simplelins opened a new issue #6389:
URL: https://github.com/apache/incubator-tvm/issues/6389
Hi,
we do a performance test in a sgx env by reduce the usable memory ,in
other way first we malloc memory from 75m-95m,and then run sgx demo to get the
api's latency(fused_nn_contrib_conv2d_NCHWc_add_nn_relu) ,now we show some
details as below:
uname -a
Linux 5.3.0-62-generic #56~18.04.1-Ubuntu SMP Wed Jun 24 16:17:03 UTC 2020
x86_64 x86_64 x86_64 GNU/Linux
base of source :
git log :commit 679fd29a7f6cae17d8c8b1b734a0abb0592ab3a8 (HEAD ->
Nick_Hynes_SGX)
the nets we used that only one layer, code as below :
`def one_layer(batch_size,
num_classes=10,
image_shape=(1, 28, 28),
dtype="float32", alpha=1.0, layout='NCHW'):
body = relay.var("data",
shape=image_shape,
dtype=dtype)
body = conv_block(body, 'conv_block_1', channels=int(32*alpha),
strides=(2, 2),
layout=layout)
return relay.Function(relay.analysis.free_vars(body), body)
def conv_block(data, name, channels, kernel_size=(3, 3), strides=(1, 1),
padding=(1, 1), epsilon=1e-5, layout='NCHW'):
"""Helper function to construct conv_bn-relu"""
# convolution + bn + relu
conv = layers.conv2d(
data=data,
channels=channels,
kernel_size=kernel_size,
strides=strides,
padding=padding,
name=name+'_conv')
bn = layers.batch_norm_infer(data=conv, epsilon=epsilon, name=name +
'_bn')
act = relay.nn.relu(data=bn)
return act
`
malloc memory by new a vector,befor run sgx demo ,
'let mut data = (0..num * 1024 * 1024 / 4)
.map(|y| y as u32)
.collect::<Vec<u32>>();'
after sgx demo successfully,
'for d in &mut data {
*d += 2;
}'
we get some datas as below:

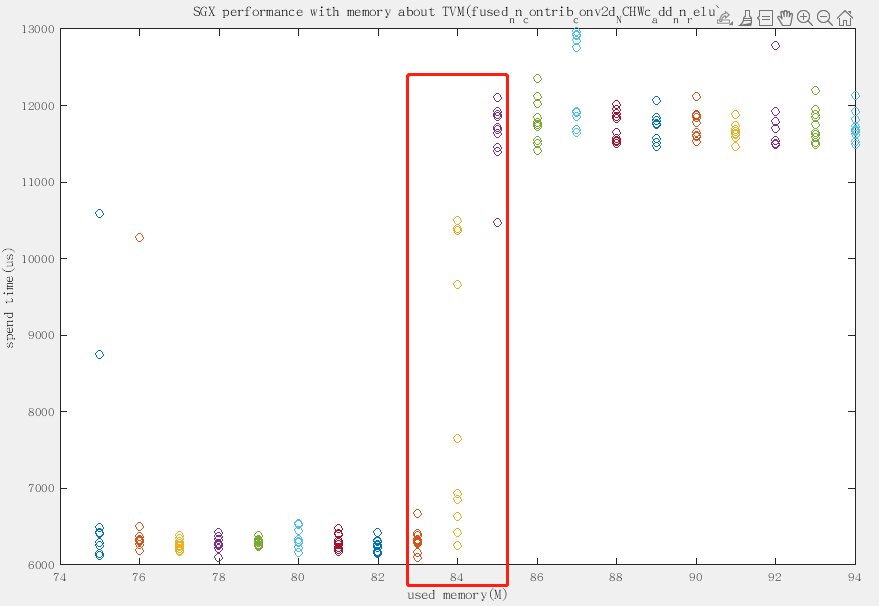
**we can find that the latency from 83m to 85m Dramatic increase.**
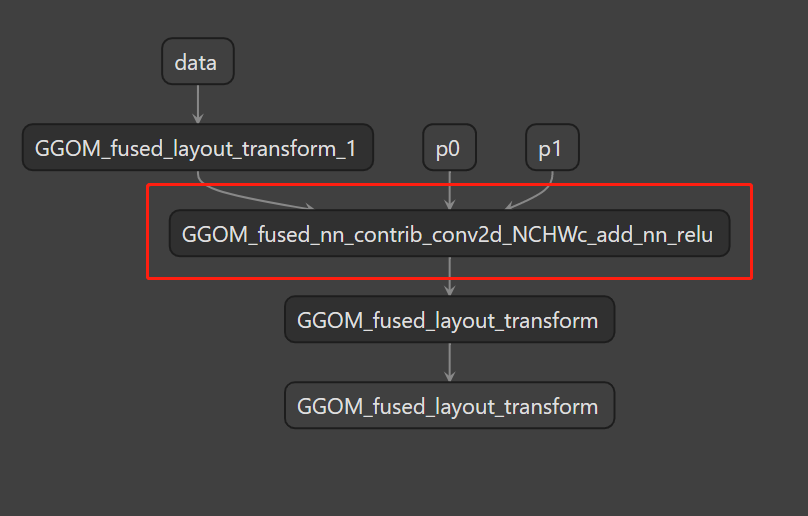
graph.json as below,we only add a prefix for model.o's api.:
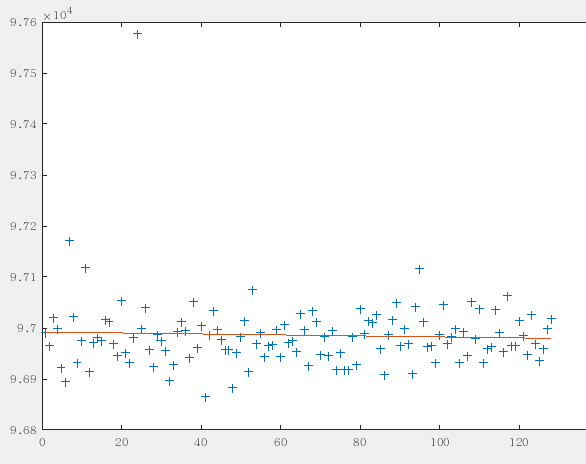
and more, we do a test for a normal app that only do a simple dh algorithm,
show as below:
In summary, we guess if there is a bug about tvm,please check!
if neccessry,i can upload all the test codes
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}