float32"))
+ lv2 = R.matmul(lv1, R.permute_dims(w1)) + b1
+ R.output(lv2)
+ return lv2
+
+
+RelaxModuleWithTIR.show()
+
+######################################################################
+# .. note::
+#
+# You may notice that the printed output is different from the written
+# TVMScript code. This is because we print the IRModule in a standard
+# format, while we support syntax sugar for the input
+#
+# For example, we can combine multiple operators into a single line, as
+#
+# .. code-block:: python
+#
+# lv0 = R.matmul(data, R.permute_dims(w0)) + b0
+#
+# However, the normalized expression requires only one operation in one
+# binding. So the printed output is different from the written TVMScript
code,
+# as
+#
+# .. code-block:: python
+#
+# lv: R.Tensor((784, 128), dtype="float32") = R.permute_dims(w0, axes=None)
+# lv1: R.Tensor((n, 128), dtype="float32") = R.matmul(data, lv,
out_dtype="void")
+# lv0: R.Tensor((n, 128), dtype="float32") = R.add(lv1, b0)
+#
+
+######################################################################
+# Create Relax programs using NNModule API
+# ----------------------------------------
+# Besides TVMScript, we also provide a PyTorch-like API for defining neural
networks.
+# It is designed to be more intuitive and easier to use than TVMScript.
+#
+# In this section, we will show how to define the same MLP model using
+# Relax NNModule API.
+
+from tvm.relax.frontend import nn
+
+
+class NNModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.fc1 = nn.Linear(784, 128)
+ self.relu1 = nn.ReLU()
+ self.fc2 = nn.Linear(128, 10)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.relu1(x)
+ x = self.fc2(x)
+ return x
+
+
+######################################################################
+# After we define the NNModule, we can export it to TVM IRModule via
+# ``export_tvm``.
+
+mod, params = NNModule().export_tvm({"forward": {"x": nn.spec.Tensor(("n",
784), "float32")}})
+mod.show()
+
+######################################################################
+# We can also insert customized function calls into the NNModule, such as
+# Tensor Expression(TE), TensorIR functions or other TVM packed functions.
+
+
[email protected]_func
+def tir_linear(x: T.handle, w: T.handle, b: T.handle, z: T.handle):
+ M, N, K = T.int64(), T.int64(), T.int64()
+ X = T.match_buffer(x, (M, K), "float32")
+ W = T.match_buffer(w, (N, K), "float32")
+ B = T.match_buffer(b, (N,), "float32")
+ Z = T.match_buffer(z, (M, N), "float32")
+ for i, j, k in T.grid(M, N, K):
+ with T.block("linear"):
+ vi, vj, vk = T.axis.remap("SSR", [i, j, k])
+ with T.init():
+ Z[vi, vj] = 0
+ Z[vi, vj] = Z[vi, vj] + X[vi, vk] * W[vj, vk]
+ for i, j in T.grid(M, N):
+ with T.block("add"):
+ vi, vj = T.axis.remap("SS", [i, j])
+ Z[vi, vj] = Z[vi, vj] + B[vj]
+
+
+class NNModuleWithTIR(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.fc1 = nn.Linear(784, 128)
+ self.fc2 = nn.Linear(128, 10)
+
+ def forward(self, x):
+ n = x.shape[0]
+ # We can call external functions using nn.extern
+ x = nn.extern(
+ "env.linear",
+ [x, self.fc1.weight, self.fc1.bias],
+ out=nn.Tensor.placeholder((n, 128), "float32"),
+ )
+ # We can also call TensorIR via Tensor Expression API in TOPI
+ x = nn.tensor_expr_op(topi.nn.relu, "relu", [x])
+ # We can also call other TVM packed functions
+ x = nn.tensor_ir_op(
+ tir_linear,
+ "tir_linear",
+ [x, self.fc2.weight, self.fc2.bias],
+ out=nn.Tensor.placeholder((n, 10), "float32"),
+ )
+ return x
+
+
+mod, params = NNModuleWithTIR().export_tvm(
+ {"forward": {"x": nn.spec.Tensor(("n", 784), "float32")}}
+)
+mod.show()
+
+
+######################################################################
+# Create Relax programs using Block Builder API
+# ---------------------------------------------
+# In addition to the above APIs, we also provide a Block Builder API for
+# creating Relax programs. It is a IR builder API, which is more
+# low-level and widely used in TVM's internal logic, e.g writing a
+# customized pass.
