On Wed, Oct 14, 2009 at 1:03 PM, Anca Luca <[email protected]> wrote:
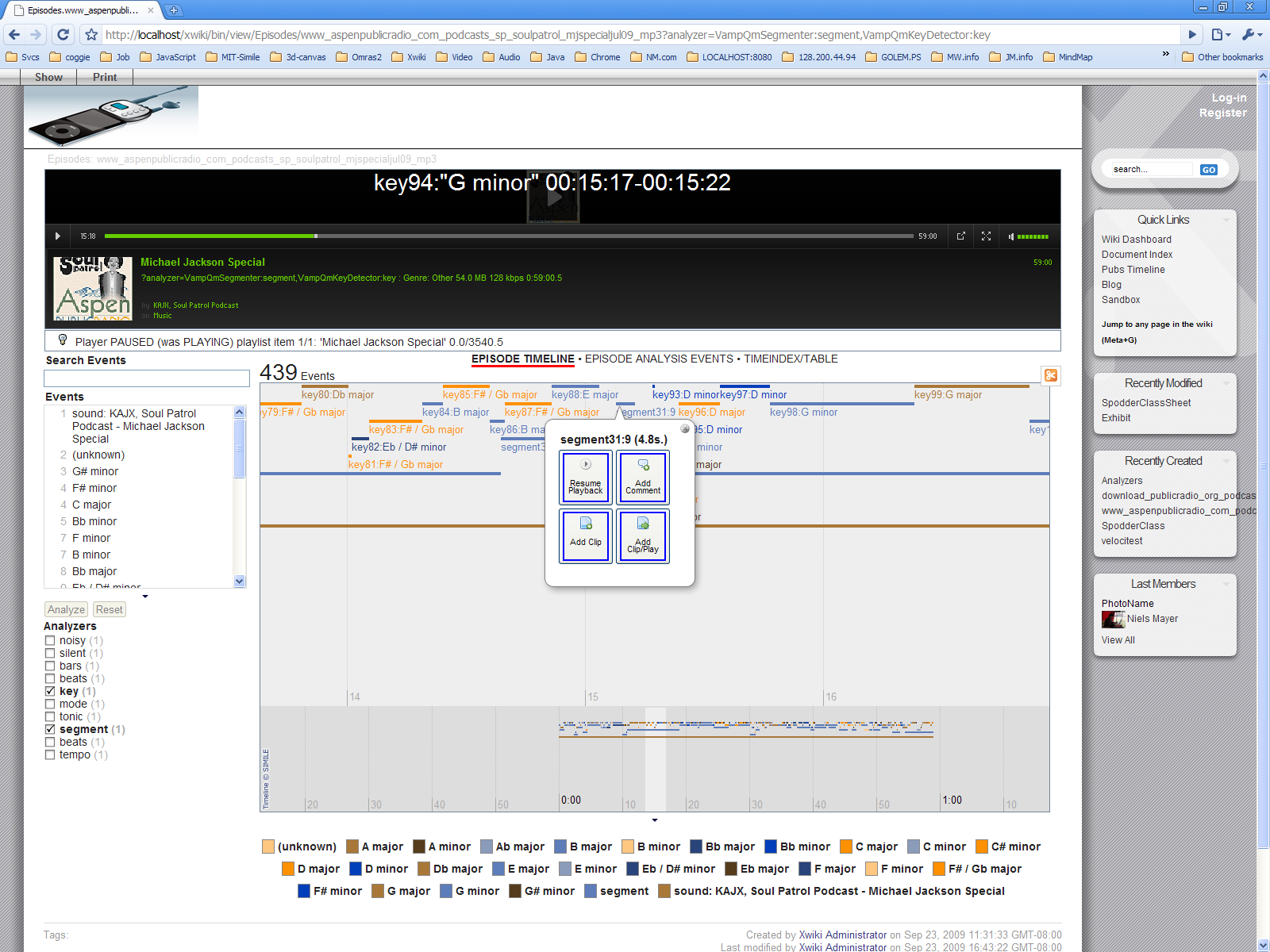
> * the backing annotation storage is based on components, currently with an > XWiki > objects implementation but a different service can be easily created (there > is > one implemented for Scribo annotations stored in RDF) > Where is the source for the xwiki-based annotation storage? Is this it? http://hg.nuxeo.org/sandbox/scribo/file/a9c5293ae8b3/scribo-xwiki-documentsource/src/main/java/ws/scribo/or some other part of http://hg.nuxeo.org/sandbox/scribo/summary ? Also, I request a simple feature: The addition of an extra, separate, string-property alongside every annotation. This would allow an arbitrary JSON structure (text) to be entered, containing additional information. As my interest is in semantic video and audio annotations, this kind of "back-link" would allow easy addition of structured information alongside an annotation. One of the issues with "annotation" in general is that there can be a variety of information one wants to supply. For example, in a structured document, one may want to annotate a named element, an unnamed-element positionally defined within a larger named structure, as well as an "extent" , in case the annotation doesn't correspond to an exact DOM structure. With streaming media, you will want to annotate with a start and a stop time, but also there may be the need for much additional information to be cross-referenced: for example, if using automatic indexing, structure or dialog detection in a video or audio stream, one will typically have a variety of other information one may need attached to any particular annotation. So in my need for annotation, I may want to include a JSON structure like this alongside every audio annotation: {"title": "Michael Jackson Special", "file": " http://www.aspenpublicradio.com/podcasts/sp/soulpatrol_mjspecialjul09.mp3";, "type": "sound", "link": "http://www.aspenpublicradio.org/support.php";, "tags": "Music", "image": "/Misc_icon_Media_Clip_1813.jpg", "author": "KAJX, Soul Patrol Podcast", "description": "Clip: segment32 start: 00:15:12.600 end: 00:19:01.400 length: 228.80000000000007s. analyzer=VampQmSegmenter:segment", "date": "2009-07-05T08:00:00Z", "start": 912.6, "duration": 228.80000000000007, "captions.file": "/xwiki/bin/view/Episodes/www_aspenpublicradio_com_podcasts_sp_soulpatrol_mjspecialjul09_mp3?xpage=plain&analyzer=VampQmSegmenter%3Asegment", "trainspodder.analysis": "VampQmSegmenter:segment"} This