And 40+ years of programming languages research too :-)
> On Apr 25, 2019, at 12:36 PM, Joshua Shinavier <[email protected]> wrote:
>
> +10. Great to see structure and process coming together in this way. I think
> the algebraic and relational idiom will serve TP4 well. ADTs + constraints
> are all we need in order to expose a wide variety of structured data models
> to TinkerPop. Traditional property graphs, hypergraphs, relational DBs, and
> anything expressed in typical data interchange languages like Protobuf,
> Thrift, Avro, etc. Graph I/O and graph stream processing becomes easier,
> because a graph is just a set of tuples. There are fewer barriers to formal
> analysis of schemas, queries, and mappings, and new forms of optimization
> become possible. 40+ years of database research is now more immediately
> applicable, and so is the wide world of category theory. Agreed that there
> are individual details to nail down, but the broad strokes of this are
> looking pretty good.
>
> Josh
>
>
> On Thu, Apr 25, 2019 at 10:46 AM Marko Rodriguez <[email protected]> wrote:
> Hello,
>
> This email proposes a TP4 bytecode specification that is agnostic to the
> underlying data structure and thus, is both:
>
> 1. Turing Complete: the instruction set has process-oriented
> instructions capable of expressing any algorithm (universal processing).
> 2. Pointer-Based: the instruction set has data-oriented instructions
> for moving through referential links in memory (universal structuring).
>
> Turing Completeness has already been demonstrated for TinkerPop using the
> following sub-instruction set.
> union(), repeat(), choose(), etc. // i.e. the standard program flow
> instructions
>
> We will focus on the universal structuring aspect of this proposed bytecode
> spec. This work is founded on Josh Shinavier’s Category Theoretic approach to
> data structures. My contribution has been to reformulate his ideas according
> to the idioms and requirements of TP4 and then deduce a set of TP4-specific
> implementation details.
>
> TP4 REQUIREMENTS:
> 1. The TP4 VM should be able to process any data structure (not just
> property graphs).
> 2. The TP4 VM should respect the lexicon of the data structure (not
> just embed the data structure into a property graph).
> 3. The TP4 VM should allow query languages to naturally process their
> respective data structures (standards compliant language compilation).
>
> Here is a set of axioms defining the structures and processes of a universal
> data structure.
>
> THE UNIVERSAL STRUCTURE:
> 1. There are 2 data read instructions — select() and project().
> 2. There are 2 data write instructions — insert() and delete().
> 3. There are 3 sorts of data — tuples, primitives, and sequences.
> - Tuples can be thought of as “key/value maps.”
> - Primitives are doubles, floats, integers, booleans, Strings,
> etc.
> - Sequences are contiguous streams of tuples and/or primitives.
> 4 Tuple data is accessed via keys.
> - A key is a primitive used for referencing a value in the
> tuple. (not just String keys)
> - A tuple can not have duplicate keys.
> - Tuple values can be tuples, primitives, or sequences.
>
> Popular data structures can be defined as specializations of this universal
> structure. In other words, the data structures used by relational databases,
> graphdbs, triplestores, document databases, column stores, key/value stores,
> etc. all demand a particular set of constraints on the aforementioned axioms.
>
> ////////////////////////////////////////////////////////////
> /// A Schema-Oriented Multi-Relational Structure (RDBMS) ///
> ////////////////////////////////////////////////////////////
>
> RDBMS CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
> 1. There are an arbitrary number of global tuple sequences (tables)
> 2. All tuple keys are Strings. (column names)
> 3. All tuple values are primitives. (row values)
> 4. All tuples in the same sequence have the same keys. (tables have
> predefined columns)
> 5. All tuples in the same sequence have the same primitive value type
> for the same key. (tables have predefined row value types)
>
> Assume the following tables in a relational database.
>
> vertices
> id label name age
> 1 person marko 29
> 2 person josh 35
>
> edges
> id outV label inV
> 0 1 knows 2
>
> An SQL query is presented and then the respective TP4 bytecode is provided
> (using fluent notation vs. [op,arg*]*).
