I'm using dask to do calculations on a large amount of data which I then save locally to a partitioned parquet file. I figured a partitioned file would allow for better parallelism.
Saving the data from multiple workers takes less 30s: 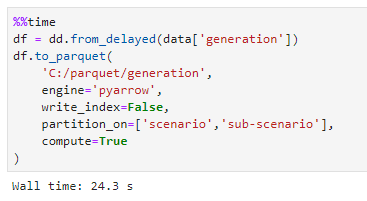 ...but I'm finding that reading the data back takes more than 5 times longer than writing the data and that more threads doesn't help: 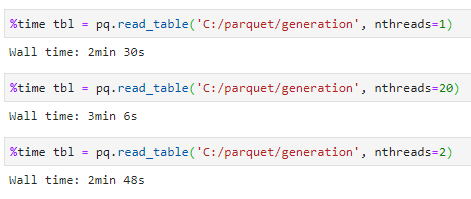 The read performance is a bit of a surprise - it's faster to simply extract and transform the data from source than it is to read back the transformed data from a parquet file. Is this performance asymmetry (read/write) expected? [ Full content available at: https://github.com/apache/arrow/issues/2614 ] This message was relayed via gitbox.apache.org for [email protected]
{kind=link}
{kind=link}