huangxiao2008 commented on pull request #10580: URL: https://github.com/apache/tvm/pull/10580#issuecomment-1066257810
@masahi @Meteorix Take a concrete case for example , such as we compute a GEMM with M = 128, N = 128 and K = 16, and Batch = 1. and Hardcode setting block_row_warps = 2, and block_col_warps = 2 in schedule template. In this case, a Warp will cover 16x16 tile size, and single wmma.sync instruction will do all the work. ======================================Before modify , Each Warp takes 4 wmma.sync ====================================================== 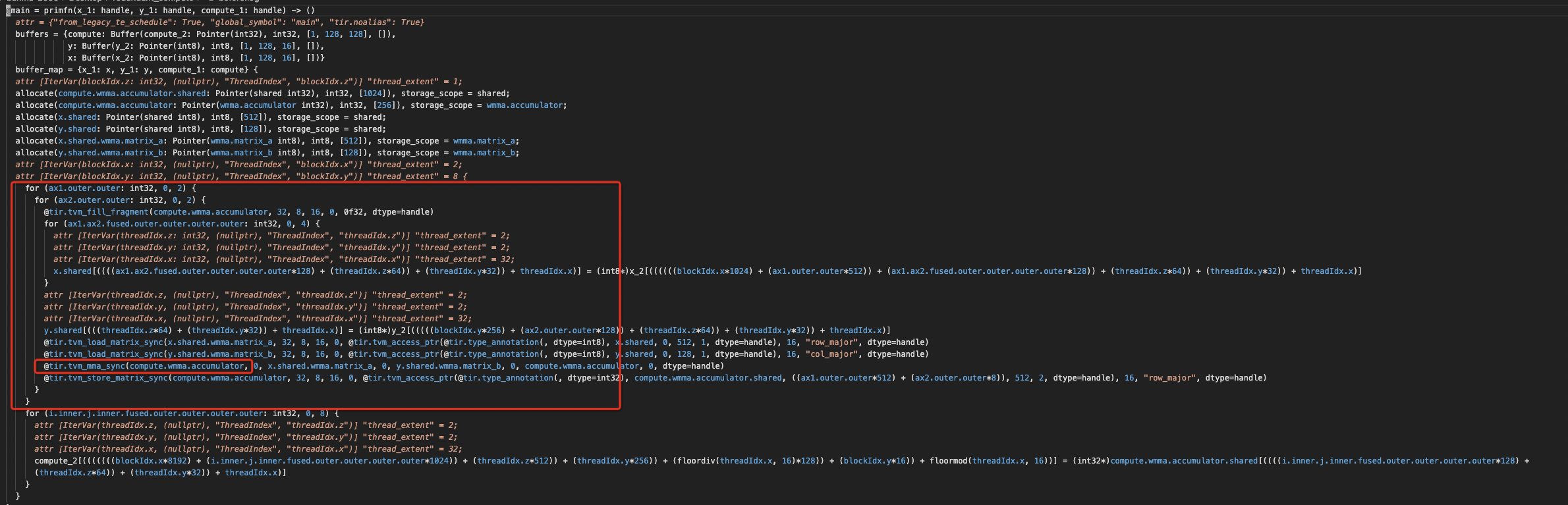 =====================================After modify, the loop is binded to threadIdx.z threadIdx.y and each warp has a single wmma.sync ==================== 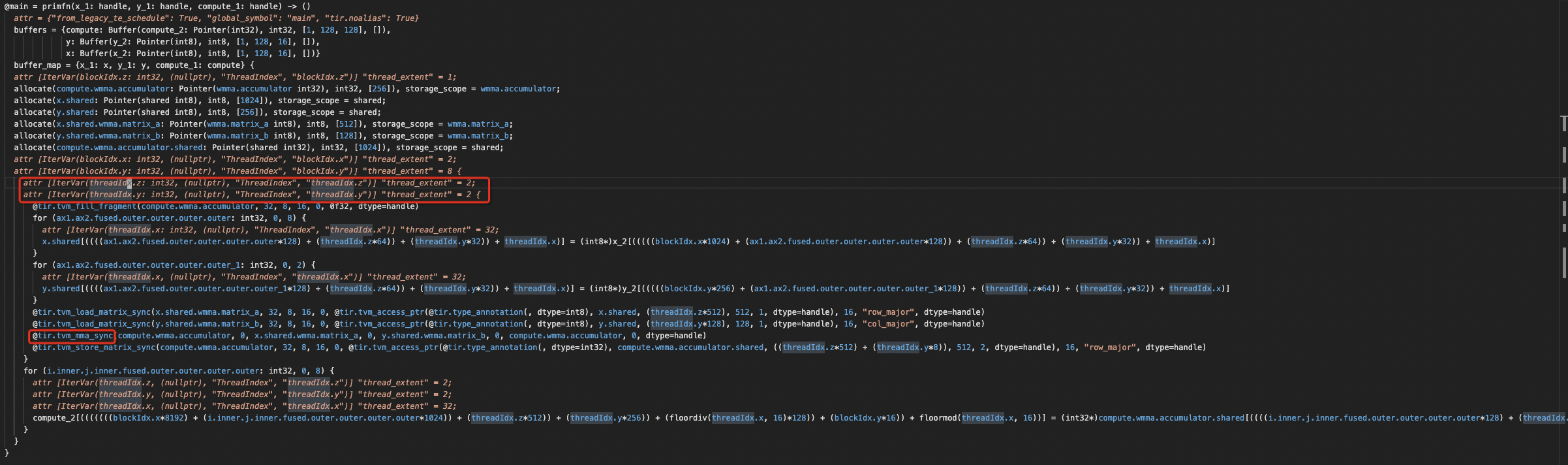 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}