Pádraig Brady wrote: > $ yes áááááááááááááááááááá | head -n100000 > mbc.txt > $ yes 12345678901234567890 | head -n100000 > num.txt > > ===== Before ==== > > $ time src/wc -Lm < mbc.txt > 2100000 20 > real 0m0.186s > > $ time src/wc -m < mbc.txt > 2100000 > real 0m0.186s
Profiling this on a glibc system, using the valgrind + kcachegrind
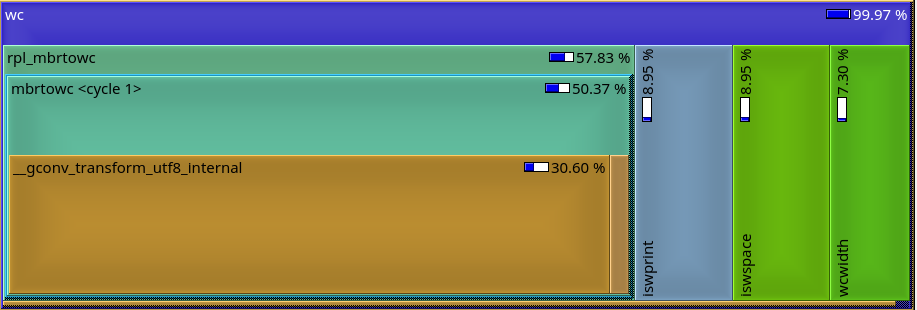
combination [1], I obtain the attached treemap.
$ valgrind --tool=callgrind src/wc -m < mbc.txt
$ kcachegrind callgrind.out.10379 # switch to callee map
My reading of this output is:
* The transformation of the byte strings to a character stream
takes more than 50% of the CPU time. I find this extraordinary
slow, given that what this parsing does is essentially to combine
2 adjacent bytes in a word, according to an algorithmic formula
(no table lookup).
What each step does:
- rpl_mbtowc: Implements the gnulib workaround against
"In the C or POSIX locales, this function can return @code{(size_t) -1}
and set @code{errno} to @code{EILSEQ}"
- mbrtowc: Adapt the invocation conventions of mbrtowc to the invocation
conventions of __gconv_transform_*.
- __gconv_transform_utf8_internal: This is the transformation UTF-8 ->
UCS-4.
It is slow because the __gconv_transform_* functions are optimized to do
long runs of characters all at once (i.e. for iconv() and mbstowcs).
However,
what 'wc' and the coreutils in general do is to convert one character, check
status and update application logic, then convert another character, check
status and update application logic again, etc.
There would be two ways to make 'wc' more performant:
- Change the 'wc' program to transform buffers at once. The problem here
is that it comes with degradation of error-handling logic (ability
to precisely diagnose errors and continue appropriately) and complicates
the code, making it less maintainable.
- Change glibc to add an optimized 'mbrtwoc' function for each encoding
(or at least for the most frequently used encodings: the built-in and
8-bit ones).
I estimate that this optimization would make 60% of the mbrtwoc times
go away, thus speeding up 'wc' by 30%.
* The other operations (print, space, and width, for each character)
are reasonably optimized in glibc.
Bruno
[1] http://www.pixelbeat.org/programming/profiling/
![]() callgrind.out.10379.png
callgrind.out.10379.png
Description: application/kcachegrind
{kind=link}