Hi, Russell. This is okay for a starting point but it is a bit vague. Could you perhaps flesh out the plan and make it more comprehensive?
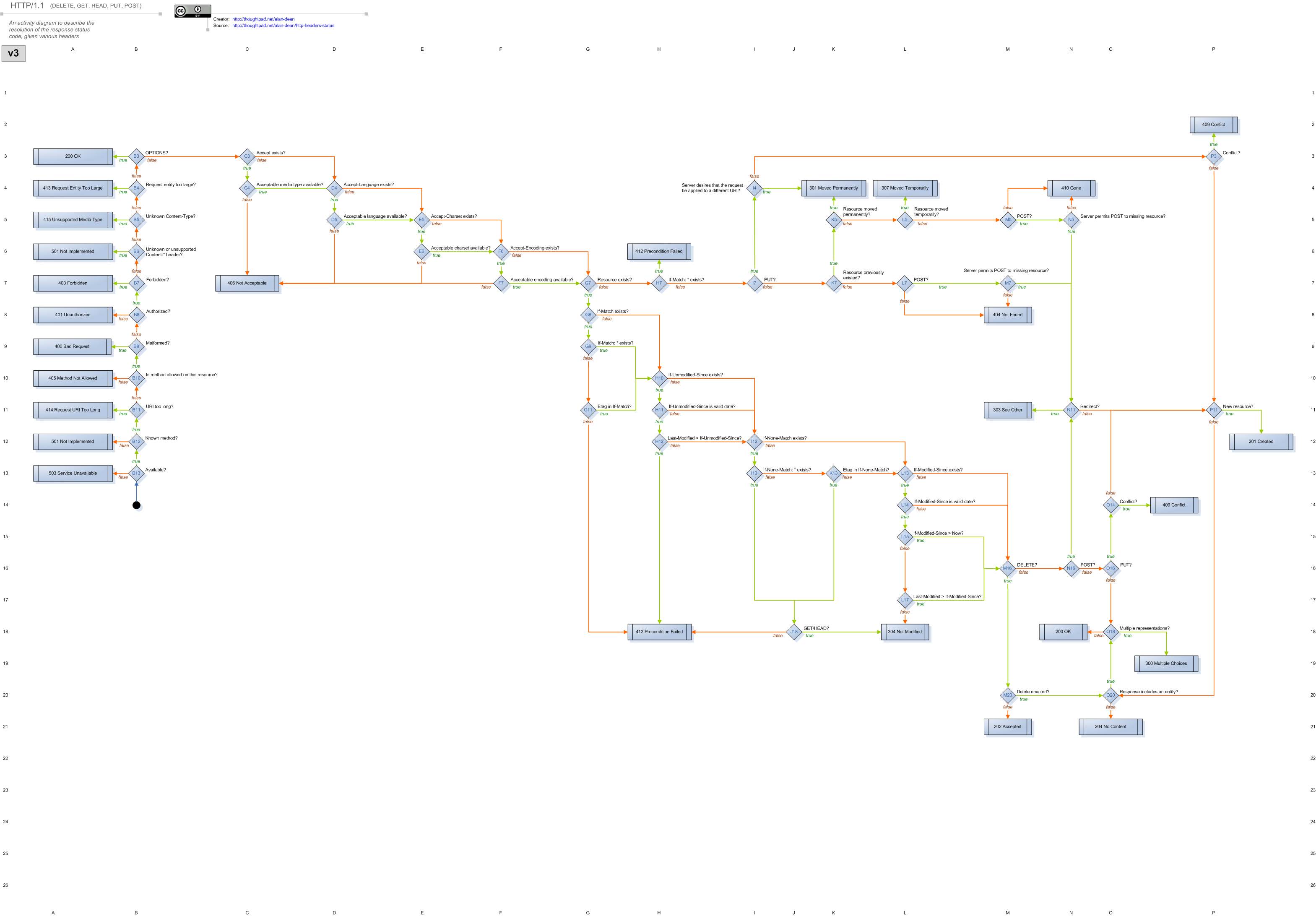
^^ That is a joke! Seriously, thank you very much for this analysis and plan. This is very exciting! (Not least because the http codebase is the part I know best and I can get excited about.) One quick question that I don't see from your writeup: What version of CouchDB are you thinking of targeting? 2.0? 2.1? 3.0? Is this completely an internal change, or does it affect users? For me, I am not so interested in an internal rewrite with zero advantage (besides "it's cleaner"), however I am am very interested to use the rewrite for a better opportunity to explore plugin opportunities or other extensibility features. On Mon, Aug 18, 2014 at 1:41 AM, Russell Branca <[email protected]> wrote: > # Rewriting the CouchDB HTTP Layer > > With the light at the end of tunnel on the BigCouch merge, I thought > it was time to get the conversation going on cleaning up the current > HTTP stack duality. We've got a good opportunity to do some major > cleanup, remove duplication, and really start more clearly separating > the various components of CouchDB. > > > ## Primary objectives > > * Consolidate down to one HTTP layer > * Isolate HTTP functionality > * Separate HTTP server from HTTP resources > * Easy plugin integration > * Build clustered/local API > > > ### Consolidate down to one HTTP layer > > We currently have two HTTP layers, `couch_httpd` and `chttpd`. This > was a useful construct when BigCouch was a separate application where > isolating the clustered layer from the local layer was necessary, and > quite useful. > > This is no longer the case, and we can significantly reduce code > duplication by consolidating down to one http layer. There are a > number of places in the two apps where the code is nearly identical, > except one calls out to `fabric` and the other calls out for > `couch_*`. For instance, compare `couch_httpd_db:couch_doc_open/4` [1] > with `chttpd_db:couch_doc_open/4` [2]. These are completely identical > aside from whether it goes through the clustered layer, `fabric`, or > through the local layer `couch_db`. > > There are plenty of other places with similar duplication. This is > obviously ripe with opportunity to refactor and introduce some higher > level abstractions to make the HTTP layer function independently of the > document/database level APIs. > > > ### Isolate HTTP functionality > > I don't think `couch_doc_open/4` has any business existing in > the HTTP layer, we should move all non HTTP logic out. IMO the HTTP > layer should only concern itself with: > > 1. Receiving the HTTP requests > 2. Extracting out the request data into a standard data structure > 3. Dispatch requests to the appropriate internal APIs > 4. Forward the response > > Anything that doesn't fit into those four steps should be ripped out > and moved elsewhere. For instance, the primary logic for determining the > database redundancy and shard values is done in `chttpd_db` [3]. I > would greatly prefer to see this logic in a database API. > > The more we can isolate HTTP logic from database logic the > better. Once they are fully decoupled, then the HTTP layer is merely > one particular client interface on top of the core database. We also > get all the benefits of isolation for testing and what not. > > Along these lines, I think we greatly overuse the #http{} record for > passing around request data, and instead you extract the body, and > then combine all of the user supplied headers and query string params > into a standard options list. This we can we completely separate > making database requests from the representation of the client > request. > > > ### Separate HTTP server from HTTP resources. > > I think everything I've said so far is pretty clear cut in