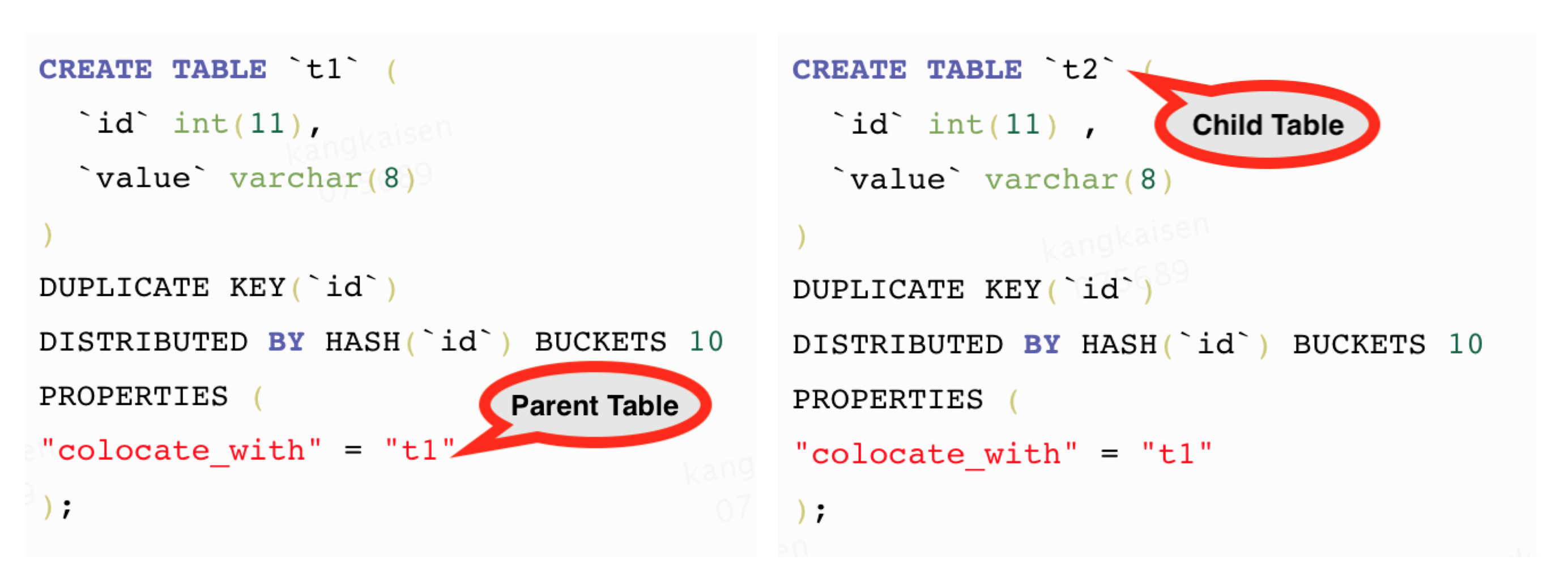
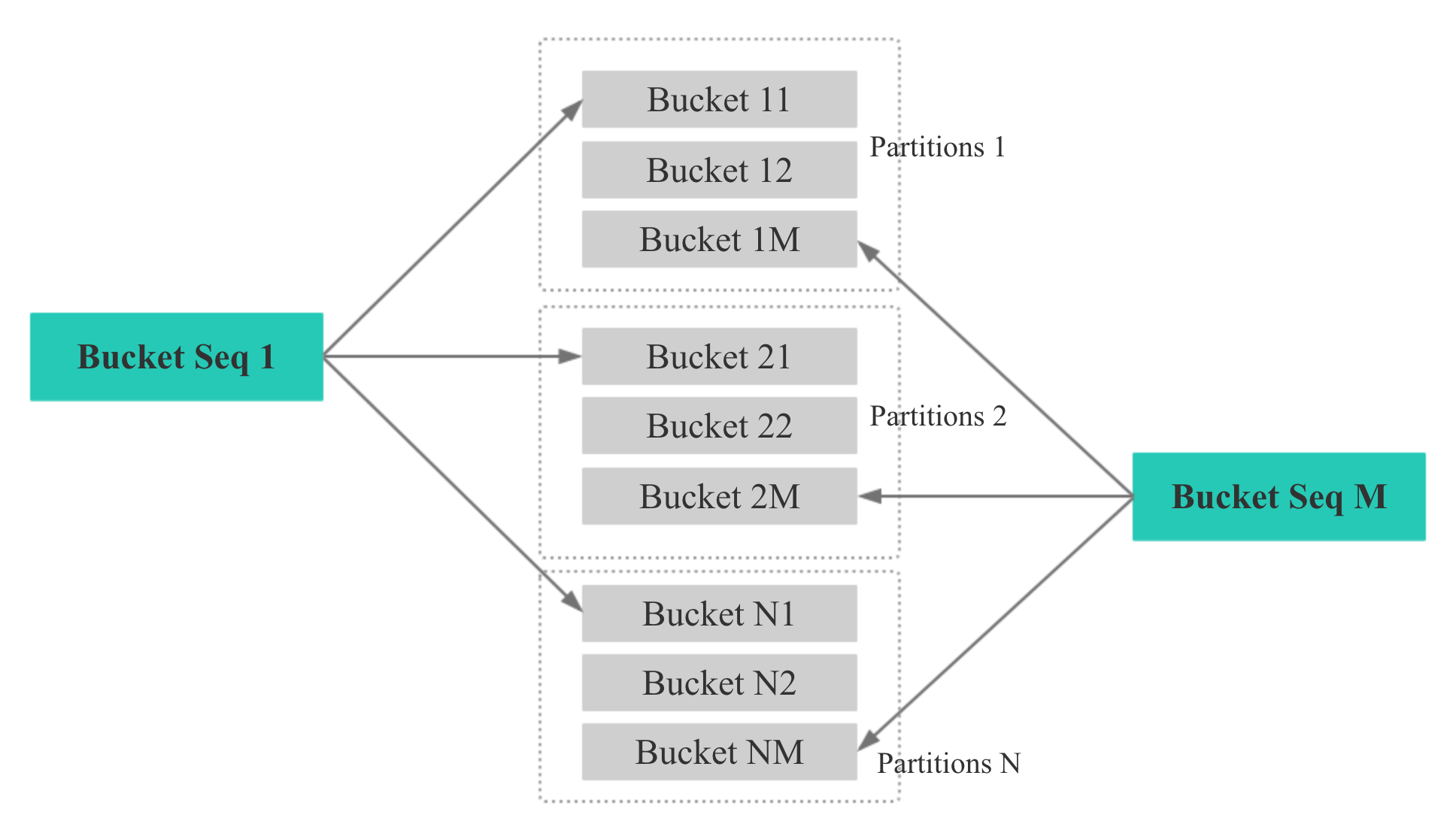
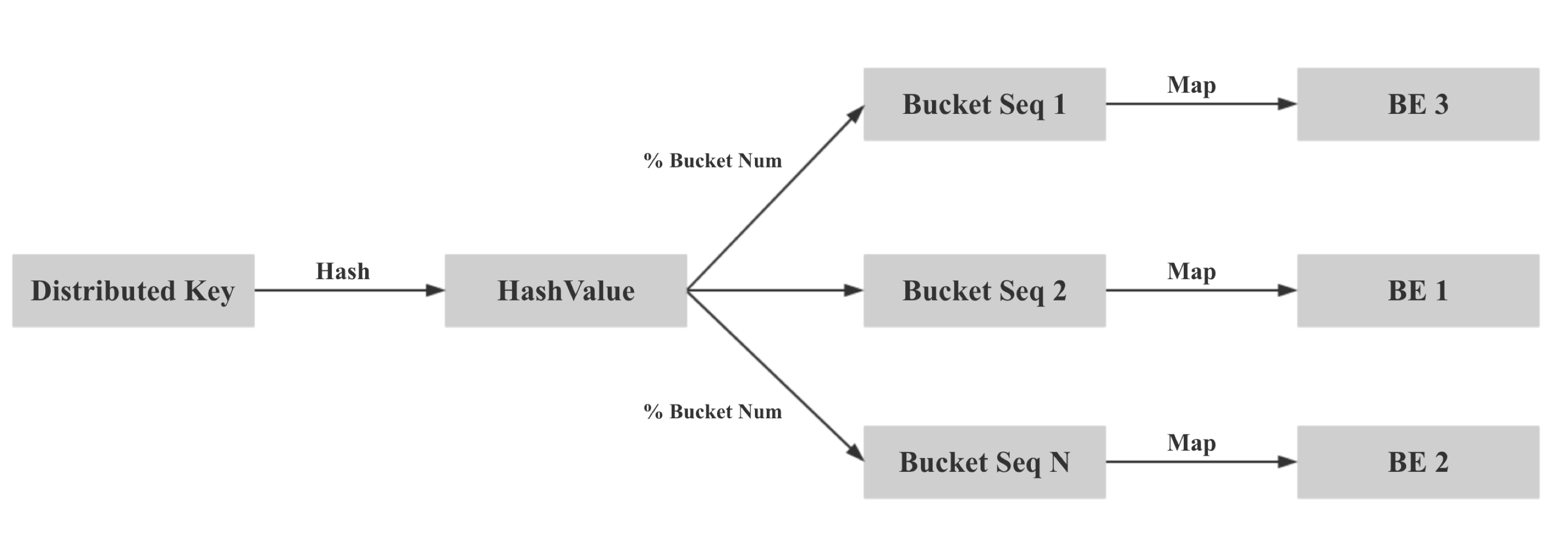
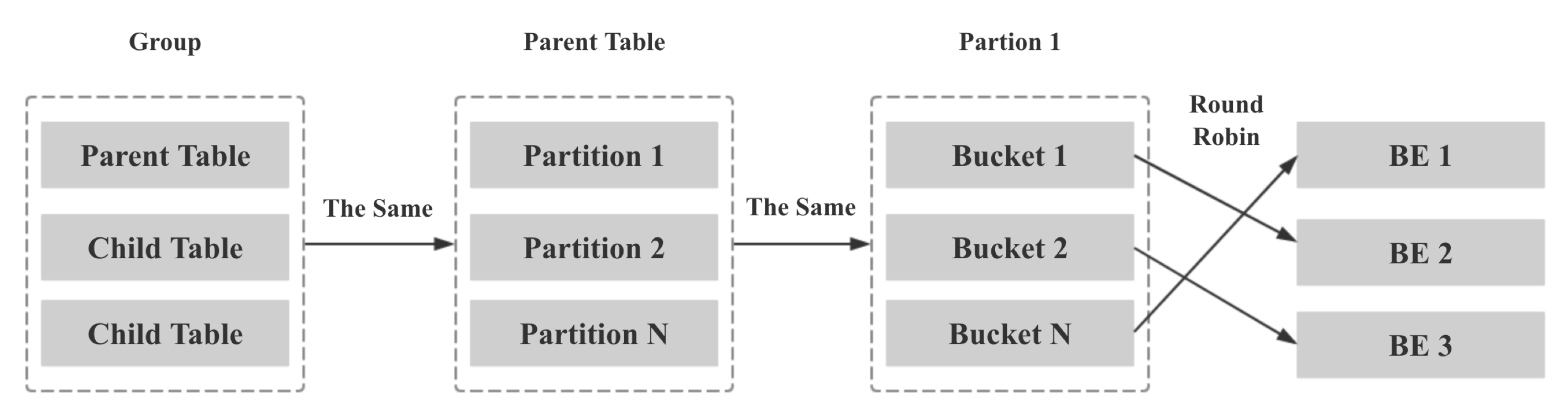
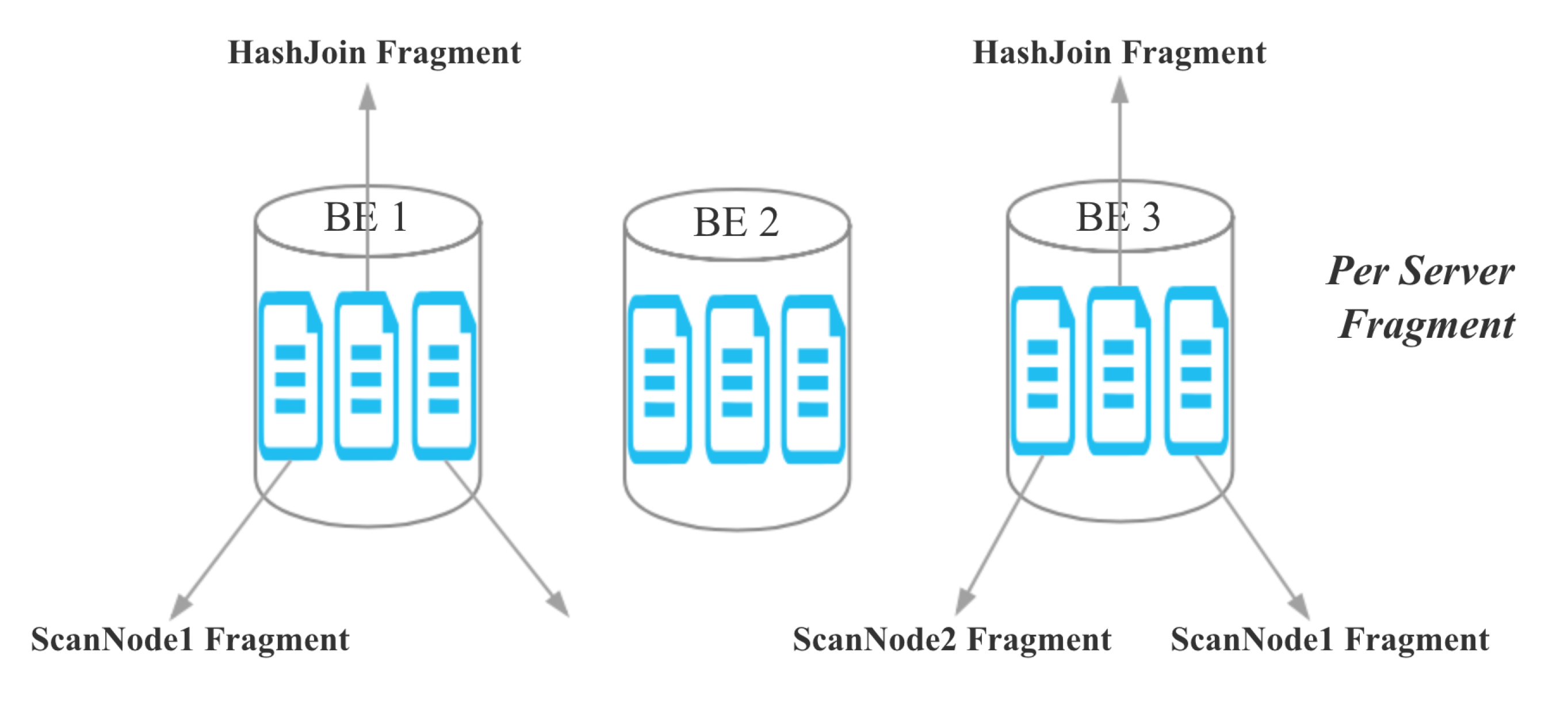
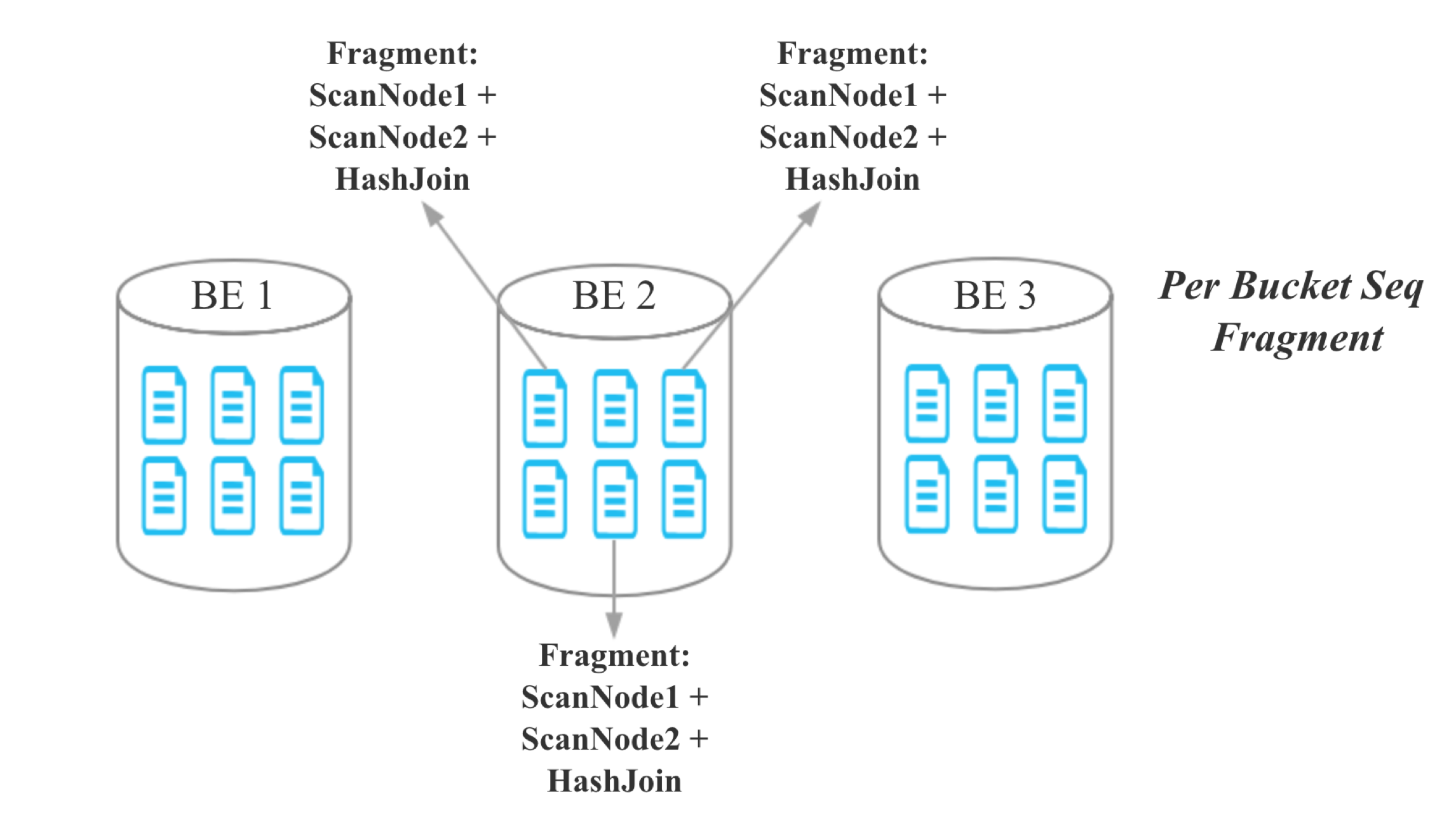
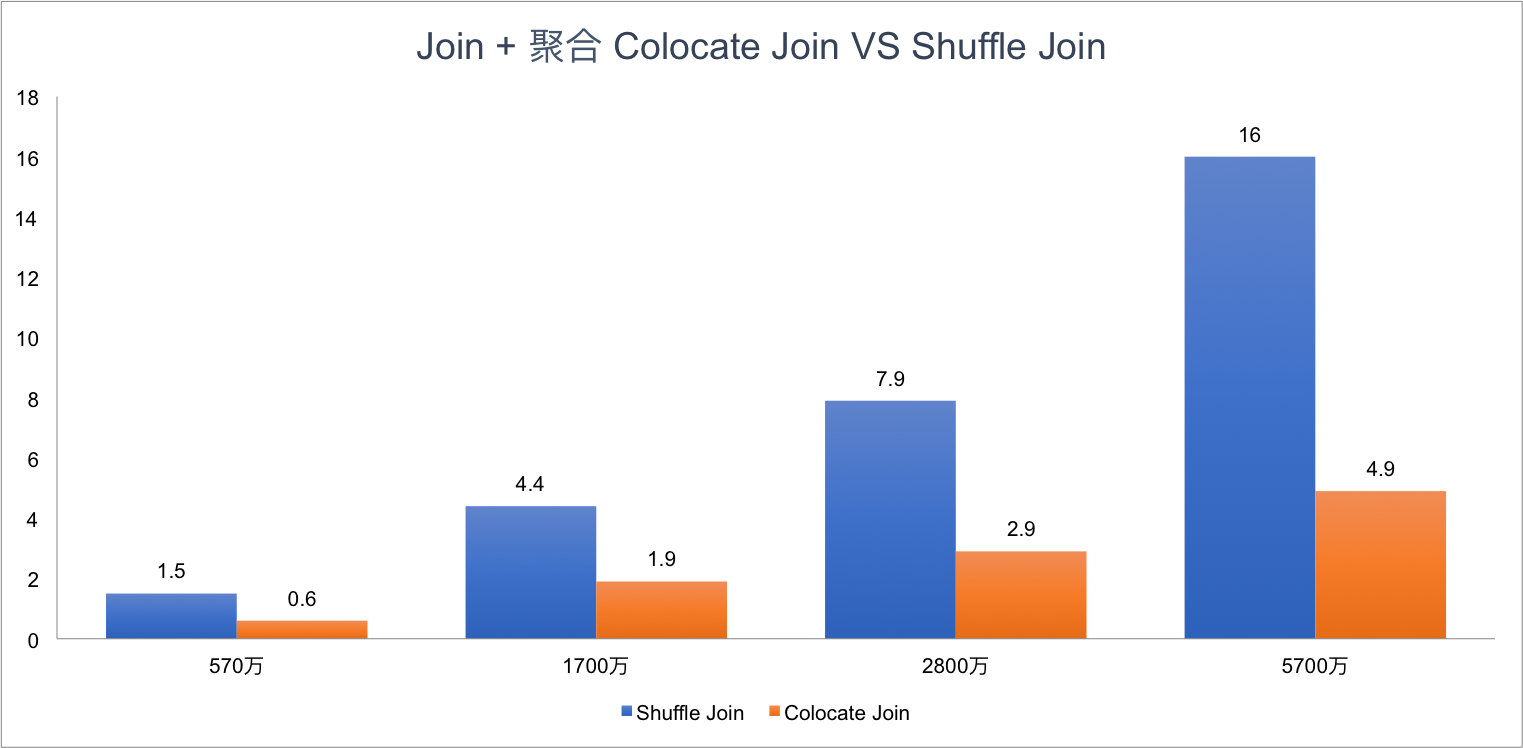
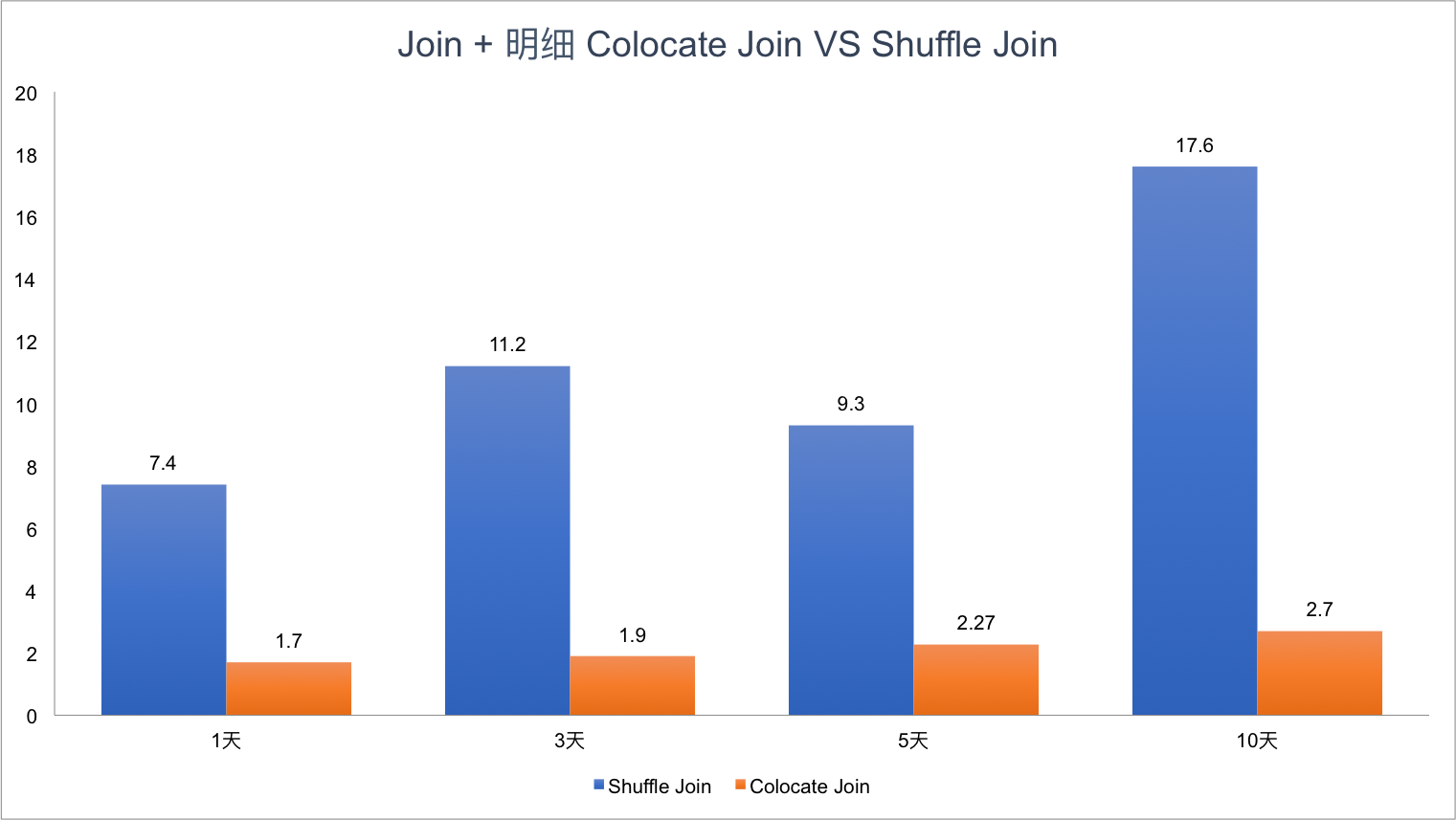
kangkaisen opened a new issue #245: Colocate Join URL: https://github.com/apache/incubator-doris/issues/245 ## What Colocate Join Colocate Join means two table are distributed by the columns being joined, then we can join them locally on each backend. ## Why Colocate Join 1. No Shuffle (no data movement) 2. More Concurrency (we can join on bucket level) ## How Colocate Join ### The key idea and challenge **Keep data locally in any case and any time for colocate tables.** For example: - keep data locally when data load into palo - keep data locally when query schedule - keep data locally when data balance ### Terminology define **1 Colocate Group** If some tables have the same "colocate_with" property, we think these tables belong to the same Colocate Group. In the following picture, table