VertexStep that got replaced with JanusgraphVertexStep.
Good for them, first prize is not replacing anything.
Cheers
Pieter
On 24/04/2018 19:50, Keith Lohnes wrote:
It looks like it,
`g.V().has("foo", "bar").repeat(out()).emit().explain()`
yields
`[JanusGraphStep([],[foo.eq(bar)]),
RepeatStep([JanusGraphVertexStep(OUT,vertex),
RepeatEndStep],until(false),emit(true))]`
On Tue, Apr 24, 2018 at 12:12 PM pieter gmail <[email protected]
wrote:
Hi,
Sqlg completely replaces TinkerPop's RepeatStep. The idea being that
with g.V().repeat(out()).times(x) only x round trips to the db is
needed
regardless of the size of the graph. Each time it will go to the db
with
the full set of the previous step's incoming starts.
But yeah TinkerPop's implementation is always the starting point so
I'll
definitely have a look at how you have implemented DFS.
BTW, does Janus graph use TinkerPop's default RepeatStep as is with no
optimization strategies?
Cheers
Pieter
On 24/04/2018 16:33, Keith Lohnes wrote:
Pieter,
If you take a look at https://github.com/apache/tinkerpop/pull/838
DFS
is
implemented as a modification to BFS. It's taking the starts that
come
in
from a BFS and stashing them to be processed later. I haven't seen a
big
performance difference on JanusGraph; At least for the queries that
I've
been running with it. I'm not terribly familiar with Sqlg, but I
wonder
if
in the context of how DFS is implemented there, it may be less of a
concern.
Cheers,
Keith
On Thu, Apr 19, 2018 at 12:46 PM pieter gmail <
[email protected]
wrote:
Hi,
Not really sure either what 'global' means technically with respect
to
TinkerPop's current configuration support.
Perhaps it can be the start of a global configuration registry that
can
be overridden per traversal.
I get that DFS is the preferred default but for Sqlg the performance
impact is so great that I'd rather, if possible have BFS as its
default.
I am not sure about this but I reckon that any graph where the
TinkerPop
vm is not running in the same process space as the actual graph/data
that latency is a big issue. BFS alleviates the latency issue
significantly.
Cheers
Pieter
On 19/04/2018 14:49, Keith Lohnes wrote:
whether this will affect more than just
repeat()?
For the PR that I start and the intent of this thread was to only
affect
repeat.
I prefer that the semantics of the traversal be specified in the
traversal
as a first class citizen.
+1
I am fine with any default but am wondering whether it would
be
worthwhile for the default to be overridden at a global level at
not
just
per traversal
It might be nice, but I guess I'm not sure what `global` means in
this
context. Configured on the graph object?
On Tue, Apr 17, 2018 at 9:28 PM Daniel Kuppitz <[email protected]>
wrote:
TinkerPop makes no guarantees about the order of elements unless
you
specify an explicit order. This also goes back to the fact that
certain
strategies (LazyBarrier-, RepeatUnroll- and
PathRetractionStrategy)
add
NoOpBarrierSteps to your traversal, which ultimately turns it
into a
DFS/BFS mix. Check the .explain() output of your traversal to see
which
strategy adds which steps.
Cheers,
Daniel
On Tue, Apr 17, 2018 at 4:45 PM, Michael Pollmeier <
[email protected]> wrote:
Also it seems to me that DFS only really applies to repeat()
with
an
emit().
g.V().hasLabel("A").repeat().times(2) gets rewritten as
g.V().hasLabel("A").out().out(). Are their subtleties that I am
not
aware of or does DFV vs BFS not matter in this case?
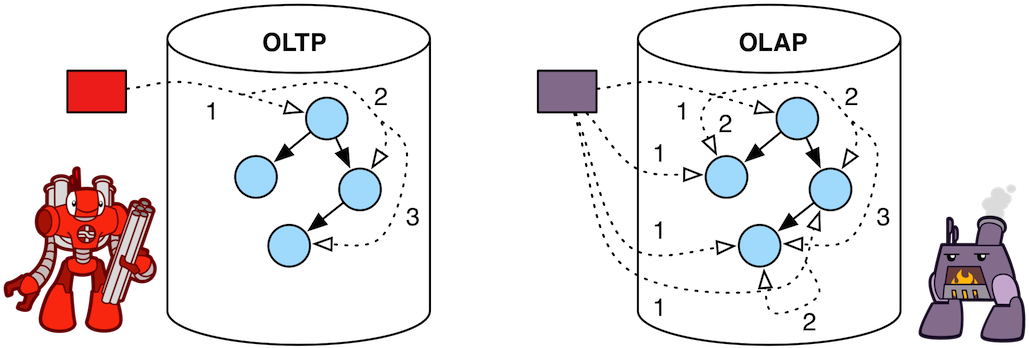
When I read this I thought: clearly `.out().out()` is DFS for
OLTP,
that's also what the documentation says, e.g. in this nice
infographic
http://tinkerpop.apache.org/docs/current/images/oltp-vs-olap.png
However, looks like that's not the case. Has my life been a lie?
Setting
up a simple flat graph to make things more obvious:
v3 <- v1 <- v0 -> v2 -> v4
```
graph = TinkerGraph.open()
v0 = graph.addVertex("l0")
v1 = graph.addVertex("l1")
v2 = graph.addVertex("l1")
v3 = graph.addVertex("l2")
v4 = graph.addVertex("l2")
v0.addEdge("e", v2)
v2.addEdge("e", v4)
v0.addEdge("e", v1)
v1.addEdge("e", v3)
g = graph.traversal()
g.V(v0).out().sideEffect{println(it)}.out().sideEffect{
println(it)}
```
Prints:
v[2]
v[1]
v[4]
==>v[4]
v[3]
==>v[3]
If this was OLTP the output would be:
v[2]
v[4]
==>v[4]
v[1]
v[3]
==>v[3]
Cheers
Michael
On 18/04/18 02:58, pieter gmail wrote:
Hi,
I agree with the question about whether this will affect more
than
just
repeat()?