is from a real-world example: http://nielsmayer.com/trainspodder-prototype-2009-10-16.jpg ... This discussion is timely, as I'm now implementing the functionality behind the "add comment" button in the timeline popup bubble. Thus my interest in finding the source code and it's status for your annotations back-end for use outside your project.... Regarding Scribo, http://trueg.wordpress.com/2009/05/14/scribo-getting-natural-language-into-the-mix/suggests that the main focus is on natural language processing for documents, which is a laudable goal, as I spent some time in college writing in prolog for just this purpose and then spent 8 years in research working alongside NLP people. See before the web existed, we did "web" over email: http://nielsmayer.com/p93-shepherd.pdf and worried about semantic tagging of "intent", and automating conversation structures based on tracking conversational moves.... Today, however, a vast unexplored chunk of content and "intelligence" (and it's dialectic, stupidity) out there is in audio and video form. For that, semantic-audio technologies on which I base my work come in very handy, e.g. http://www.omras2.org/ . Is scribo intending to focus any effort on semantic tagging audio and video content? Given the shared platform, Xwiki, perhaps there's room for collaboration? Also, please note that there is a good deal of potential with the "idiot savant" technology such as that employed by http://www.google.com/voice . Excited to see things from the labs hit the mainstream, I installed my new free google voice "Call Me" button on my website... the performance of the transcription capabilities are less than stellar (it's own "annotation" animated beautifully in synchrony with the recorded message, dynamically underlining each spoken word in the transcript, many of which were completely wrong): *Niels Mayer* () .....11:10 PMHey this is a groovy tester google voice on my homepage. I wanna see how prizes, as I can release my number. What they're gonna do. I have keep number private sector so. Ohh no it's not facts of course it's not gonna do it. Anyways, it's all very excited and an call on the web and see what it actually and they call. -- Niels http://nielsmayer.com _______________________________________________ devs mailing list [email protected] http://lists.xwiki.org/mailman/listinfo/devs
{kind=link}