t1 and t2 have the same Colocate Group **2 Colocate Parent Table** In a Colocate Group, the value of "colocate_with" is Colocate Parent Table. In the following picture, table t1 is Colocate Parent Table. **3 Colocate Child Table** All tables in a Colocate Group are Colocate Child Table, except Colocate Parent Table. In the following picture, table t2 is Colocate Child Table. ![屏幕快照 2018-10-17 下午3.49.59.png-491.2kB][9] **4 Bucket Seq** If one table has N partitions, we call the Mth bucket in each partion is Bucket Seq M ![屏幕快照 2018-10-17 下午4.16.04.png-202.2kB][10] ### 1 Keep data locally when data load into palo The core idea is twice map, for colocate join tables, we keep the same Distributed Key map to the same bucket seq, and keep the same bucket seq map to the same BE. ![屏幕快照 2018-10-17 下午4.29.36.png-92kB][11] Firstly, we get the hash value for Distributed Key, and mod by bucket num. ![屏幕快照 2018-10-17 下午4.32.55.png-193kB][12] Secondly, How to keep the same bucket seq map to the same BE for all colocate join tables? the map rule for all colocate tables in a colocate group is same as colcoate parent table, all partitions of colcoate parent table is same as the first partition of colcoate parent table, for the first partition of colcoate parent table, we use the Round Dobin algorithm choose BE for buckets. ![屏幕快照 2018-10-17 下午4.42.17.png-249.2kB][13] **Finally, we can ensure all buckets that have the same bucket seq in a colocate group load into the same BE.** Note: **If a load job stay in QUORUM_FINISHED state longer than `colocate_quorum_load_job_max_second`, we will mark the colocate group balancing and not use Clone to finish the load job** (This case shoule be rare, I never found this case in our prod env) ### 2 Colocate join query plan For the Colocate Hash join, **we remove the Exchange node, the OlapScanNode will be the HashJoinNode child Directly**. ![屏幕快照 2018-10-17 下午4.44.06.png-643.7kB][14] ### 3 Colocate join query schedule The schedule goal: the scan of the bucket that have the same bucket seq for all ScanNode in a colocate join should schedule to the same BE. The schedule strategy: **the bucket seqs of first ScanNode choose BE by random, the bucket seqs of subsequent ScanNode keep consistent with