merrymercy commented on pull request #6671: URL: https://github.com/apache/incubator-tvm/pull/6671#issuecomment-717506384
I tested your autotvm implementation and found it is significantly slower. To do the test, you can run this tutorial (https://github.com/apache/incubator-tvm/blob/main/tutorials/autotvm/tune_conv2d_cuda.py) and replace the n_trial=20 with n_trial=100 The number we care about is the time spent on simulated annealing which actually uses the xgboost_cost_model.py modified by you. This is the screenshot before your PR. You can see elapsed: 63.40 in the last line, which means it takes 63.40 ms to do simulated annealing. 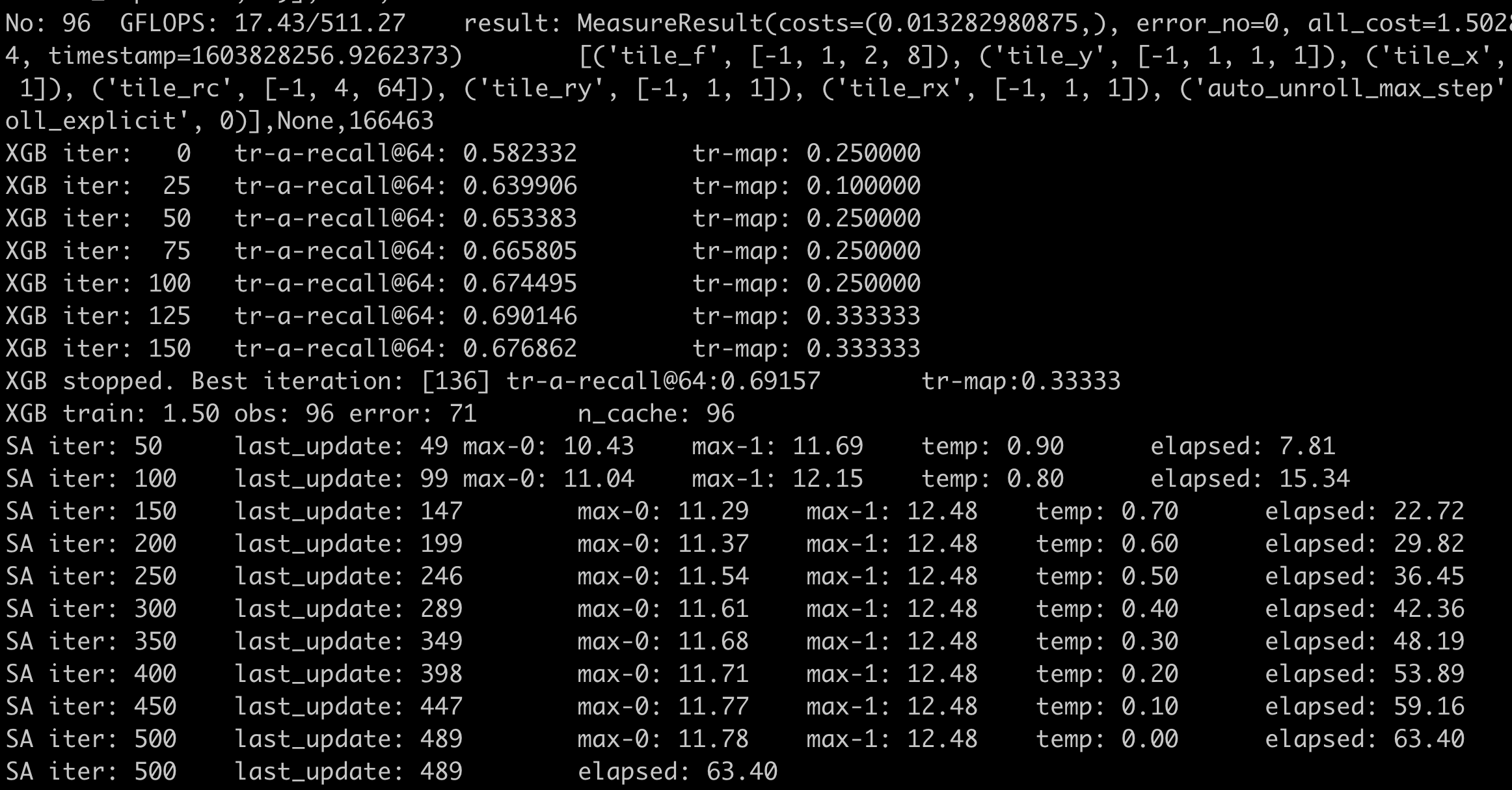 However, with your PR, the number becomes 194.67 <img width="1152" alt="Screen Shot 2020-10-27 at 12 47 15 PM" src="https://user-images.githubusercontent.com/15100009/97355886-cff21380-1854-11eb-9058-72eb1ac9f844.png";> I don’t understand why the autotvm part is required for that PR, because autotvm and auto-scheduler are totally independent. Can you delete autotvm files in that PR? The test machine is a 24-core Intel E5 ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}