terms of > it's _the_ logical thing to do, but separating the HTTP server from > the HTTP endpoints is less clearly defined. However, we do have > precedence for this and there are a number of solid benefits. > > First, let me explain what I mean here. There are two pieces to an > HTTP stack, first there's the core HTTP engine that handles receiving > and responding to requests and other things along those lines, and > second there's the places where you supply your business logic and > figure what content to send to the user. > > CouchDB has a handful of places using this aproach, where instead of > defining all the logic in the HTTP stack directly, we have auxilary > modules defined within the appropriate applications that specify how > any HTTP requests for that application are handled. A good clean > example of this approach is `couch_mrview_http` [4]. > > > ### Easy plugin integration > > One big advantage of the above separation of HTTP resources is that it > provides a standard way of plugins hooking in new HTTP endpoints. The > more we can treat the "core" CouchDB applications as plugins, the more > easily it is to isolate and replace various parts of the stack. > > > ### Build clustered/local API > > The above example of `couch_doc_open/4` is a clear cut case where > we want to abstract the process of loading a document. Not all places > are as easily abstractable, but this is a great example of why I think > we should have a standard API on top of clustered and local layers, > where deciding which to use is based on a local/clustered flag, or > some other heuristic. > > I've been toying around with the idea of making a request object of > some sort, is something like `couch_req:make(ReqBody, ReqOptions)` > that you can then pass to `couch_doc_api` or some such, but I don't > have any strong opinions on this. > > > ## Where I've gotten so far: chttpd2, a proof of concept > > I've hacked out an experimental WebMachine [5] based rewrite of the > HTTP stack called `chttpd2` [6]. This PoC follows the same ideas I've > outlined above, so I'll run back through the previous outlined items > and explain how `chttpd2` handles it. > > > ### Consolidate down to one HTTP layer > > Right now I'm not doing anything special here, I still think building > an API layer that handles deciding whether to make a clustered or > local request is the proper approach, so I've not included any logic > in the HTTP stack for doing so. > > > ### Isolate HTTP functionality > > I've got a solid separation of functionality in `chttpd2`. If you > notice the current codebase in [6], there is zero logic for actually > handling any particular CouchDB requests. Rather those are self > contained within the appropriate sub applications. I've started this > for `couchdb-couch` [7] and `couchdb-config` [8]. Here's a simple > example of the new welcome resource [9]. > > As you can see, there is zero database logic in the welcome request > module. In fact, I started moving all the random logic in the current > HTTP layer to a temporary module I'm calling `couch_api` [10]. As you > can see from that module, it removes all the logic that was previously > nested in `couch_httpd_misc_handlers` [11]. More complicated examples > for creating a database and viewing database info are in [12], and an > all dbs example is in [13]. Also I've done similar things for > `couchdb-couch` as mentioned above in [8]. > > > ### Easy plugin integration > > As I mentioned above, by making it easy to plugin in new HTTP > endpoints, we also make it easier for plugins to do the same. On that > front I've made it so each application can optionally declare a > `couch_dispatch` function describing what endpoints it can handle, and > then `chttpd2` will go and find all of those to figure out how to > dispatch requests [14]. And for example, here's how the > `couchdb-couch` endpoints are