Are you sure you can't use trunk? Swapping in PForDelta as a codec is much easier and we are wanting to do that, anyway (as a hybrid codec w/ Pulsing as well), before releasing 4.0 :)
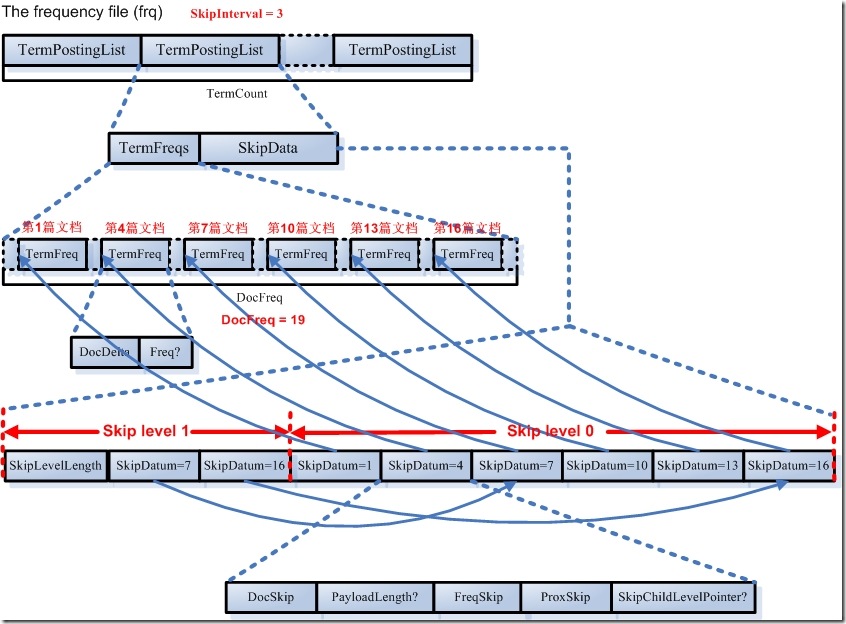
Partial decode of PForDelta is challenging I think... because the exceptions are a linked list, you have to walk the exceptions up front? That's a nice idea to interleave the encoding of 128 docDeltas then 128 docFreqs... in trunk's Sep codec we currently put them in separate files. Mike On Wed, Nov 24, 2010 at 5:16 AM, Li Li <[email protected]> wrote: > hi all > I want to improve our search engine throughput without any help of > hardward improvement. My task now is optimizing index format. And we > have some experience on modifying index format by reading codes of > lucene and write a little codes such as implementing bitmap for high > frequent terms, top positions infos with frq files and modifiable fdt > style fields to meet our need. > I want to integrate PForDelta into index but can't waiting for > lucene4's release date and we can not migrate lucene 2.9/solr 1.4 to > new version in svn trunk . > the index format in lucene 2.9.3 is > http://lucene.apache.org/java/2_9_3/fileformats.html#Frequencies > > FreqFile (.frq) --> <TermFreqs, SkipData> TermCount > TermFreqs --> <TermFreq> DocFreq > TermFreq --> DocDelta[, Freq?] > SkipData --> <<SkipLevelLength, SkipLevel> NumSkipLevels-1, > SkipLevel> <SkipDatum> > SkipLevel --> <SkipDatum> DocFreq/(SkipInterval^(Level + 1)) > SkipDatum --> DocSkip,PayloadLength?,FreqSkip,ProxSkip,SkipChildLevelPointer? > DocDelta,Freq,DocSkip,PayloadLength,FreqSkip,ProxSkip --> VInt > SkipChildLevelPointer --> VLong > > which can be summarized in this image > http://hi.csdn.net/attachment/201002/2/3634917_1265115903L6FU.jpg > > I just want to modify compression algorithm from VInt to PForDelta. > But PForDelta is batching method that compress/decompress an integer > array while VInt decode/encode one by one. > The main implementation of TermDocs is SegmentTermDocs. > And some important methods are > void seek(TermInfo ti, Term term) > public int read(final int[] docs, final int[] freqs) > public boolean next() > public boolean skipTo(int target) > > There are 2 major type of search: disjunction and conjuction > for conjuction, we decode all the docList and frequency so public > int read(final int[] docs, final int[] freqs) is needed > for disjuction, in ConjunctionScorer doNext function does the major job > private int doNext() throws IOException { > int first = 0; > int doc = scorers[scorers.length - 1].docID(); > Scorer firstScorer; > while ((firstScorer = scorers[first]).docID() < doc) { > doc = firstScorer.advance(doc); > first = first == scorers.length - 1 ? 0 : first + 1; > } > return doc; > } > which finally call TermScorer.advance() which call > boolean result = termDocs.skipTo(target); > e.g. term1's docList 1 10 100 > term2's docList 1 2 3 .. 100 > then with skipList, we don't need decode all the docIds of term2 > > That's my understanding of lucene 2.9.3's implementation > > Now I need integrating PForDelta > My plan is as follows: > 1 if df<128 stay VINT not changed return > 2 compress 128 ints into groups. docList and tf are stored separately > e.g. docList 1--128, tf 1--128 | docList 129-256,tf 129-256 | ... > 3 skipList's leaf point to group start position (in 2.9.3 leaf of > skipList point to the position of exact position of this document) > 4 for disjunction query, we decode the whole group for docID and tf > and cache the int array of this group > for conjuction query, we also decode the whole group and cache > the group result of docID and tf(maybe tf is not needed because it > don't occur in other terms, but for now we don't want to modify score > algorithm) > > Comparision with VINT > for disjunction query, both need decode all the docIDs and tfs. So > PForDelta will be faster. > for conjunction query,it's hard to analyze > e.g. skipInterval is 1024 if we skipTo 10 and then 1100 then VINT > only need decode 10 docIDs while PForDelta need decode the 128 docIDs > e.g. skipInteval is 1024 if we skipTo 10 and then 100. VINT need > decode 100 docIDs while PForDelta need also decode 128 docIDs > I think PForDelta also support parial decode but don't know it's > speed is fast or slow comparing with VINT. > > So the group size is critical,if it's too large, conjuction query > may become slow. if it's too small, disjuction query may become slow. > I found 128 in paper Performance of Compressed Inverted List Caching > in Search Engines > any other good method to improve both disjunction and conjuction > query? Or any suggestion for me ? > Thank you ! > > --------------------------------------------------------------------- > To unsubscribe, e-mail: [email protected] > For additional commands, e-mail: [email protected] > > --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}