the first ScanNode**. ### 4 Colocate join at bucket seq level Currently, The Doris Hash join is server level. ![屏幕快照 2018-10-17 下午5.11.48.png-374.4kB][15] For colocate join, we have kept the data data locally for all bucket seqs in a colocate groups, so we can join at bucket seq level. ![屏幕快照 2018-10-17 下午5.16.06.png-407kB][16] ### 5 Colocate join metadata maintenance we need to maintain the following metadata and indexs: ![屏幕快照 2018-10-17 下午5.20.45.png-145.4kB][17] - in code, the colocate group id is the colocate parent table id - group2BackendsPerBucketSeq is keep the map from bucket seqs in a colocate group to BE - **in order to support balance and keep the metadata consistent, these metadata need to be persistent** ### 6 How to decide a query can colocate join 1. The join tables must be colocate 2. The colocate group must be stable (not balancing) 3. The eqJoinConjuncts must contain the distribution columns ### 7 Colocate join support balance The core idea is **adding a new daemon thread only do the balance for colocate tables**, and make `CloneChecker`, `DecommissionBackendJob`, `ReportHandler.addReplica` don't handle colocate tables. **We will balance colocate tables when backend remove, down, and add**. **We will balance all tablets in a colocate group at one time**, when balance start we will mark colocate group balancing, after balance done, we will mark colocate group stable. **When the colocate group is balancing, the colocate join will degrade into shuffle join or broadcast join.** When backend removed or long time down, we will do: 1. compute need delete BucketSeqs in the removedBackend 2. select clone replica BackendId for the new Replica 3. mark colocate group balancing 4. add a Supplement Job 5. update the backendsPerBucketSeq metadata When backend added, we will do: 1. compute the the number of bucket seqs need to move from the each old Backend and the number of bucket seqs need to move to the each new Backend 2. select the clone Backend for the new Replica 3. mark colocate group balancing 4. add a Migration Job 5. update the backendsPerBucketSeq metadata **When the clond job done and the colocate group is stable, we will delete the redundant replicas** ### 8 Others #### 8.1 Allow use change the