Dear Wiki user, You have subscribed to a wiki page or wiki category on "Hadoop Wiki" for change notification.
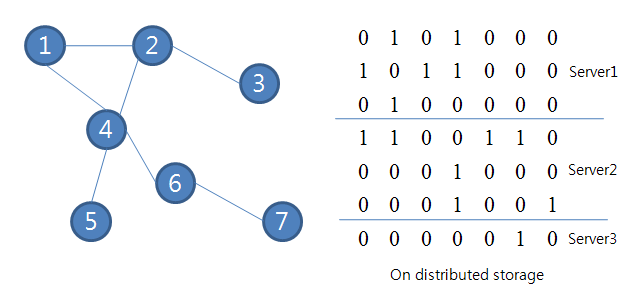
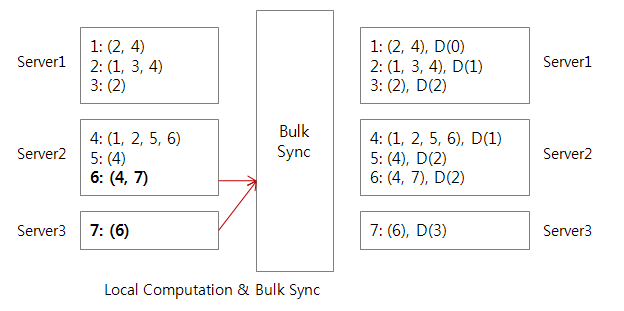
The following page has been changed by edwardyoon: http://wiki.apache.org/hadoop/Hamburg ------------------------------------------------------------------------------ == Motivation == The MapReduce (M/R) programming model is inappropriate to graph problems because of the following reasons: - - ''Do you know other situations that might fall into what you are describing above?'' * '''!MapReduce does not support traversing graph''' â A mapper reads input data sequentially, and it canât control its input data. In contrast, most of the graph problems are based on walking vertices step by step. Walking vertices is to expand adjacent vertices from a given vertex. This operation is only available if current input data can be determined by the previous operation. In MapReduce, however, the previous operation cannot affect the input data of the next operation. Traversing a vertex is the most basic premitive operation in graph operations. Consequently, graph processing with MapReduce is very limited. In order to come over this limit, we have to avoid traverse of graph in order to solve graph problems ([http://ieeexplore.ieee.org/search/wrapper.jsp?arnumber=5076317 Graph Twiddling in a MapReduce World]) or have to use many M/R iterations each time walk vertices ([http://blog.udanax.org/2009/02/breadth-first-search-mapreduce.html Breadth-First Search (B FS) & MapReduce]). * '''!MapReduce limits to assigning one reducer''' - In a MapReduce problem on graph data, assigning appropriate reducers according to their relations of partitioned graphs is very hard. Assigning only one reducer is a straightforward way to solve their complex relations, but it is apparent to cause deterioration of scalability. @@ -13, +11 @@ Therefore, we need a new programming model for graph processing on Hadoop. - ''We should survey other areas -- Edward J.'' + == Goal == - == Goal == * Support graph traverse * Support a simple programming interface dealing graph data * Follow the scalability concept of shared-nothing architecture @@ -33, +30 @@ Each worker will process the data fragments stored locally. And then, We can do bulk synchronization using collected communication data. The 'Computation' and 'Bulk synchronization' can be performed iteratively, Data for synchronization can be compressed to reduce network usage. The main difference between Hamburg and M/R is that Hamburg does not make intermediate data aggregate into reducer. Instead, each computation node communicates only necessary data into one another. It will be efficient if total communicated data is smaller then intermediate data to be aggregated into reducers. Plainly, It aims to improve the performance of traverse operations in Graph computing. - For example, to explores all the neighboring nodes from the root node using Map/Reduce (FYI, [http://blog.udanax.org/2009/02/breadth-first-search-mapreduce.html Breadth-First Search (BFS) & MapReduce]), We need a lot of iterations to get next vertex per-hop time. - - Let's assume the graph looks like presented below: + For example, let's assume the graph looks like presented below: [http://lh5.ggpht.com/_DBxyBGtfa3g/SmQTwhOSGwI/AAAAAAAABmY/ERiJ2BUFxI0/s800/figure2.PNG] + + We can store the graph as a adjacency matrix in HDFS or HBase and use MapReduce to explores all the neighboring nodes, but we need a lot of iterations to get next vertex per-hop time since as mentioned motivation. However, practically, we need only one communication between server2 and server3 for determine the distance between 6 and 7 as below: + + [http://lh6.ggpht.com/_DBxyBGtfa3g/SmQTwvxT2zI/AAAAAAAABmc/BRrv7plzPtc/s800/figure3.PNG] ''TODO: write more detail of above. -- Edward J.''
{kind=link}
{kind=link}