V5 is pretty trivial respin of v4, just rebased for some changes which landed to
the DRM scheduler since, plus some small tweaks.
As a summary, the new scheduling algorithm is insipired by the original Linux
CFS and so far no scheduling regressions have been found. There are improvements
in fairness and scheduling of interactive clients when running in parallel with
a heavy GPU load (for example Pierre-Eric has one viewperf medical test which
shows a nice improvement with amdgpu).
On the high level main advantages of the series are:
1. Scheduling quality - schedules better than FIFO, solves priority starvation.
2. Code simplification - no more multiple run queues and multiple algorithms.
3. Virtual GPU time based scheduling enables relatively simple addition
of a scheduling cgroup controller in the future.
There is a little bit more detailed write up on the motivation and results in
the form of a blog post which may be easier to read:
https://blogs.igalia.com/tursulin/fair-er-drm-gpu-scheduler/
First patches add some unit tests which allow for easy evaluation of scheduling
behaviour against different client submission patterns. From there onwards it is
hopefully a natural progression of cleanups, enablers, adding the fair policy,
and finally removing FIFO and RR and simplifying the code base due no more need
for multiple run queues.
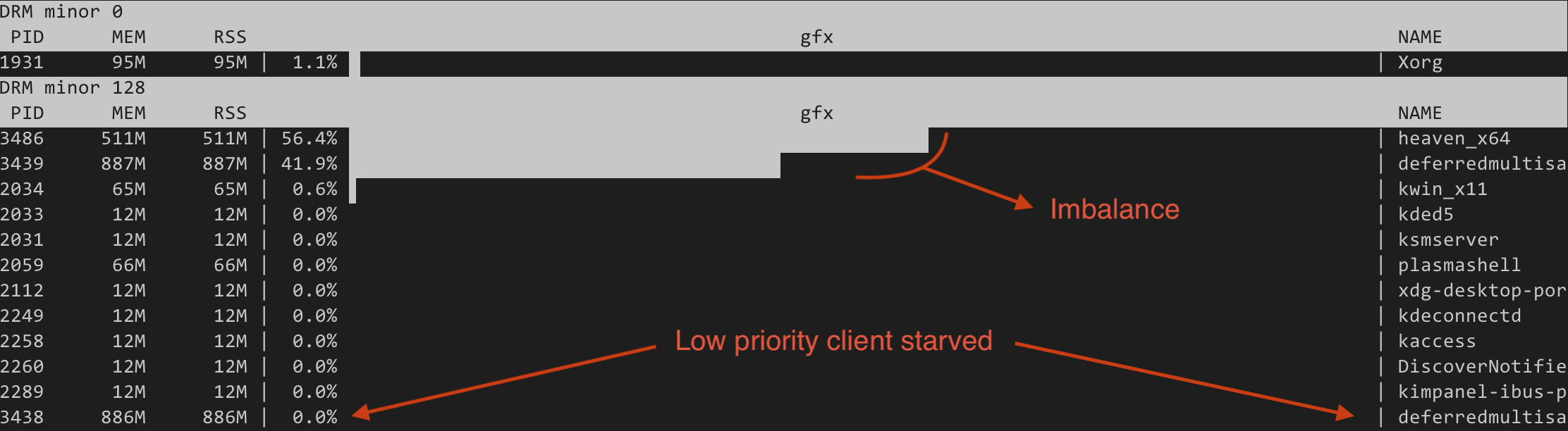
As a headline result I have tested three simultaneous clients on the Steam Deck:
One instance of a deferredmultisampling Vulkan demo running with low priority,
one normal priority instance of the same demo, and the Unigine Heaven benchmark.