+
+bb = relax.BlockBuilder()
+n = T.int64()
+x = relax.Var("x", R.Tensor((n, 784), "float32"))
+fc1_weight = relax.Var("fc1_weight", R.Tensor((128, 784), "float32"))
+fc1_bias = relax.Var("fc1_bias", R.Tensor((128,), "float32"))
+fc2_weight = relax.Var("fc2_weight", R.Tensor((10, 128), "float32"))
+fc2_bias = relax.Var("fc2_bias", R.Tensor((10,), "float32"))
+with bb.function("forward", [x, fc1_weight, fc1_bias, fc2_weight, fc2_bias]):
+ with bb.dataflow():
+ lv0 = bb.emit(relax.op.matmul(x, relax.op.permute_dims(fc1_weight)) +
fc1_bias)
+ lv1 = bb.emit(relax.op.nn.relu(lv0))
+ gv = bb.emit(relax.op.matmul(lv1, relax.op.permute_dims(fc2_weight)) +
fc2_bias)
+ bb.emit_output(gv)
+ bb.emit_func_output(gv)
+
+mod = bb.get()
+mod.show()
+
+######################################################################
+# Also, Block Builder API supports building cross-level IRModule with both
+# Relax functions, TensorIR functions and other TVM packed functions.
+
+bb = relax.BlockBuilder()
+with bb.function("forward", [x, fc1_weight, fc1_bias, fc2_weight, fc2_bias]):
+ with bb.dataflow():
+ lv0 = bb.emit(
+ relax.call_dps_packed(
+ "env.linear",
+ [x, fc1_weight, fc1_bias],
+ out_sinfo=relax.TensorStructInfo((n, 128), "float32"),
+ )
+ )
+ lv1 = bb.emit_te(topi.nn.relu, lv0)
+ tir_gv = bb.add_func(tir_linear, "tir_linear")
+ gv = bb.emit(
+ relax.call_tir(
+ tir_gv,
+ [lv1, fc2_weight, fc2_bias],
+ out_sinfo=relax.TensorStructInfo((n, 10), "float32"),
+ )
+ )
+ bb.emit_output(gv)
+ bb.emit_func_output(gv)
+mod = bb.get()
+mod.show()
+
+######################################################################
+# Note that the Block Builder API is not as user-friendly as the above APIs,
+# but it is lowest-level API and works closely with the IR definition. We
+# recommend using the above APIs for users who only want to define and
+# transform a ML model. But for those who want to build more complex
+# transformations, the Block Builder API is a more flexible choice.
+
+######################################################################
+# Summary
+# -------
+# This tutorial demonstrates how to create Relax programs using TVMScript,
+# NNModule API, Block Builder API and PackedFunc API for different use cases.
diff --git a/docs/deep_dive/relax/tutorials/relax_transformation.py
b/docs/deep_dive/relax/tutorials/relax_transformation.py
new file mode 100644
index 0000000000..01d8e4e320
--- /dev/null
+++ b/docs/deep_dive/relax/tutorials/relax_transformation.py
@@ -0,0 +1,141 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""
+.. _relax-transform:
+
+Transformation
+--------------
+In this section, we will dive into the transformation of Relax programs.
+Transformations is one of the key ingredients of the compilation flows
+for optimizing and integrating with hardware backends.
+"""
+
+######################################################################
+# Let's first create a simple Relax program as what we have done in
+# the :ref:`previous section <relax-creation>`.
+
+import tvm
+from tvm import IRModule, relax
+from tvm.relax.frontend import nn
+
+
+class NNModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.fc1 = nn.Linear(784, 128)
+ self.relu1 = nn.ReLU()
+ self.fc2 = nn.Linear(128, 10)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.relu1(x)
+ x = self.fc2(x)
+ return x
+
+
+origin_mod, params = NNModule().export_tvm(
+ {"forward": {"x": nn.spec.Tensor(("n", 784), "float32")}}
+)
+origin_mod.show()
+
+######################################################################
+# Apply transformations
+# ~~~~~~~~~~~~~~~~~~~~~
+# Passes are the main way to apply transformations to the program.
