Am 10.07.2013 16:54, schrieb Rupert Westenthaler:
Hi Sebastian
On Wed, Jul 10, 2013 at 2:02 PM, Sebastian Hellmann
<[email protected]> wrote:
1.
fise:extractedFrom should actually be nif:referenceContext if between
TextAnnotation and nif:Context and some other property, when between
EntityAnnotation and Context/ContentItem.
Ideally, we would model this with an OWL property chain. Together with
Giuseppe Rizzo and Raphael Troncy, we made a draft here, page 5 section 4.2:
http://events.linkeddata.org/ldow2012/papers/ldow2012-paper-02.pdf
This is a general feature: being able to query annotations on a ContentItem
level.
The idea in the paper was to have dc:relation and then infer
fise:extractedFrom as a shortcut for queries.
This would probably be an acceptable solution for Stanbol, or do you require
fise:extractedFrom to be materialized in RDF output.
Yes it is as Stanbol does not expect clients processing enhancement
results to support any kind of reasoning. All fise:Enhancement
instances need to define this property to allow users to simple get to
a list of all enhancements.
Ok, this might be relevant for Stanbol's use case, but not for NLP in
general. For POS tags in OLiA , NIF will probably just require these
minimal triples. oliaCategory is already "extra" for convenience.
<char=342,345> a nif:RFC5147String ;
nif:oliaLink penn:NNP ;
nif:oliaCategory olia:Noun ;
nif:oliaCategory olia:ProperNoun .
The amount of further triples deducable by a reasoner, would be far
greater, e.g.
penn:NNP a olia:Noun, olia:ProperNoun .
This would mean adding 106 classes for Penn, if each tag occurs once.
pellet classify http://olia.nlp2rdf.org/owl/penn-link.rdf
All in all this is quite a heavy commitment for NIF adoption and
difficult to standardize. What if there was slight misunterstanding and
"NNP" is actually an adjective? All non-active server projects will
provide the faulty triples.
As a guideline you could say, for standards "simplicity" drives adoption
and for tools "convenience" ;)
I created an issue here:
https://github.com/NLP2RDF/persistence.uni-leipzig.org/issues/3
2. issue is created here:
https://github.com/NLP2RDF/persistence.uni-leipzig.org/issues/4
It seems to me that we might be able to reuse an existing property, if an
entity uri is given. Instead of creating a new property, we can just define
one to be reused in the NIF specification:
"In case, enity uri is given rdfs:label should/must be used."
Is it the case, that you do require so many shortcut properties? Is it to
avoid joins in SPARQL queries?
I agree that those properties are not strictly required. The reason
for those properties is to make the enhancement results self
consistent.
The Stanbol Enhancer provides a RESTful service where the user sends
some text and receives a RDF graph. The intension is that the returned
graph contains all the necessary knowledge to process the result.
Omitting:
* fise:selected-text: would require the user to extract the anchor
text from the sent content. If the content was a PDF document this
could be a very complex task. Hence we include this information in the
graph
fise:selected-text is more like anchorOf, don't you mean
fise:selection-context, i.e. similar to nif:isString
* fise:entity-type: would require the user to obtain the RDF for the
referenced entity (e.g. making an other http lookup) maybe even to an
other host. If the server does not support CORS this might not be
successful within a browser. Hence we include those information in the
enhancement results. In addition users can configure EntityLinking to
use a other property as rdf:type as Entity Type. E.g. for Geonames one
could use the "geonames:featureCode" as type property as values of
this property do provide a better classification over the types of
linked Entities.
For the LOD2 Stack it is easy to load DBpedia into the triplestore, so
you would have all the information you need, presumably in the same
database.
Actually, we are working on having DBpedia Live for everyone. Any server
that gives out types not from http://live.dbpedia.org might be
considered outdated.