With the FIFO scheduler we can see that the low priority client is completely
starved and the GPU time distribution between the other two clients is uneven:
https://people.igalia.com/tursulin/drm-sched-fair/fifo-starvation.png
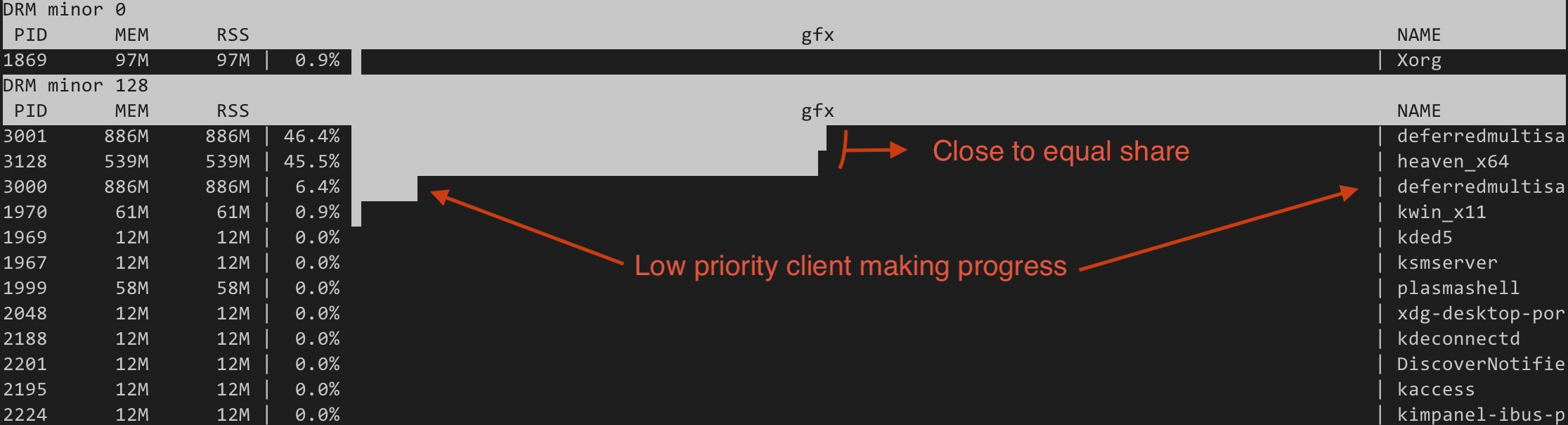
Switching to the fair scheduler, GPU time distribution is almost equal and the
low priority client does get a small share of the GPU:
https://people.igalia.com/tursulin/drm-sched-fair/fair-no-starvation.png
Moving onto the synthetic submission patterns, they are about two simultaneous
clients which broadly cover the following categories:
* Deep queue clients
* Hogs versus interactive
* Priority handling
Lets look at the results:
