CarusoGuillaume opened a new issue, #2595: URL: https://github.com/apache/drill/issues/2595
**Describe the bug** We are using Apache Drill to add ANSI SQL capabilities to cassandra, but when using the '>', '<' or 'IN' operators when filtering data, the query plan switch from a CassandraFilter to a regular Filter, meaning all the cassandra table data is scanned, fetched, then filtered, which is not the expected behavior, as the Apache Calcite plugin supports those operators. This results in very slow queries, and high resources consumptions. **Screenshots** *(boitier_id, libelle, unite and periode are keys)* *Expected behavior (using a CassandraFilter)*   *Unexpected behavior (When using lt, gt operator)*   *Possible solution to get a correct behavior, but not completely, as the whole dataset for (76, '3dProd_C1','W') is loaded insted of just the portion which we would like to use* 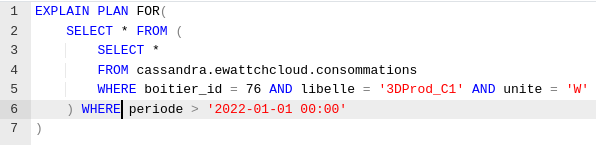  **Expected behavior** The Query should use a CassandraFilter in order to fetch data efficiently, even when using '>', '<' operators, and not use a normal filter, which requires to fetch all the data from the queried table. Should our question not belong here, feel free to remove it, but please point us to where we could ask it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}