+# We can apply passes to the program. As first step, let's apply
+# a built-in pass ``LegalizeOps`` to lower the high-level operators
+# into low-level operators.
+
+mod = tvm.relax.transform.LegalizeOps()(origin_mod)
+mod.show()
+
+######################################################################
+# As we can see from the output, the high-level operators (aka ``relax.op``)
in the program
+# are replaced by their corresponding low-level operators (aka
``relax.call_tir``).
+#
+# Then let's trying to apply the operator fusion, which is a wide-used
optimization technique
+# in ML compilers. Note that in relax, fusion optimizations are done with the
collaboration of
+# a set of passes. We can apply them in a sequence.
+
+mod = tvm.ir.transform.Sequential(
+ [
+ tvm.relax.transform.AnnotateTIROpPattern(),
+ tvm.relax.transform.FuseOps(),
+ tvm.relax.transform.FuseTIR(),
+ ]
+)(mod)
+mod.show()
+
+######################################################################
+# As result, we can see that the ``matmul``, ``add`` and ``relu`` operators
are fused
+# into one kernel (aka one ``call_tir``).
+#
+# For all built-in passes, please refer to :py:class:`relax.transform`.
+#
+# Custom Passes
+# ~~~~~~~~~~~~~
+# We can also define our own passes. Let's taking an example of rewrite the
``relu``
+# operator to ``gelu`` operator.
+#
+# First, we need to write a Relax IR Mutator to do the rewriting.
+
+from tvm.relax.expr_functor import PyExprMutator, mutator
+
+
+@mutator
+class ReluRewriter(PyExprMutator):
+ def __init__(self, mod):
+ super().__init__(mod)
+
+ def visit_call_(self, call: relax.Call) -> relax.Expr:
+ # visit the relax.Call expr, and only handle the case when op is
relax.nn.relu
+ if call.op.name == "relax.nn.relu":
+ return relax.op.nn.gelu(call.args[0])
+
+ return super().visit_call_(call)
+
+
+######################################################################
+# Then we can write a pass to apply the mutator to the whole module.
+
+
[email protected]_pass(opt_level=0, name="ReluToGelu")
+class ReluToGelu: # pylint: disable=too-few-public-methods
+ def transform_module(self, mod: IRModule, _ctx: tvm.transform.PassContext)
-> IRModule:
+ """IRModule-level transformation"""
+ rewriter = ReluRewriter(mod)
+ for g_var, func in mod.functions_items():
+ if isinstance(func, relax.Function):
+ func = rewriter.visit_expr(func)
+ rewriter.builder_.update_func(g_var, func)
+ return rewriter.builder_.get()
+
+
+mod = ReluToGelu()(origin_mod)
+mod.show()
+
+######################################################################
+# The printed output shows that the ``relax.nn.relu`` operator is
+# rewritten to ``relax.nn.gelu`` operator.
+#
+# For the details of the mutator, please refer to
:py:class:`relax.expr_functor.PyExprMutator`.
+#
+# Summary
+# ~~~~~~~
+# In this section, we have shown how to apply transformations to the Relax
program.
+# We have also shown how to define and apply custom transformations.
diff --git a/docs/deep_dive/tensor_ir/abstraction.rst
b/docs/deep_dive/tensor_ir/abstraction.rst
index fc11d7f391..a832fef995 100644
--- a/docs/deep_dive/tensor_ir/abstraction.rst
+++ b/docs/deep_dive/tensor_ir/abstraction.rst
@@ -44,7 +44,6 @@ the compute statements themselves.
Key Elements of Tensor Programs
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
The demonstrated primitive tensor function calculates the element-wise sum of
two vectors.
The function:
diff --git a/docs/deep_dive/tensor_ir/index.rst
b/docs/deep_dive/tensor_ir/index.rst
index 432d47116a..46bed7c423 100644
--- a/docs/deep_dive/tensor_ir/index.rst
+++ b/docs/deep_dive/tensor_ir/index.rst
@@ -19,7 +19,7 @@
TensorIR
========
-TensorIR is one of the core abstraction in Apache TVM Unity stack, which is
used to
+TensorIR is one of the core abstraction in Apache TVM stack, which is used to
represent and optimize the primitive tensor functions.