colocate property ``` ALTER TABLE test.t2 set ("colocate_with"="t11"); ``` #### 8.2 Allow use disable colcoate join in session Add a session variable `disable_colocate_join`, the default value is false. #### 8.3 Reduce the coloctae join PlanFragment instance memory_limit Bacause the coloctae join has more concurrency, in each coloctae join PlanFragment instance, we will scan fewer data and the Hash join node will need fewer memory (the hashtable will be smaller). We should reducer the the coloctae join PlanFragment instance memory_limit. we Add a config `query_colocate_join_memory_limit_penalty_factor`, the default value is 8. the new memory limit = exec_mem_limit / min (query_colocate_join_memory_limit_penalty_factor, instance_num) ## The limit for current colocate join 1. Colocate tables must be OLAP table (the reason is obvious) 2. Colocate tables must have the same bucket num (the reason is obvious) 3. Colocate tables must have the same replication num (in order to code easily) 4. Colocate table distribution columns must have the same data type (the data type will effect the hash result) ## Colocate Join VS Shuffle Join **Test Table:** - Table A: 10 partitions, each partition has 5.7 millions rows - Table B: 10 partitions, each partition has 5.7 millions rows - Table C: 10 partitions, each partition has 5.7 millions rows **Cluser Info:** 4 BEs, each BE is Physical Machine and has 24CPU, 96MEM. **Test SQL:** SQL1: ``` select count(*) FROM A t1 INNER JOIN [shuffle] B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN [shuffle] C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days); ``` SQL2: ``` select t1.dt, t1.id, t1.name, t1.second_id,t1.second_name, t5.id, t5.weight_time,t5.list, t6.ord_id, t6._id FROM A t1 INNER JOIN B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days) limit 10000; ``` **Test Result for SQL1:** ![join1.png-140.7kB][18] **Test Result for SQL2:** ![join3.png-174.1kB][19] [9]: http://static.zybuluo.com/kangkaisen/qspf8wvz2otzjeaapmpctegd/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%883.49.59.png [10]: http://static.zybuluo.com/kangkaisen/xdtpxecmkpqmwld27ue77xyi/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%884.16.04.png [11]: