HYY-yu opened a new issue #736:
URL: https://github.com/apache/rocketmq-client-go/issues/736
Hello, I found that there may be a problem with the retry strategy when we
use the default configuration of the Producer.
**BUG REPORT**
1. Please describe the issue you observed:
- What did you do (The steps to reproduce)?
frist we got a producer:
```golang
p, _ := rocketmq.NewProducer(
producer.WithNsResolver(primitive.NewPassthroughResolver([]string{"127.0.0.1:9876"})),
producer.WithRetry(3),
)
// do something with p
```
as we know, the producer has default configuration :
```
1. _PullNameServerInterval = 30 * time.Second
2. Selector: NewRoundRobinQueueSelector()
```
and we send some messages to Topic (test):
```golang
topic := "test"
for i := 0; i < 10; i++ {
msg := &primitive.Message{
Topic: topic,
Body: []byte("Hello RocketMQ Go Client! " +
strconv.Itoa(i)),
}
res, err := p.SendSync(context.Background(), msg)
if err != nil {
fmt.Printf("send message error: %s\n", err)
} else {
fmt.Printf("send message success: result=%s\n",
res.String())
}
}
```
In rocketmq server side, We have a 2m-2s-sync cluster, And the topic (test)
has 4 message queue.
[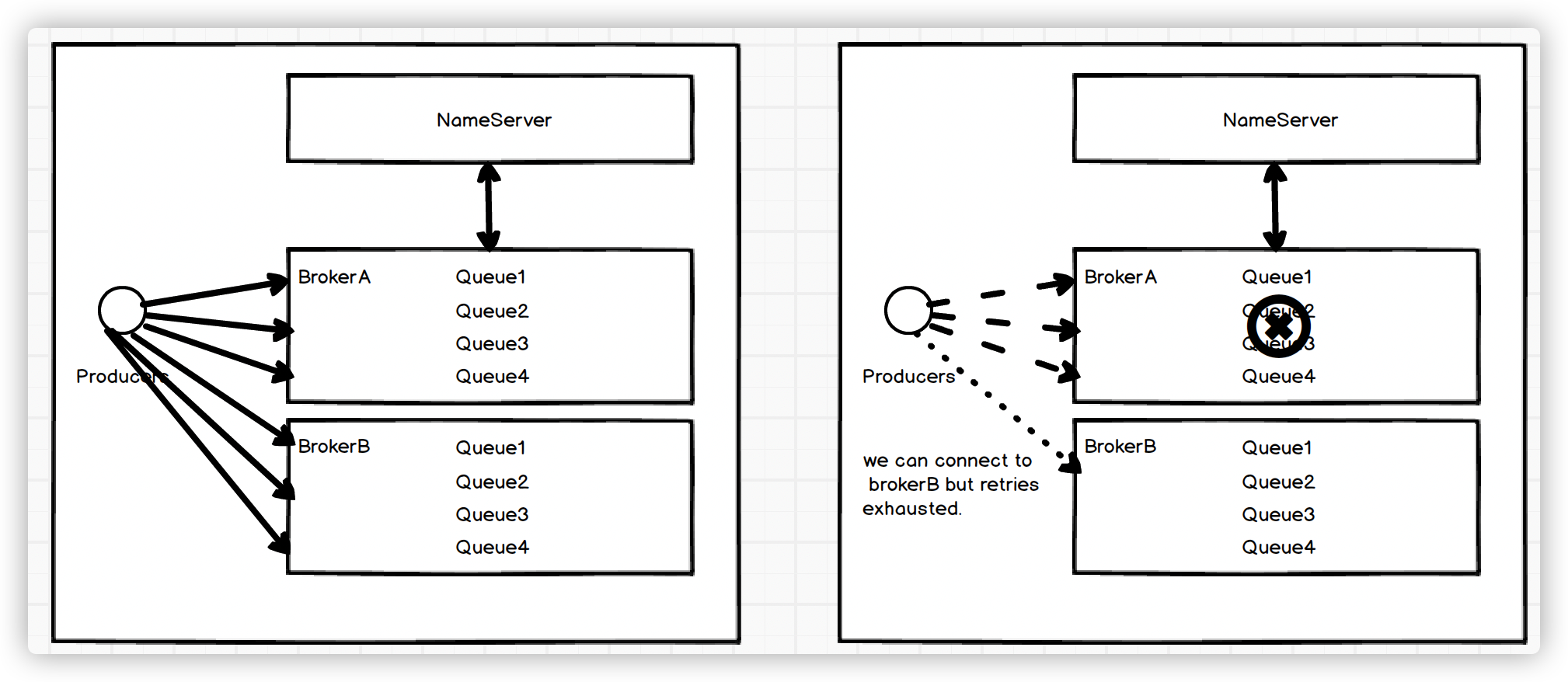](https://imgtu.com/i/5vky2F)
Producer will send messages to each MessageQueue through the RoundRobin
strategy, but if brokerA crashes, and the number of retry is less than the
number of queues. The message will fail to send and return a connection refused
error.
```golang
res, err := p.SendSync(context.Background(), msg)
if err != nil {
// returned the connection refused.
fmt.Printf("send message error: %s\n", err)
}
}
```
- What did you expect to see?
We should be able to handle this exception automatically instead of
returning an error.
Because many people use the default configuration, there are three retries
and at least four MessageQueues. If the broker crashes, they will receive a
large number of connection rejection errors within a maximum of 30 seconds (the
default refresh time).
3. Other information (e.g. detailed explanation, logs, related issues,
suggestions on how to fix, etc):
I think there are two ways to solve it:
1. Tell people that the number of retries must be greater than the number of
MessageQueue, but I think this is not a good idea.
2. I can implement a QueueSelector, it will traverse each Broker one by one,
access their queues in turn,
avoid retry strategies concentrated on a single broker, If feasible, I will
submit a PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}