.. toctree::
@@ -27,5 +27,5 @@ represent and optimize the primitive tensor functions.
abstraction
learning
- tutorials/creation
- tutorials/transformation
+ tutorials/tir_creation
+ tutorials/tir_transformation
diff --git a/docs/deep_dive/tensor_ir/tutorials/creation.py
b/docs/deep_dive/tensor_ir/tutorials/tir_creation.py
similarity index 100%
rename from docs/deep_dive/tensor_ir/tutorials/creation.py
rename to docs/deep_dive/tensor_ir/tutorials/tir_creation.py
diff --git a/docs/deep_dive/tensor_ir/tutorials/transformation.py
b/docs/deep_dive/tensor_ir/tutorials/tir_transformation.py
similarity index 100%
rename from docs/deep_dive/tensor_ir/tutorials/transformation.py
rename to docs/deep_dive/tensor_ir/tutorials/tir_transformation.py
diff --git a/docs/index.rst b/docs/index.rst
index 2eec0cb99e..2102bdd33a 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -55,6 +55,7 @@ driving its costs down.
:caption: Deep Dive
deep_dive/tensor_ir/index
+ deep_dive/relax/index
.. toctree::
:maxdepth: 1
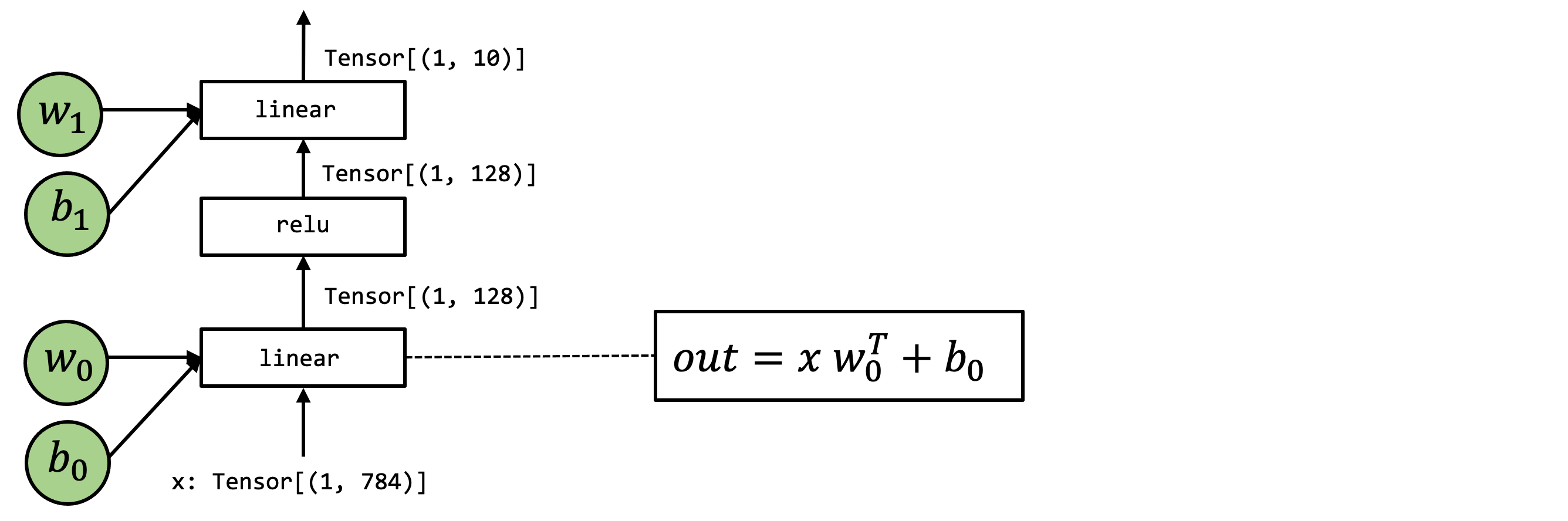{kind=link}