alexott commented on pull request #513: URL: https://github.com/apache/incubator-sedona/pull/513#issuecomment-850197240
@jiayuasu The main problem is that if you add the library via UI, then it's loaded only after Spark is started, so all SparkExtensions already executed. That's an existing limitation of the platform. There is a workaround - copy all necessary jars to DBFS (the `/tmp/sedona-jars/` in my example), and use the [init scripts](https://docs.microsoft.com/en-us/azure/databricks/clusters/init-scripts) to copy jar files before Spark starts. Something like this: ```sh cp /dbfs/tmp/sedona-jars/*.jar /databricks/jars ``` After that, Spark extensions are picked up, and you can use SQL commands: 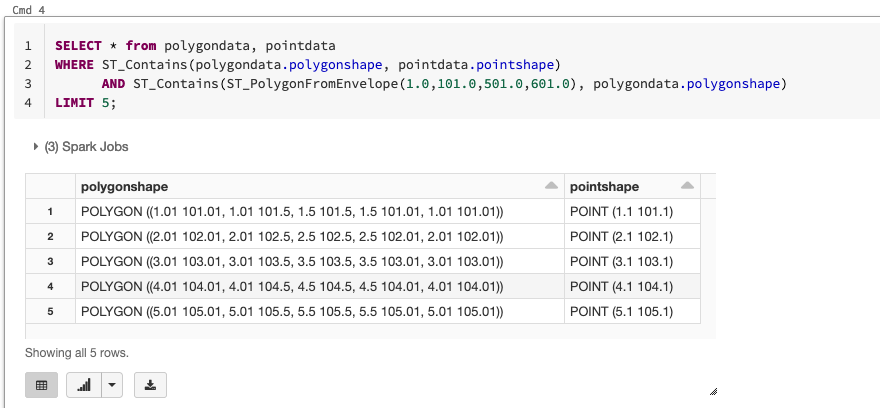 P.S. One problem is also that you need to pull many jars to make it working. I was using following `pom.xml` to generate a jar with dependencies and use it in init script: ```xml <project xmlns="http://maven.apache.org/POM/4.0.0"; xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"; xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd";> <modelVersion>4.0.0</modelVersion> <groupId>net.alexott.demos.spark</groupId> <artifactId>sedona-all_3.0_2.12</artifactId> <version>1.0.1-incubating</version> <packaging>jar</packaging> <name>sedona-all</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <sedona.version>1.0.1-incubating</sedona.version> <spark.version>3.0_2.12</spark.version> </properties> <dependencies> <dependency> <groupId>org.apache.sedona</groupId> <artifactId>sedona-viz-${spark.version}</artifactId> <version>${sedona.version}</version> </dependency> <dependency> <groupId>org.apache.sedona</groupId> <artifactId>sedona-python-adapter-${spark.version}</artifactId> <version>${sedona.version}</version> </dependency> <dependency> <groupId>org.datasyslab</groupId> <artifactId>geotools-wrapper</artifactId> <version>geotools-24.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>${java.version}</source> <target>${java.version}</target> <optimize>true</optimize> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.2.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project> ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}