This is happening for us as well. We have roughly 400 GB of DB files and this hits us pretty hard as some of the DBs see a lot of changes.
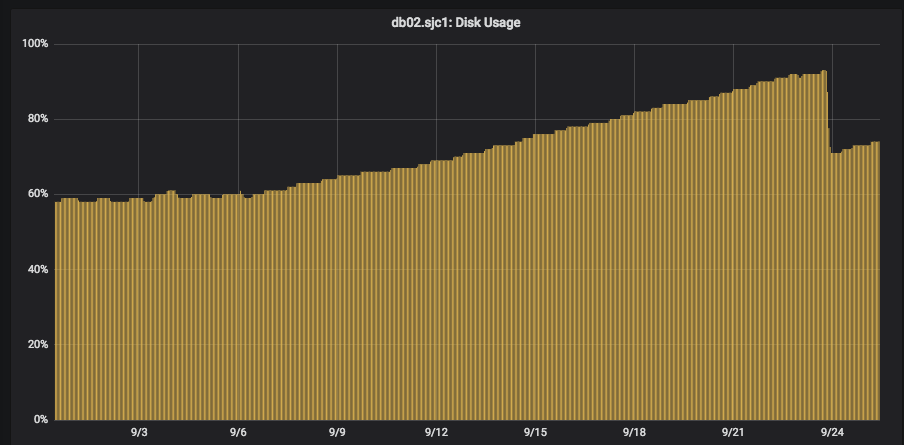 Our DB disk before the upgrade was hovering just below 60%. You can see the daily compaction (we have compaction restricted to off hours) take the disk space down a bit every day as it goes up. then on the night of September 6th we deployed CouchDB 2.2 and compaction just kinda stops happening. Disk space usage grew at a fairly steady pace and our alerts triggered at 85%. After a bunch of reviewing our configs, testing different configs, we were unable to get auto compaction to work. On the 23rd we ran a script that grabbed every DB, compared the disk size to data size, and then we manually compacted (using the _compact endpoint) the worst 1k DBs. This gave us back about 22% of our disk, but is not a long term solution. On one of our other DB servers that sees a lot of activity the _global_changes DB grew to about 85 GB in size. We manually triggered the compaction and it compacted down to 1 GB. We have been playing with a bunch of different values to see if something else works, but here are some of our current config settings: ``` [compaction_daemon] check_interval = 3600 min_file_size = 131072 (most our DBs are 500 MB in size) [compactions] _default = [{db_fragmentation, "40%"}, {view_fragmentation, "30%"}, {from, "03:00"}, {to, "09:00"}] ``` We did confirm CouchDB is reading the compactions settings correctly and that the compaction daemon is running. We do configure CouchDB to store all data on the /srv mount, but there are no symlinks. If there is any other information you need or that we can provide let us know. :) [ Full content available at: https://github.com/apache/couchdb/issues/1579 ] This message was relayed via gitbox.apache.org for [email protected]
{kind=link}