declared [15]. > > > ### Build clustered/local API > > I have not started on this front, and have only built these endpoints > for interacting with the clustered layer for simplicity as this is > just a proof of concept I hacked together. However, as I mentioned > above I've started moving all the logic out of the HTTP layer into > more appropriate places. I've made similar changes to `couch-config` > by moving all of the logic from [16] into the `couch-config` > application itself. > > > ### Why WebMachine? > > I find WebMachine [5] to be one of the more interesting HTTP stacks for > building webapps. In particular I like how they have a specific flow > chart [17] and coordinate point corresponds to a particular definition > of the `webmachine_decision_core:decision/1` function. > > That said I think Cowboy [19] has more momentum and might be a better > long term project to tie ourselves too. > > Also, if we decide to go the WebMachine route, we'll need to > restructure a fair bit of the current HTTP layer, making a number of > breaking changes. I'm a strong -1 for coercing WebMachine into the > current haphazard CouchDB API. WebMachine is very opinionated on how > you structure your API (for good reason!) and I think going against > that is a mistake. > > So if we wanted to just do a drop in replacement of the current > CouchDB API, then Cowboy is the way to go. Although one of these days > we should clean up the HTTP API. > > > # Conclusion > > I hope this can start a good discussion on a game plan for the HTTP > layer. Like I said, this is a proof of concept that I hacked out, so > I'm not attached to the code or the use of WebMachine, but I do think > it's a good representation of the ideas outlined above. > > Looking forward to hearing your thoughts and comments! > > > > #### Footnotes > > [1] > https://github.com/apache/couchdb-couch/blob/master/src/couch_httpd_db.erl#L805-L823 > > [2] > https://github.com/apache/couchdb-chttpd/blob/master/src/chttpd_db.erl#L886-L904 > > [3] > https://github.com/apache/couchdb-chttpd/blob/master/src/chttpd_db.erl#L203-L205 > > [4] > https://github.com/apache/couchdb-couch-mrview/blob/master/src/couch_mrview_http.erl > > > [5] https://github.com/basho/webmachine > > [6] https://github.com/chewbranca/chttpd2/tree/initial-branch > > [7] > https://github.com/apache/couchdb-couch/tree/2073-feature-webmachine-http-engine > > [8] > https://github.com/apache/couchdb-config/tree/2073-feature-webmachine-http-engine > > [9] > https://github.com/apache/couchdb-couch/blob/2073-feature-webmachine-http-engine/src/couch_httpr_welcome.erl > > [10] > > https://github.com/apache/couchdb-couch/blob/2073-feature-webmachine-http-engine/src/couch_api.erl > > [11] > https://github.com/apache/couchdb-couch/blob/master/src/couch_httpd_misc_handlers.erl#L32-L45 > > [12] > https://github.com/apache/couchdb-couch/blob/2073-feature-webmachine-http-engine/src/couch_httpr_db.erl > > [13] > https://github.com/apache/couchdb-couch/blob/2073-feature-webmachine-http-engine/src/couch_httpr_dbs.erl > > [14] > https://github.com/chewbranca/chttpd2/blob/initial-branch/src/chttpd2_config.erl#L26-L33 > > [15] > https://github.com/apache/couchdb-couch/blob/2073-feature-webmachine-http-engine/src/couch.erl#L68-L73 > > [16] > https://github.com/apache/couchdb-couch/blob/master/src/couch_httpd_misc_handlers.erl#L155-L249 > > > [17] > https://raw.githubusercontent.com/basho/webmachine/develop/docs/http-headers-status-v3.png > > [18] > https://github.com/basho/webmachine/blob/develop/src/webmachine_decision_core.erl#L158-L595 > > [19] https://github.com/ninenines/cowboy > > > P.S. I've decided to stop using gists.github.com for posting content, > as I can never find my posts again and the comments there are a black > hole. I've instead posted this at: > http://www.chewbranca.com/tech/2014/08/17/rewriting-the-couchdb-http-layer/ >
{kind=link}