We propose a solution for TensorCore CodeGen with significant transparency, flexibility and usability. In this solution, the algorithm description and schedule of TensorCore CodeGen is no different than that of a normal CUDA CodeGen. All the information needed by wmma API, such as matrix_a/matrix_b/accumulator, row_major/col_major, warp tile size and so on, is automatically derived from the AST. Of course, not every algorithm and schedule is suitable for TensorCore computation. This solution will do the check and fall back to normal CUDA CodeGen for those that are not qualified for TensorCore CodeGen.
In this solution, 3 IRVisitors and 1 IRMutator are added. * IRVisitors: BodyVisitor, MMAMatcher and BufferAnalyser. * IRMutator: TensorCoreIRMutator. BodyVisitor, which is called by ScheduleAnalyser, visits the body stmt of original ComputeOp to get the access indices of input matrices if it is recognized as matrix multiply. ScheduleAnalyser compares the access indices with the axis/reduce_axis of ComputeOp to figure out whether an input matrix is matrix_a or matrix_b, row_major or col_major. MMAMatcher does the pattern matching on AST stmt. The pattern it tries to find out is as following: 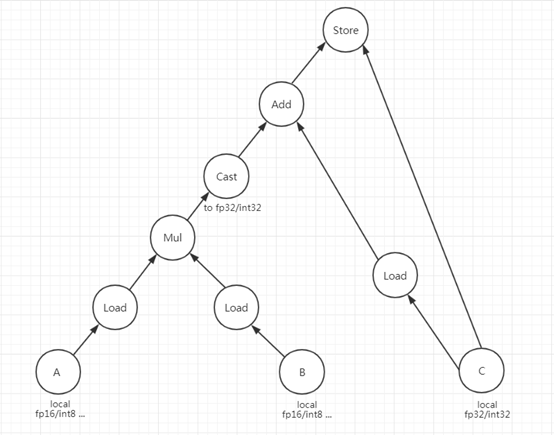 If matched, the a, b, c will be recorded as fragment registers, which are important inputs to the next visitor. BufferAnalyser, the last visitor, will get all of the rest information needed for TensorCoreIRMutator, like strides of src/dst buffer for wmma load/store matrix operation, warp tile size for fragment allocation as well as checking whether the schedule is qualified for TensorCore, loops that need to be scaled after normal load/store and compute operation replaced by TensorCore operations, etc.. TensorCoreIRMutator mutates the AST stmt for TensorCore CodeGen. The subtree matched by MMAMatcher will be replaced with “mma_sync” extern call. Load/Store of fragments are replaced with “load/store_matrix_sync” extern call, with the thread index getting unified within a warp. Thread index unification, i.e. changing the index of every thread to the same as the first thread of the warp, is done by ThreadIdxMutator on the subtree. The TensorCore IR Passes are applied before StorageFlatten because they need stride/shape and index of specific dimensions before they got flattened into one. Before StorageFlatten, “Allocation” is represented by Realize IR Node, which has no new_expr member as Allocate IR Node has. So we added it to Realize IR Node to carry the expr for fragment allocation and pass to Allocate IR Node. We noticed the comment of deprecating new_expr when merging with the latest TVM codebase. We would like to ask for a reconsideration of this decision, because it is really useful for some non-standard buffer allocations. This solution is evaluated on a sample schedule of Matmul, which is based on AutoTVM. It supports fp16 and int8 data type, and three kinds of data layouts: NN, NT, TN. On some model layers, we have already achieved better performance than CUBLAS/CUDNN: ### FP16 on V100, CUDA 9.0, Driver 396.44 * NMT Online Service (In-house Model) | M, N, K | CUBLAS TensorCore | TVM TensorCore | Speed Up | | -------- | -------- | -------- | -------- | | 512, 64, 512 | 9.05us | 7.34us | 1.23X | | 512, 32, 512 | 8.30us | 6.84us | 1.21X | | 512, 16, 512 | 7.88us | 6.60us | 1.19X | * MobileNet (Public Model) | H W C_IN C_OUT KERNEL KERNEL PAD_H PAD_W STRIDE_H STRIDE_W |CUDNN TensorCore| TVM TensorCore | SpeedUp | | -------- | -------- | -------- | -------- | | 56 56 64 128 1 1 0 0 1 1 | 8.5220us | 6.9320us | 1.23X | | 28 28 128 256 1 1 0 0 1 1 | 10.787us | 8.3490us | 1.29X | | 28 28 256 256 1 1 0 0 1 1 | 15.188us |14.136us | 1.07X | ### Int8 on T4, CUDA10.1, Driver 418.39 * NMT Online Service (In-house Model) | M, N, K | CUBLAS TensorCore | TVM TensorCore | Speed Up | | -------- | -------- | -------- | -------- | | 512, 64, 512 | 23.163us | 22.603us | 1.025X | | 512, 32, 512 | 22.551us | 14.263us | 1.58X | | 512, 16, 512 | 22.510us | 11.015us | 2.04X | There are also many shapes on which CUBLAS/CUDNN is much better. The performance tuning is still on-going. Thanks! -- Minmin Sun, Lanbo Li, Chenfan Jia and Jun Yang of Alibaba PAI team -- You are receiving this because you are subscribed to this thread. Reply to this email directly or view it on GitHub: https://github.com/dmlc/tvm/issues/4105
{kind=link}