>
> // SELECT * FROM vertices WHERE id=1
> select(‘vertices’).has(‘id’,1)
> => v[1]
> // SELECT name FROM vertices WHERE id=1
> select(‘vertices’).has(‘id’,1).project('name’)
> => "marko"
> // SELECT * FROM edges WHERE outV=1
> select('edges’).has('outV’,1)
> => e[0][v[1]-knows->v[2]]
> // SELECT * FROM edges WHERE outV=(SELECT 'id' FROM vertices WHERE
> name=‘marko')
> select('edges’).has(‘outV’,within(select(‘vertices’).has(‘name’,’marko’).project(‘id’)))
>
> => e[0][v[1]-knows->v[2]]
> // SELECT vertices.* FROM edges,vertices WHERE outV=1 AND id=inV
> select(‘vertices’).has(‘id’,1).select('edges').by('outV',eq('id')).select('vertices').by('id',eq('inV'))
> => v[2]
>
> VARIATIONS:
> 1. Relational databases that support JSON-blobs values can have nested
> “JSON-constrained” tuple values.
> 2. Relational databases the materialize views create new tuple
> sequences.
>
> //////////////////////////////////////////////////////////////////
> /// A Schema-Less, Recursive, Bi-Relational Structure (GRAPHDB) //
> //////////////////////////////////////////////////////////////////
>
> GRAPHDB CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
> 1. There are two sorts of tuples: vertex and edge tuples.
> 2. All tuples have an id key and a label key.
> - id keys reference primitive values.
> - label keys reference String values.
> 3. All vertices are in a tuple sequence denoted “V”.
> 4. Vertex tuples have an inE and outE key each containing edge tuples.
> 5. Edge tuples have an outV and inV key each containing a single vertex
> tuple.
> 6. An arbitrary number of additional String-based tuple keys exist for
> both vertices and edges.
>
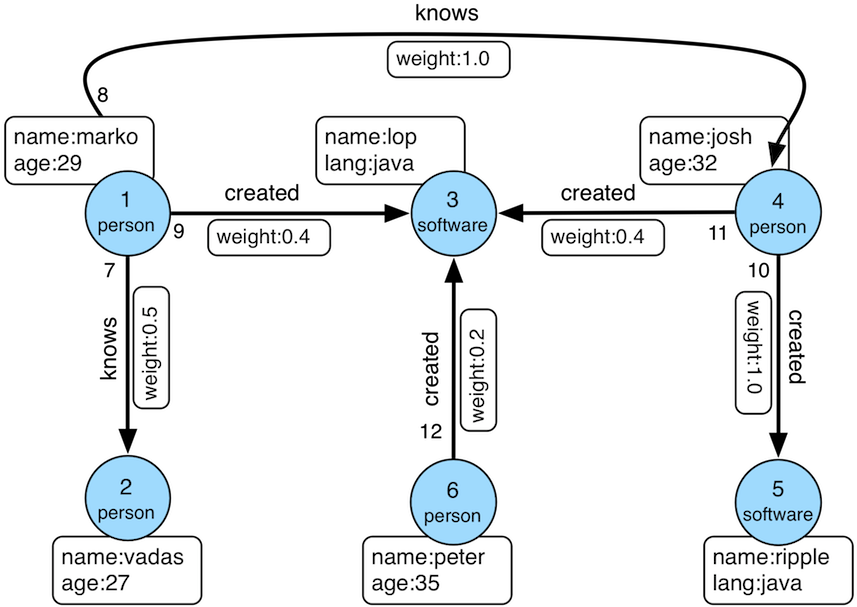
> Assume the “classic TinkerPop graph” where marko knows josh and they have
> names and ages, etc.
> http://tinkerpop.apache.org/docs/current/images/tinkerpop-modern.png
>
> A Gremlin query is presented and then the respective TP4 bytecode is provided
> (using fluent notation vs [op,arg*]*).