http://static.zybuluo.com/kangkaisen/aqin0s9ivn9reb6yvg7zk9si/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%884.29.36.png [12]: http://static.zybuluo.com/kangkaisen/5pih8trh6lif8yqbg4sd10js/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%884.32.55.png [13]: http://static.zybuluo.com/kangkaisen/gip6kbbrdedy3vrhqwrtd13u/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%884.42.17.png [14]: http://static.zybuluo.com/kangkaisen/2on70kuajufmy06uwwwz0dva/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%884.44.06.png [15]: http://static.zybuluo.com/kangkaisen/922wjkbbimv3z1ndgxm7cdpk/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%885.11.48.png [16]: http://static.zybuluo.com/kangkaisen/b4bseudgdxpgix3kvwbbgacq/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%885.16.06.png [17]: http://static.zybuluo.com/kangkaisen/0xzo2whr7giba9lt8lxcyj1o/%E5%B1%8F%E5%B9%95%E5%BF%AB%E7%85%A7%202018-10-17%20%E4%B8%8B%E5%8D%885.20.45.png [18]: http://static.zybuluo.com/kangkaisen/c42utzd11dn4zf605qq2chbz/join1.png [19]: http://static.zybuluo.com/kangkaisen/0fg89hwa5v9enuldiw7elc84/join3.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]