tomscut opened a new pull request #3366: URL: https://github.com/apache/hadoop/pull/3366
JIRA: [HDFS-16203](https://issues.apache.org/jira/browse/HDFS-16203) **Discover datanodes with unbalanced volume usage by the standard deviation.** **In some scenarios, we may cause unbalanced datanode disk usage:** 1. Repair the damaged disk and make it online again. 2. Add disks to some Datanodes. 3. Some disks are damaged, resulting in slow data writing. 4. Use some custom volume choosing policies. In the case of unbalanced disk usage, a sudden increase in datanode write traffic may result in busy disk I/O with low volume usage, resulting in decreased throughput across datanodes. We need to find these nodes in time to do diskBalance, or other processing. Based on the volume usage of each datanode, we can calculate the standard deviation of the volume usage. The more unbalanced the volume, the higher the standard deviation. **We can display the result on the Web of namenode, and then sorting directly to find the nodes where the volumes usages are unbalanced.** **This interface is only used to obtain metrics and does not adversely affect namenode performance.** 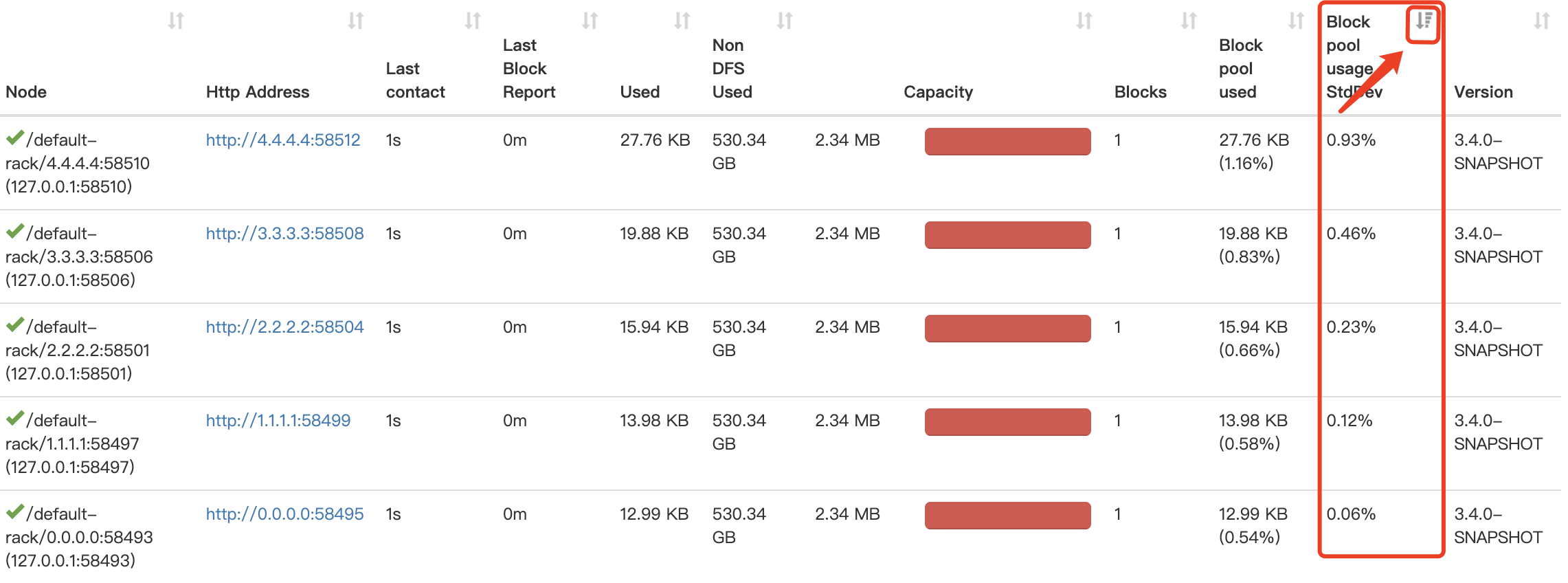 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}