Updates on questions in the IO framework document.
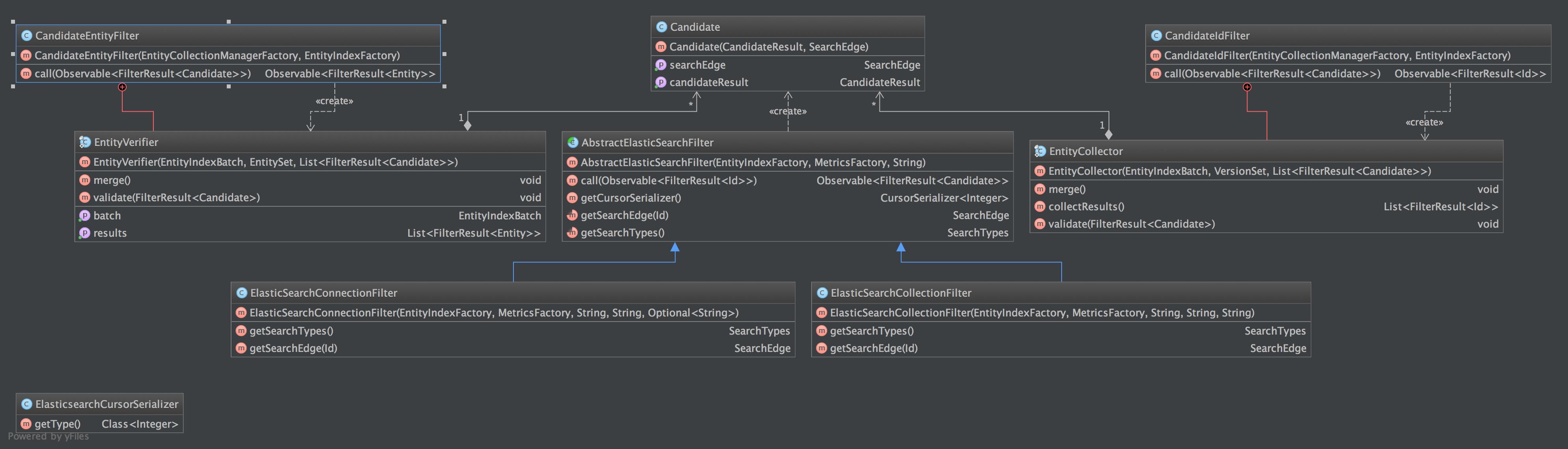
Project: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/repo Commit: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/commit/eae4cbd5 Tree: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/tree/eae4cbd5 Diff: http://git-wip-us.apache.org/repos/asf/incubator-usergrid/diff/eae4cbd5 Branch: refs/heads/USERGRID-614 Commit: eae4cbd599772615dce01bf3e8fe6d9d093ddb32 Parents: 944253a Author: GERey <[email protected]> Authored: Tue May 5 10:52:04 2015 -0700 Committer: GERey <[email protected]> Committed: Tue May 5 10:52:04 2015 -0700 ---------------------------------------------------------------------- .../usergrid/corepersistence/pipeline/README.md | 23 ++++++-------------- 1 file changed, 7 insertions(+), 16 deletions(-) ---------------------------------------------------------------------- http://git-wip-us.apache.org/repos/asf/incubator-usergrid/blob/eae4cbd5/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md ---------------------------------------------------------------------- diff --git a/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md b/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md index 5b98c31..780ada5 100644 --- a/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md +++ b/stack/core/src/main/java/org/apache/usergrid/corepersistence/pipeline/README.md @@ -102,7 +102,6 @@ Consider the following example flow: 1. Results Page * Contains the encapsulation of entities as a group of responses. * Holds the list of entities along with the limit of the entities we want for a response and the cursor that gets returned. - * Maybe refactor to collect module? 1. EdgePath * Represents the path from the intial entity to the emitted element. * A list of these represnt a path through the graph to a specific element. @@ -115,7 +114,7 @@ Consider the following example flow: 1. EntityFilter - * A filter that is used when we can potentially serialize pages via cursor. ? (not entirely sure I know what that means.) + * This filter is our intermediate resume filter. So if we're returning in consistent results around the end of the limit query then it is possible for the last result on the last page and first result on the resume page to have the same entity. This filter detects is that is the case and will filter the first result if the id's of the last entity of the last page and the first entity of the new page match. 1. IdCursorSerializer * The serializer for Id's. 1. AbstractCollector @@ -158,20 +157,12 @@ Consider the following example flow: ###Indepth Elasticsearch Module Explanation  - - 1. Impl Module - * contains all the implementations and verfiers and loaders for elasticsearch - - 3. CandidateResultsEntityResultsCollector - * Collects the results from Elasticsearch then retrieves them from cassandra and converts them from 2.0 to 1.0 entities that are suitable for return. - 4. CandidateResultsIdVerifyFilter - * Filter that verifies that the canaidate results id's are correct???? What else does this do ? isn't that what the collector does? - 5. ElasticsearchCursorSerializer + 1. ElasticsearchCursorSerializer * The serializer we use to decode and make sense of the elasticsearch cursor. 1. Candidate * Contains the candidate result and the search edge that was searched for that result. - * Is Canadidate really a good name for this class if it actually contains the CandidateResults? What does this class represent? + * Since we needed the search edge along with the CandidateResults we packaged them together into a single class. 1. CandidateIdFilter * Takes in candidate results and outputs a stream of validated Ids. * Uses the EntityCollector to map a fresh new cp entity to an old 1.0 version of the entity. Then we return those results to the upper tiers. @@ -179,14 +170,14 @@ Consider the following example flow: * I'm not entirely clear how the collector actually does the mapping. Seems like it just does the elasticsearch repair and checks entity versions. Then collects the entities into a result set 1. AbstractElasticSearchFilter * This extends into the same pattern as the Graph Module where we make a abstract filter so we can extend it to easily accomodate Collection or Connection searching. - 2. ElasticSearchConnectionFilter + 1. ElasticSearchConnectionFilter * Creates the filter that will go and search for connections in elasticsearch. - 3. ElasticSearchCollectionFilter + 1. ElasticSearchCollectionFilter * Creates the filter that will go and search for collections in elasticsearch. - 4. CandidateEntityFilter + 1. CandidateEntityFilter * Searches on incoming Candidate entity and returns an entity instead of an Id like the CandidateIdFilter. * Does a similar repair using the EntityVerifier. - 5. EntityVerifier + 1. EntityVerifier * Collects the entities emitted and returns them as a result set. Also verifies that the entities exist or if they need to be repaired in elasticsearch.
{kind=link}