>
> // g.V(1)
> select(‘V’).has(‘id’,1)
> => v[1]
> // g.V(1).label()
> select(‘V’).has(‘id’,1).project('label’)
> => “person"
> // g.V(1).values(‘name’)
> select(‘V’).has(‘id’,1).project(‘name’)
> => “marko”
> // g.V(1).outE('knows').inV().values('name')
> select(‘V’).has(‘id’,1).project('outE').has('label','knows').project('inV').project('name’)
>
> => “josh”, “vadas”, “peter”
> // g.V(1).out('knows').values('name')
> select(‘V’).has(‘id’,1).project('outE').has('label','knows').project('inV').project('name’)
>
> => “josh”, “vadas”, “peter"
> // g.V().has(‘age’,gt(25)).values(‘age’).min()
> select(‘V’).has(‘age’,gt(25)).project(‘age’).min()
> => 29
> // g.V(1).as(‘a’).out(‘knows’).addE(‘likes’).to(‘a’)
> select(‘V’).has(‘id’,1).as(‘a’).
> project(‘outE’).has(‘label’,’knows’).
> project(‘inV’).
> project(‘inE’).insert(identity(),’likes’,path(‘a’))
> => e[7][v[2]-likes->v[1]], ...
>
> VARIATIONS:
> 1. Schema-based property graphs have the same tuple keys for all vertex
> (and edge) tuples of the same label.
> 2. Multi-labeled property graphs have String sequences for vertex
> labels.
> 3. Multi-property property graphs have primitive sequences for property
> keys.
> 4. Meta-property property graphs have an alternating sequence
> primitives (values) and tuples (properties).
> 5. Multi/meta-property property graphs support repeated values in the
> alternating sequences of the meta-property property graphs.
>
> //////////////////////////////////////////////////////////////////////////
> /// A Web-Schema, 3-Tuple Single Relational Structure (RDF TRIPLESTORE) //
> //////////////////////////////////////////////////////////////////////////
>
> RDF TRIPLESTORE CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
> 1. There is only one type of tuple called a triple and it is denoted T.
> 2. All tuples have a s, p, and o key. (subject, predicate, object)
> - s keys reference String values representing URIs or blank
> nodes.
> - p keys reference String values representing URIs.
> - o keys reference String values representing URIs, blank
> nodes, or literals.
>
> A SPARQL query is presented and then the respective TP4 bytecode is provided
> (using fluent notation vs [op,arg*]*).
> - assume ex: is the namespace prefix for http://example.com#
>
> // SELECT ?x WHERE { ex:marko ex:name ?x }
> select(’T').by(’s’,is(‘ex:marko')).has(‘p’,’ex:name').project(‘o') ->
> "marko"^^xsd:string
> // SELECT ?y WHERE { ex:marko ex:knows ?x. ?x ex:name ?y }
> select(’T').by(’s’, is(‘ex:marko')).has(‘p’,’ex:knows’).
> select(’T’).by(’s’,eq(‘o’)).has(‘p’,’ex:name’).
> project(‘o’) -> “josh"^^xsd:string
>
> VARIATIONS:
> 1. Quadstores generalize RDF with a 4-tuple containing a ‘g’ key
> (called the "named graph").
> 2. RDF* generalizes RDF by extending T triples with an arbitrary number
> of String keys (thus, (spo+x*)-tuples)).
>
> ///////////////////////////////////////////////////////////////////////
> /// A Schema-Less, Type-Nested, 3-Relational Structure (DOCUMENTDB) //
> ///////////////////////////////////////////////////////////////////////
>
> DOCUMENTDB CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
> 1. There are sorts of tuples: documents, lists, and maps.
> 2. Document tuples are in a sequence denoted D.
> 3. All document tuples have an _id key.
> 4. All tuple keys are string keys.
> 5. All tuple values are either primitives, lists, or maps. (JSON-style)
> - primitives are either long, double, String, or boolean.