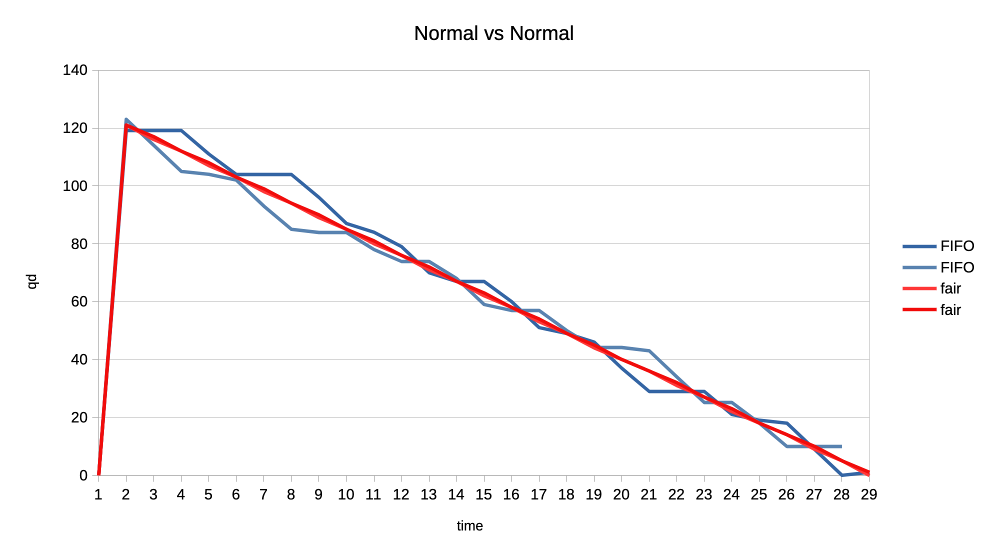
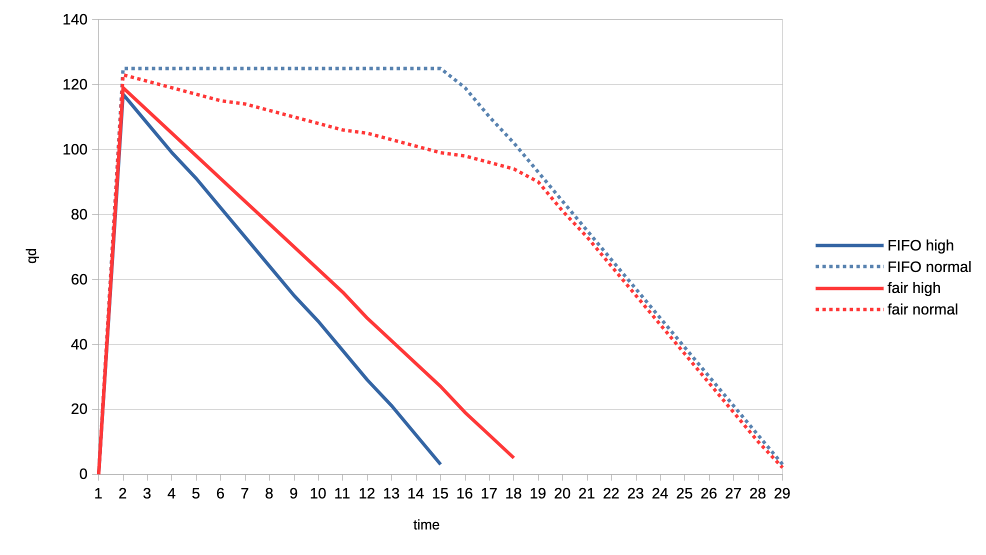
1. Two normal priority deep queue clients.
These ones submit one second worth of 8ms jobs. As fast as they can, no
dependencies etc. There is no difference in runtime between FIFO and fair but
the latter allows both clients to progress with work more evenly:
https://people.igalia.com/tursulin/drm-sched-fair/normal-normal.png
(X axis is time, Y is submitted queue-depth, hence lowering of qd corresponds
with work progress for both clients, tested with both schedulers separately.)
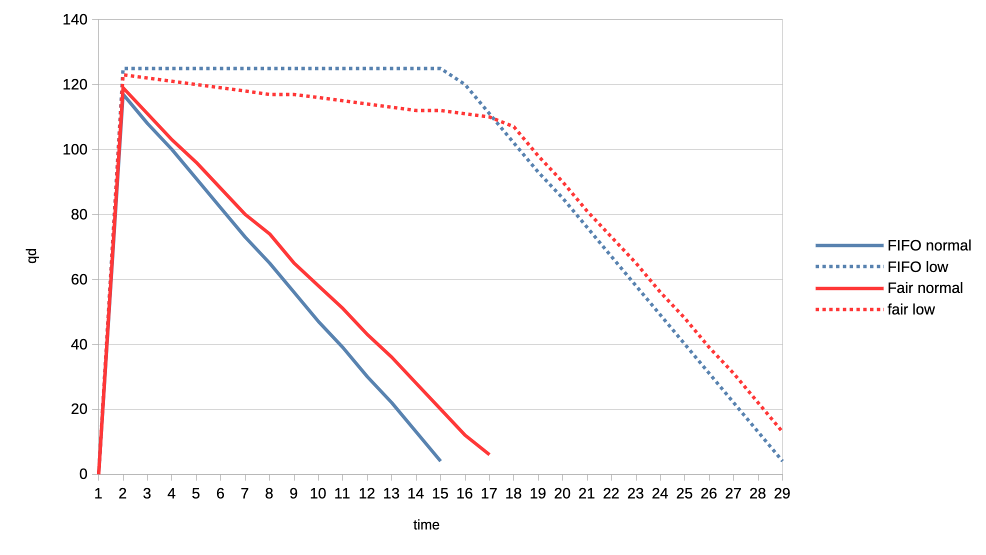
2. Same two clients but one is now low priority.
https://people.igalia.com/tursulin/drm-sched-fair/normal-low.png
Normal priority client is a solid line, low priority dotted. We can see how FIFO
completely starves the low priority client until the normal priority is fully
done. Only then the low priority client gets any GPU time.
In constrast, fair scheduler allows some GPU time to the low priority client.