Again your use case is legit -> convenient tool vs. simple, versatile
standard
* fise:entity-label: principally the same as for fise:entity-type. But
in this case it also provide the actual label that was matched. For a
client it could be quite complex to determine the best matching label
for the "fise:selected-text" especially if the entity has a lot of
alternate labels, the matching process used some NLP stuff such as
lemma, stemming, the matching process supports tokens in the wrong
ordering (e.g. if the label notes "{given-name} {family-name}" but the
mention uses "{family-name} {given-name}") ...
So adding those additional triples seams to be a good tradeoff for a
RESTful service. In usage scenarios where one dose not need those
information one could simple remove those in an post processing
engine.
Yes, I agree, most likely, we will include these properties and give a
best practice, but not make them required.
Trade-off is additional triples or additional query patterns (please excuse
any syntax errors ):
with shortcut
Select ?label {
?s a nif:EntityAnnotation .
?s fise:entity-label ?label .
}
or alternatively (all three possible):
Select ?label {
?s a nif:EntityAnnotation .
?s itsrdf:taIdentRef ?entity .
?entity rdfs:label ?label .
}
How would you know that '?entity' uses the rdfs:label property for the
labels. It might also be foaf:name, skos:prefLabel, schema:name ...
Well, NIF is a standard and there is a validator already. We would
coordinate this with the BPMLOD (http://www.w3.org/community/bpmlod/)
and Ontolex (http://www.w3.org/community/ontolex/) W3C groups to reach a
broad consensus. Then we select *the* property that we want and make it
mandatory, if others exist.
SPARQL tests:
https://github.com/NLP2RDF/java-maven/tree/master/core/jena/src/main/resources/sparqltest/missing_property
Select ?s ?message {
?s itsrdf:taIdentRef ?entity .
?entity ?triggerProperty ?label .
BIND (concat(str(?triggerProperty), " for entity ", str(?s) , " found,
but not mandatory property our:mandatoryProperty (link to standard) ")
AS ?message)
FILTER (NOT EXISTS {?s our:mandatoryProperty ?label} ) .
FILTER (?triggerProperty in (foaf:name, rdfs:label, skos:prefLabel,
schema:name, fise:entity-type ) )
}
or
Select ?labels {
?s a nif:EntityAnnotation .
?s dc:relation ?string .
?string a nif TextAnnotation .
?string nif:anchorOf ?label .
}
The label of the Entity might be different to the anchor Text. E.g. if
the Text mentions a person by switching the order of given and family
name, or if the mention uses the plural form of an Entity.
rdfs:label was just an example. There are some databases (mis) using it:
http://dbpedia.org/class/yago/UnitedStates
or even very generic, using http://www.w3.org/TR/sparql11-query/#func-substr
(no extra property needed)
Select ?labels {
?s a nif:EntityAnnotation .
?s dc:relation ?string .
?string a nif:TextAnnotation , nif:RFC5147String .
?string nif:beginIndex ?b .
?string nif:endIndex ?e .
?string nif:referenceContext ?contentItem .
?contentItem nif:isString ?text .
BIND (SUBSTR (?text, ?b, (?e - ?b) ) as ?label ) .
}
This would not work if the sent content was encoded in a rich text format
?? NIF assumes text, so it works on the extracted text and delivers it
to the client via nif:isString . Maybe I understand the notion of
contentItem wrong here. It can also be a PDF or an image (OCR) . Is this
more correct:
urn:content-item-5-text-representation#char=0,40
a nif:Context ;
nif:isString "My favourite actress is Natalie Portman." ;
# provenance, where did the tool extract the text from?
nif:sourceUrl urn:content-item-5-PDF-representation .
All the best,
Sebastian
best
Rupert
Thanks for the feedback,
Sebastian
Am 10.07.2013 12:43, schrieb Rupert Westenthaler:
Hi Sebastian,
Thanks for all your effort Sebastian!
Sorry for my late response, but I am traveling this and the next week.
So I do not have enough time to properly look into this. At least I
had the change to have a look at the mappings [4]. I will try to
provide some initial feedback with this mail.