>
> ///////////////////////////////////////////////////////////
> /// A Schema-Less Multi-Relational Structure (BIGTABLE) ///
> ///////////////////////////////////////////////////////////
>
> BIGTABLE CONSTRAINTS ON THE UNIVERSAL STRUCTURE: (CASSANDRA)
> 1. There are an arbitrary number of global tuple sequences. (column
> families)
> 2. All tuple keys are Strings. (column key)
> 3. All tuple values are primitives. (row values)
>
> /////////////////////////////////////////////////////////////////////////
> /// A Schema-Less 1-Tuple Single-Relational Structure (KEYVALUESTORE) ///
> /////////////////////////////////////////////////////////////////////////
>
> KEYVALUESTORE CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
> 1. There is one global tuple sequence.
> 2. Each tuple has a single key/value.
> 3. All tuple keys must be unique.
>
> ————————————————————————————————————————————————————————
> ————————————————————————————————————————————————————————
> ————————————————————————————————————————————————————————
>
> WHY SEQUENCES?
>
> In property graphs, V is a tuple sequence.
>
> // g.V()
> select(‘V’)
> => v[1], v[2], v[3],...
> // g.V(1)
> select(‘V’).has(‘id’,1)
> => v[1]
> // g.V().has(‘name’,’marko’)
> select(‘V’).has(‘name’,’marko’)
> => v[1]
>
> If V were a tuple of vertex tuples, then V would be indexed by keys. This
> situation incorporates superfluous “indexing” which contains information
> auxiliary to the data structure.
>
> // g.V()
> select(‘V’).values()
> => v[1], v[2], v[3], ...
> // g.V(1)
> select(‘V’).project(‘1’)
> => v[1]
> // g.V().has(‘name’,’marko’)
> select(‘V’).values().has(‘name’,’marko’)
> => v[1]
>
> In property graphs, outE is a tuple sequence unique to each vertex.
>
> // g.V(1).outE()
> select(‘V’).has(‘id’,1).project(‘outE’)
> => e[0][v[1]-knows->v[2]]...
>
> In all structures, if x is a key and the value is a tuple, then x references
> a tuple sequence with a single tuple. In particular, for binary property
> graphs, project(‘inV’) is a single tuple sequence.
>
> // g.V(1).outE(’knows').inV()
> select(‘V’).has(‘id’,1).project(‘outE’).has(‘label’,’knows’).project(‘inV’)
> => e[0][v[1]-knows->v[2]]
>
> ————————————————————————————————————————————————————————
>
> JOINS VS. TRAVERSALS
>
> In relational databases, a join is the random-access movement from one tuple
> to another tuple given some predicate.
>
> // g.V().outE().label()
> // SELECT edges.label FROM vertices, edges WHERE vertices.id = edges.outV
> select(‘vertices’).select(‘edges’).by(id,eq(‘outV’)).project(‘label’)
> => knows, knows, created, ...
>
> In a graph database, the structure is assumed to be "pre-joined" and thus, a
> selection criteria is not needed.
>
> // g.V().outE().label()
> select(‘vertices’).project(‘outE’).project(‘label’)
> => knows, knows, created, …
>
> A latter section will discuss modeling one data structure within another data
> structure within the universal data structure. In such situations, joins may
> become traversals given Tuple data caching and function-based tuple values.
>
> ————————————————————————————————————————————————————————
>
> THE STRUCTURE PROVIDER OBJECTS OF A TP4 VIRTUAL MACHINE
>
> Data structure providers (i.e. database systems) interact with the TP4 VM via
> objects that implement:
>
> 1. Tuple
> - TupleSequence select(String key, Predicate join)
> - V project(K key)
> 2. TupleSequence
> - TupleSequence implements Iterator<Tuple>
> 3. and primitives such as String, long, int, etc.
>
> These interfaces may maintain complex behaviors that take unique advantage of
> the underlying data system (e.g. index use, function-oriented tuple values,
> data caching, etc.).
>
> This means that the serializers to/from TP4 need only handle the following
> object types:
>
> - Bytecode
> - Traverser
> - Primitives (String, long, int, etc.)
> - TupleProxy
> - TupleSequenceProxy
>
> This significantly simplifies the binary serialization format relative to TP3.