I prefer that the semantics of the traversal be specified in the
traversal as a first class citizen. i.e. with order(SearchAlgo).
Strategies are to my mind internal to an implementation. In
Robert's
example LazyBarrierStrategy may be replaced/removed by an
implementation
for whatever internal reason they have.
Regarding the default, I am fine with any default but am
wondering
whether it would be worthwhile for the default to be overridden
at a
global level at not just per traversal? That way the impact can
also
be
alleviated when folks upgrade.
Also it seems to me that DFS only really applies to repeat()
with
an
emit().
g.V().hasLabel("A").repeat().times(2) gets rewritten as
g.V().hasLabel("A").out().out(). Are their subtleties that I am
not
aware of or does DFV vs BFS not matter in this case?
Cheers
Pieter
On 17/04/2018 14:58, Robert Dale wrote:
+1 on DFS
-1 on order(SearchAlgo)
It seems like a strategy may be more appropriate. It could
affect
more
than just repeat(). And how would this interact with
LazyBarrierStrategy?
Maybe the default should be DFS with LazyBarrierStrategy. Then
LazyBarrierStrategy
can be removed with 'withoutStrategies()' and then it works
just
like
everything else. I'd prefer consistency with the way
everything
else
works.
Robert Dale
On Tue, Apr 17, 2018 at 8:11 AM, Stephen Mallette <
[email protected]
wrote:
Thanks for the summary. Just a quick note - I'd not worry
about
the
GLV
tests for now. That part should be easy to sort out. Let's
first
make
sure
that we get clear on the other items first before digging too
deeply
there.
On an administrative front, I think that this change should
just
go
to
3.4.0/master (so it's currently targeted to the right branch
actually) as
it sounds like we want DFS to be the default and that could
be a
breaking
change as the semantics of the traversal shift a bit. So
that's
one
issue
to make sure we're all happy with.
A next issue would be the API from the user perspective -
thanks
for
the
link to that JIRA btw - I see I was involved in that
conversation
a
little
bit but then dropped off. You'd commented that you preferred a
per
loop
configuration for search approach which is what you stuck with
for
the
implementation. I guess I can see that there could be some
value
in
having
that ability. That said, I'm not sure that I like the overload
of
order()
as the method for doing that:
g.V().has("name", "marko").
repeat(__.outE().order().by("weight", decr).inV()).
emit().
order(SearchAlgo.DFS)
Still thinking about what else we might do there, but perhaps
that
can wait
a bit as I still need to study your changes in detail.
Regarding:
The barrier step that Daniel described doesn’t currently
work
since
there’s basically booleans in the RepeatStep on whether or not
to
stash the
starts to make the RepeatStep depth first.
I assume you are referring to these booleans:
https://github.com/apache/tinkerpop/blob/
fe8ee98f6967c7b0f0ee7f2cf2d105
31b68fab8b/gremlin-core/src/main/java/org/apache/
tinkerpop/gremlin/process/traversal/step/branch/
RepeatStep.java#L46-L47
?
On Tue, Apr 17, 2018 at 7:37 AM, Keith Lohnes <
[email protected]>
wrote:
Stephen, That’s a fair summary. I had an immediate need for
it,
so
I
developed something based on Michel Pollmeier’s work and a
modification
to
the syntax Pieter Martin suggested in the Jira
<https://issues.apache.org/jira/browse/TINKERPOP-1822?
focusedCommentId=16233681&page=com.atlassian.jira.
plugin.system.issuetabpanels%3Acomment-tabpanel#comment-1623
3681>
with DFS being explicit.
The semantics I used were g.V().repeat(out()).order(DFS),
putting
the
order
clause outside of the repeat. It made it simpler for me to
develop
and
seemed nice to make that DFS vs BFS explicit. The barrier
step
that
Daniel
described doesn’t currently work since there’s basically
booleans
in
the
RepeatStep on whether or not to stash the starts to make the
RepeatStep
depth first.
I added a test for the DFS, though I’ve had some issues
getting
things to
run re: .net tests and some other tests timing out. I have
some
more
tests
I'd like to write based off issues that I ran into testing
this
in
the
console (k-ary trees, until/emit before the repeat vs after),
but I
really
wanted to get this out there for people to take a look at and
see
if
it
could work out.
On Mon, Apr 16, 2018 at 7:29 PM Stephen Mallette <
[email protected]>
wrote:
Keith, I have to admit that I didn't really follow this
general
body
of
work closely, which include this pull request, the earlier
one
from
Michael
Pollmeier, the JIRA and I think some discussion somewhere on
one
of
the
mailing lists. As best I have gathered from what I did
follow, I
feel
like
the focus of this work so far was mostly related to "can
someone
get it
to
actually work", but not a lot about other aspects like
testing,
api,
release branch to apply it to, etc. Is that a fair depiction
of
how
this
work has developed so far? if so, let's use this thread to
make
sure
we're
all on the same page as to how this change will get in on
all
those
sorts
of issues.
btw, thanks to you and michael for sticking at this to come
to
something
that seems to work. looking forward to the continued
discussion
on
this
thread.
On Mon, Apr 16, 2018 at 6:54 PM, Michael Pollmeier <
[email protected]> wrote:
Unsurprisingly I'm also +1 for defaulting to DFS in OLTP.
My
feeling
is
that most users currently expect it to be DFS since that's
what
the
docs
{kind=link}