### The fise:entity-label
regarding the comment:
# ??? not sure about fise:entity-label
# This should be dbpedia:London rdfs:label "London"@en ;
#
# fise:entity-label
# a owl:DatatypeProperty ;
# rdfs:comment "the label(s) of the referenced Entity"@en ;
# rdfs:domain :EntityAnnotation .
This property is intended to hold the label of the entity that best
matched the mention in the text. It is not always the case that this
will be the rdfs:label. This depends on the ontology used by suggested
Entity. Labels might also come from multiple properties (e.g. in the
case of SKOS where both skos:prefLabel, skos:altLabel do hold label
information)
In addition the fise:entity-type and fise:entity-label values are
intended to be used for visualization purposes in cases where the
client does not dereference the linked (fise:entity-reference) entity.
### None FISE namespace properties
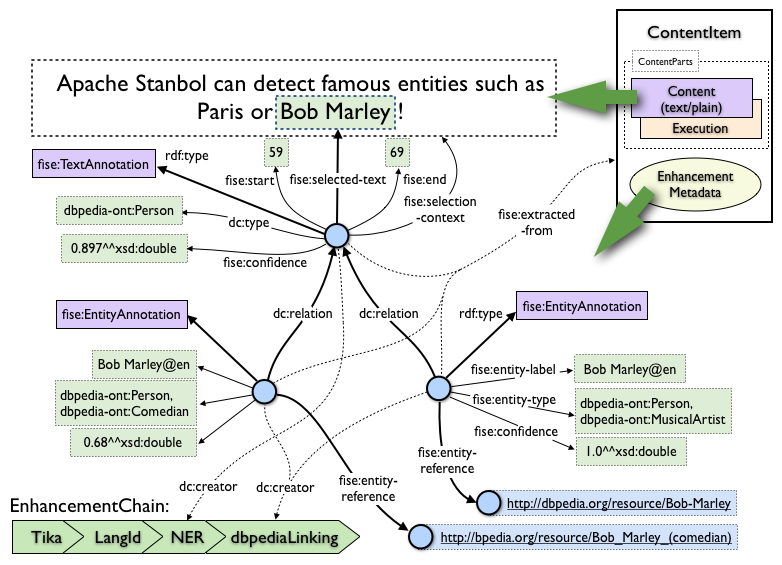
I would also like to mention that the Stanbol Enhancement Structure
also uses some DC Type properties (e.g. fise:EntityAnntoation do use
dot:relation to link to the fise:TextAnnotation) (see [9] for a figure
and [10] for the full documentation). AFAIU those none fise namespace
properties are not included in the current mapping.
best
Rupert
[9]
http://stanbol.apache.org/docs/trunk/components/enhancer/enhancementstructure.png
[10]
http://stanbol.apache.org/docs/trunk/components/enhancer/enhancementstructure.html
On Mon, Jul 8, 2013 at 12:35 PM, Sebastian Hellmann
<[email protected]> wrote:
Good News Everyone!
Yesterday, I had a more detailed look at the FISE Ontology[1], which is
supposed to provide an output format for Apache Stanbol [2]. After a
while I
found out that they fit together without major problems, so I went ahead
and
created a merging proposal! The NIF Core Ontology [3] is now dually
licensed
under CC-By 3.0 and Apache 2.0 to ease integration.
The NIF inf model ([4], line 92) documents the mapping from NIF-Core to
Fise. One minor problem is that FISE uses xsd:int and not
xsd:nonNegativeInteger for indices.
The mapping is complete except for the (probably unnecessary)
fise:entity-label.
(cross posting to Stanbol and NLP2RDF list)
Due to this merger, the creation of a release candidate for NIF 2.0 is
coming along quite well now. The seven properties/classes (Context,
String,
isString, RFC5147String, endIndex, beginIndex, referenceContext) at the
core
are already stable.
We included a lot of people in the attribution section[5] as well, but
the
list is not yet exhaustive. Also there is a NIF validator software and
a
logging ontology.
The Validator uses SPARQL 1.1 to produce log output adhering to the
logging
ontology.
