DzAvril opened a new pull request #10650: URL: https://github.com/apache/tvm/pull/10650
During performance optimization for platform Xavier which has a Volta GPU in it, we found that tuning by AutoTVM with subgraph as granularity could bring performance improvement. Because the data type of the subgraph's output may be different from the data type of the subgraph's anchor operator's output, this may change the task from memory-bound to compute-bound or change in reverse. Let's take the subgraph in the figure below as an example. If we tune with the single convolution the output data type is 'Int32' but if we tune with the subgraph the output data type is 'Int8'. The former's data size is four times the latter one. But in the actual inference, the data type is 'Int8' same as the latter one. So the best config searched by tuning with a single operator maybe not be the best for the subgraph. 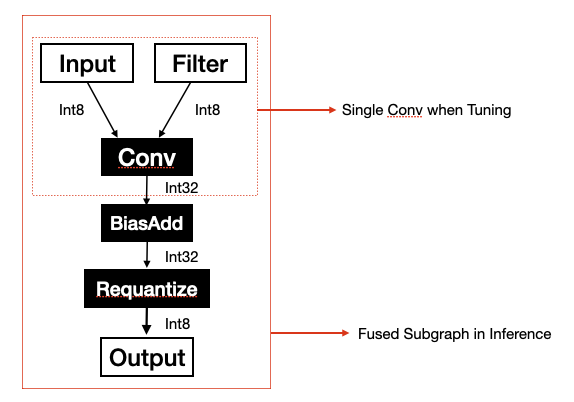 We also run an example to verify the theory above. - We wrote a schedule marked as ```ScheduleA``` for the subgraph above by hardcode and the latency of subgraph inferencing is 104 microseconds. Then we tuned the subgraph with single op as granularity. In the tuning log we found ```ScheduleA``` and the latency recorded in the measurement result is 329 microseconds. - The best schedule from the tuned log in the step above is marked as ```ScheduleB``` and the latency recorded in the measurement result is 237 microseconds. The latency of subgraph inferencing with ```ScheduleB``` is 224 microseconds. From the example above we can tell AutoTVM would not find ```ScheduleA```, the obvious better schedule. This means the tuning result is distorted, the distortion would be more obvious if the shape of the output became bigger. By the way, you may have a question why we don't just tune with AutoSchedule, this is because we want to employ tensor core on Volta GPU to compute matrix multiply and auto-schedule doesn't support tensorize. This PR proposes a method to tune with subgraph as granularity by AUTOTVM. As we know, tuning with a single operator we need function ```fcompute``` which computes the output tensors of the operator and function ```fschedule``` which schedules the computation. With these two functions, we can build a measurable program running on the device. So the key problem is assigning function ```fcompute``` and function ```fschedule``` for subgraph. In this PR, we use the fucntion ```fschedule``` of the anchor operator as the subgraph's function ```fschedule```. As for function ```fcompute```, its purpose is getting output tensors of the subgraph. The function ```LowerToTECompute::Lower``` can get the output tensors of the subgraph, so we can use these tensors as output of subgraph's function ```fcompute```. The whole process can breakdown into two major phases and it will be clearer reading with code. 1. Task extracting and tuning. 1.1 Select best implementation to compute output for anchor operator and record implementation name `best_impl_name` 1.2 Lower subgraph to `outputs` 1.3 Create subgraph tuning task name `task_name` with subgraph name and `iotensors` extracted from `outputs`. 1.4 Add subgraph task with `task_name`, `iotensors` and `best_impl_name`. 1.5 Create `workload` for subgraph tuning task with `task_name` and `iotensors`. 1.6 Set function `fcompute` for subgraph by returning `outputs` . 1.7 Set function `fschedule` for subgraph by querying table with `best_impl_name`. 1.8 Tune. 2. Building. 2.1 Apply the best history. 2.2 Select best implementation to compute output for anchor operator and record implementation name `best_impl_name` 2.3 Lower subgraph to `outputs` 2.4 Create subgraph tuning task name `task_name` with subgraph name and `iotensors` extracted from `outputs`. 2.5 Create `workload` for subgraph tuning task with `task_name` and `iotensors`. 2.6 Lower schedule with the best config queried by `workload`. 2.7 Codegen. In our optimization job, employing tuning with subgraph achieved **6.3%** performance improvement. **But**, there are two cases in which tuning with subgraph may not get better performance. Case 1: Anchor operator has more than one implementation. We register the subgraph tuning task by `outputs` in step 1.4. No matter how many implementations the anchor operator has, step 1.1 will only pick the implementation with the highest level and return outputs computed by it. So the subgraph tuning tasks may not contain the potential best implementation. Case 2: Anchor operator's function `fcompute` needs value from config such as code block below. In step 2.2, computing output will call function `_pack_data` and the `cfg` suppose to be the best config of the subgraph. But in step 2.2 we don't know which subgraph the anchor operator belongs to yet, so we cannot get the right config from the best history and fallback to the default one. This may bring great performance regression. ```python def _pack_data(cfg, data, kernel): n, _, ih, iw = get_const_tuple(data.shape) oc, ic, kh, kw = get_const_tuple(kernel.shape) ic_bn, oc_bn = cfg["tile_ic"].size[-1], cfg["tile_oc"].size[-1] ...... ``` The cases above seem too hard to resolve in the current implementation. You're welcome to make any suggestions. Thanks!! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}