>
> Tuple’s are never serialized/deserialized as they may be complex,
> provider-specific objects with runtime functional behavior that interact with
> the underlying data system over sockets/etc. Thus, every Tuple implementation
> must have a corresponding TupleProxy which provides an appropriate
> “toString()” of the object and enough static data to reconnect the TupleProxy
> to the Tuple within the VM. This latter requirement is necessary for
> distributed processing infrastructures that migrate traversers between
> machines.
>
> - TupleProxy
> - Tuple attach(Structure provider)
> - String toString()
> - Tuple
> - TupleProxy detach()
>
> Similar methods exist for TupleSequence.
>
> ————————————————————————————————————————————————————————
>
> MODELING ONE DATA STRUCTURE WITHIN ANOTHER DATA STRUCTURE WITHIN THE
> UNIVERSAL DATA STRUCTURE
>
> The “shape of the data" determines the nature of the data structure. The
> question that arises is: What happens when a property graph is encoded in a
> relational database and property graph-oriented bytecode is used? This will
> yield exceptions as relational databases can not nest tables. To solve this
> in practice, it is possible to:
>
> 1. Rewrite the property graph bytecode to respective “property graph
> encoded” relational bytecode using a compiler strategy. (via a decoration
> strategy)
> 2. Develop Tuple objects that maintain functions for values that map
> the data accordingly.
>
> With respects to 2.
>
> VertexRow implements Tuple
>
> v = new VertexRow(1)
> v.project(‘outE’) // this method (for outE) computes the edge tuple sequence
> via SELECT * FROM edges WHERE outV=1
> => a bunch of EdgeRowTuples with similar function-based
> projection and selection operations.
>
> It is possible to model any data structure within any database system,
> regardless of the native data structure supported by the database. In TP4,
> databases are understood to be memory systems (like RAM) optimized for
> particular tuple-structures (e.g. sequential access vs. random access,
> index-based vs. nested based, cache support, etc.).
>
> ————————————————————————————————————————————————————————
>
> CUSTOM DATA STRUCTURE INSTRUCTIONS
>
> In order to make provider bytecode compilation strategies easy to write,
> DecorationStrategies can exist that translate “universal data structure”
> read/write instructions to “specific data structure” read/write instructions.
> For example, a property graph specific read/write instruction set is
> namespaced as “pg” and the following bytecode
>
> // g.V(1).out(‘knows’).values(‘name’)
> [[select,V] [has,id,eq(1)] [project,outE] [has,label,eq(knows)] [select,inV]
> [project,name]]
> ===strategizes to (via PropertyGraphDecorationStrategy)===>
> [[pg:V,1] [pg:out,knows] [pg:values, name]]
>
> Note that only read/write instructions need to be considered. All other
> instructions such as repeat(), choose(), count(), union(), is(), where(),
> match(), etc. are not effected by the underlying data structure.
>
> ————————————————————————————————————————————————————————
>
> There is still much more to discuss in terms of how all this relates to query
> languages and processors. While I haven’t considered all forks in the road, I
> have yet to hit any contradictions or inconsistencies when looking a
> few-steps ahead of where this email is now.
>
> Thank you for reading. Your thoughts are more than welcome.
>
> Take care,
> Marko.
>
> http://rredux.com
>
>
> --
> You received this message because you are subscribed to the Google Groups
> "Gremlin-users" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to [email protected].
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/gremlin-users/6A0FF63D-8591-41AC-B024-2FF5629B4CD5%40gmail.com.
> For more options, visit https://groups.google.com/d/optout.
>
> --
> You received this message because you are subscribed to the Google Groups
> "Gremlin-users" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to [email protected].
> To view this discussion on the web visit
> https://groups.google.com/d/msgid/gremlin-users/CAPKNUSv2jPxbuuLBLO7F4JQGsU_x6Bp1HXPA2FVD8dWXOwx8Aw%40mail.gmail.com.
> For more options, visit https://groups.google.com/d/optout.
{kind=link}