jimmylao commented on issue #49: URL: https://github.com/apache/incubator-bluemarlin/issues/49#issuecomment-1048165884
@klonikar 1. What is context in the red cells in decoder? Is it used as input to next timestep? As shown in the 1st figure, the context of the red cells are from the attention layer which will be concatenated with the state output of current cell, then used as input to next cell. 2. Can you explain split of train_window data into train_skip_first, data used for training and final eval? How is the data in the final 10 days of 82 (12+60+10) days used in training? Is it used to update regularization params or weights in backprop?  As shown in the figure above, the data is typical split into configurable 4 parts, i.e. train_skip_first, train_window, validate and back_offset. In your case, - train_skip_first = 12 - train_window = 60 - predict (validate) = 10 - back_offiset = 0 "Is it used to update regularization params or weights in backprop?" - I don't understand the meaning of this question. The data is used for training a model or leverage trained model for prediction, in training stage, they are used to compute gradient in each batch/epoch which can further be used in backprop. 3. What are the features used at time step of 82 days? How is ts_n in trainready table used as input? I thought that's the output. 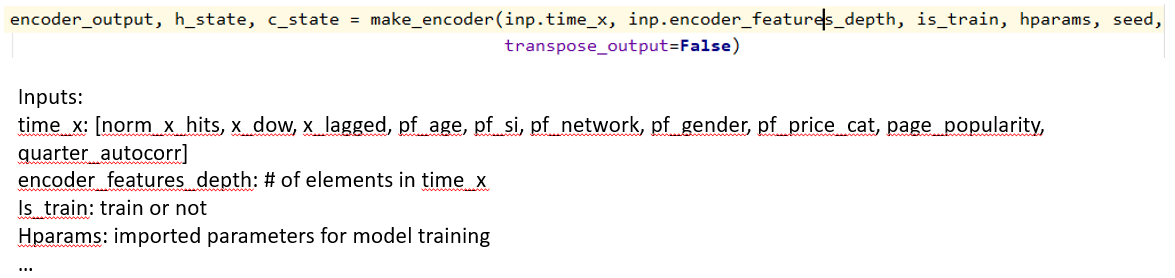 As shown in the figure above, time_x is the major input data needed to train the model, it has multiple components. trainready table is the output of preprocessing and input for model training. There's a program called tfrecord_reader.py to convert trainready data format to model training data format. 4. Attention: Explain attention heads = 10, and attention depth = 60 These parameters are used when the "attention" option is turned on. The purpose of attention is to find the correlation among different time step. The attention method used by this model used the attention concept not the implementation, i.e. it uses convolution to model the correlation among different time steps which is faster than typical attention implementation, however, such approximation does not generate better performance. Domain knowledge based attention features, such as: monthly or quarterly correlation, are added in the model to fill the gap and was claimed to work better than using the attention implementation in the model. 5. Can you give mathematical description of the model? I'll add some math equation later. I suggest you read through the code and run a couple of sample data first. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}