* Jar for CLI (no webservice yet) [6]
* Readme [7]
* The SPARQL queries [8]
Please feel free to:
* download the validator and test it on your NIF implementation to see
what
changed
* check if we spelled your name correctly ;) in the attribution section
[5].
* Please also tell us whether we should add your logo in the
maintainer/supporter section
* check and extend the ontology and write some additional SPARQL
queries[8]
Since we moved to GitHub now, we are also eager to give out push
permissions....
All the best,
Sebastian
[1] http://fise.iks-project.eu/ontology/
[2] http://stanbol.apache.org/
[3]
https://github.com/NLP2RDF/persistence.uni-leipzig.org/blob/master/ontologies/nif-core/version-1.0/nif-core.ttl
[4]
https://github.com/NLP2RDF/persistence.uni-leipzig.org/blob/master/ontologies/nif-core/version-1.0/nif-core-inf.ttl#L92
[5] http://persistence.uni-leipzig.org/nlp2rdf/#attribution
[6] https://github.com/NLP2RDF/java-maven/raw/master/validate.jar
[7]
https://github.com/NLP2RDF/java-maven/blob/master/README.md#nif-validator
[8]
https://github.com/NLP2RDF/java-maven/tree/master/core/jena/src/main/resources/sparqltest
--
On holidays from 11. July until 3. August
Dipl. Inf. Sebastian Hellmann
Department of Computer Science, University of Leipzig
Events:
* NLP & DBpedia 2013 (http://nlp-dbpedia2013.blogs.aksw.org, Extended
Deadline: *July 18th*)
* LSWT 23/24 Sept, 2013 in Leipzig (http://aksw.org/lswt)
Venha para a Alemanha como PhD: http://bis.informatik.uni-leipzig.de/csf
Projects: http://nlp2rdf.org , http://linguistics.okfn.org ,
http://dbpedia.org/Wiktionary , http://dbpedia.org
Homepage: http://bis.informatik.uni-leipzig.de/SebastianHellmann
Research Group: http://aksw.org
_______________________________________________
NLP2RDF mailing list
[email protected]
http://lists.informatik.uni-leipzig.de/mailman/listinfo/nlp2rdf
--
On holidays from 11. July until 3. August
Dipl. Inf. Sebastian Hellmann
Department of Computer Science, University of Leipzig
Events:
* NLP & DBpedia 2013 (http://nlp-dbpedia2013.blogs.aksw.org, Extended
Deadline: *July 18th*)
* LSWT 23/24 Sept, 2013 in Leipzig (http://aksw.org/lswt)
Venha para a Alemanha como PhD: http://bis.informatik.uni-leipzig.de/csf
Projects: http://nlp2rdf.org , http://linguistics.okfn.org ,
http://dbpedia.org/Wiktionary , http://dbpedia.org
Homepage: http://bis.informatik.uni-leipzig.de/SebastianHellmann
Research Group: http://aksw.org
--
| Rupert Westenthaler [email protected]
| Bodenlehenstraße 11 ++43-699-11108907
| A-5500 Bischofshofen
--
| Rupert Westenthaler [email protected]
| Bodenlehenstraße 11 ++43-699-11108907
| A-5500 Bischofshofen
_______________________________________________
NLP2RDF mailing list
[email protected]
http://lists.informatik.uni-leipzig.de/mailman/listinfo/nlp2rdf
--
On holidays from 11. July until 3. August
Dipl. Inf. Sebastian Hellmann
Department of Computer Science, University of Leipzig
Events:
* NLP & DBpedia 2013 (http://nlp-dbpedia2013.blogs.aksw.org, Extended
Deadline: *July 18th*)
* LSWT 23/24 Sept, 2013 in Leipzig (http://aksw.org/lswt)
Venha para a Alemanha como PhD: http://bis.informatik.uni-leipzig.de/csf
Projects: http://nlp2rdf.org , http://linguistics.okfn.org ,
http://dbpedia.org/Wiktionary , http://dbpedia.org
Homepage: http://bis.informatik.uni-leipzig.de/SebastianHellmann
Research Group: http://aksw.org
{kind=link}