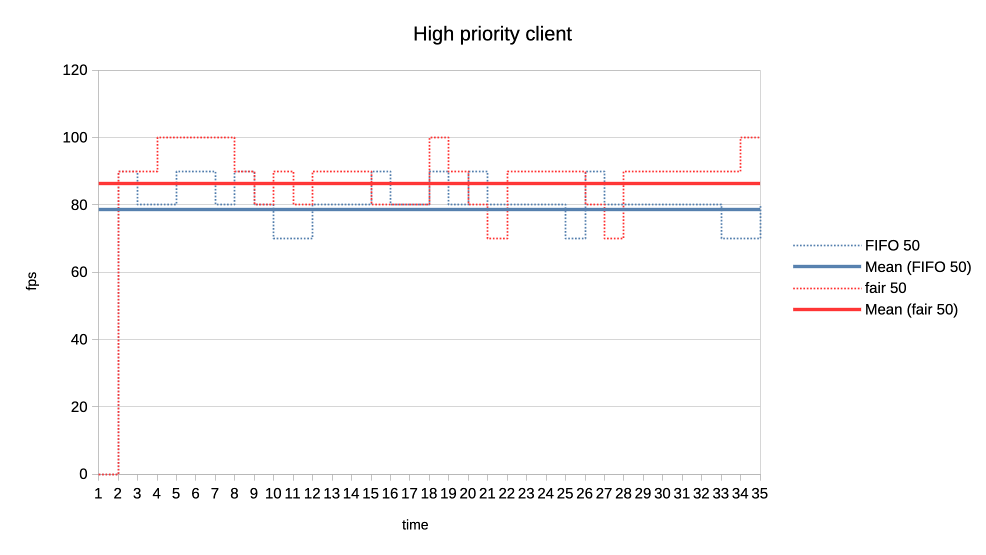
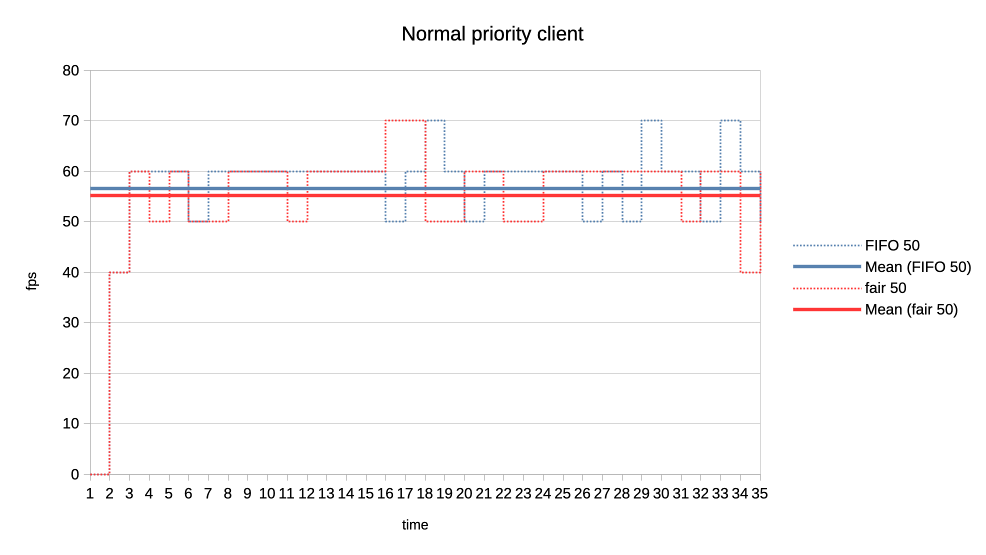
3. Same clients but now high versus normal priority.
Similar behaviour as in the previous one with normal a bit less de-prioritised
relative to high, than low was against normal.
https://people.igalia.com/tursulin/drm-sched-fair/high-normal.png
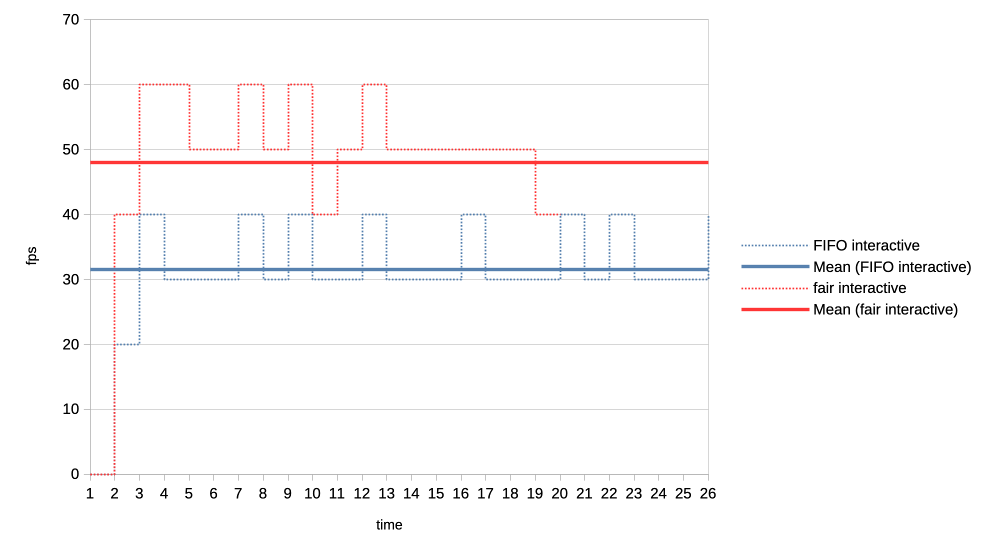
4. Heavy load vs interactive client.
Heavy client emits a 75% GPU load in the format of 3x 2.5ms jobs followed by a
2.5ms wait. Interactive client emits a 10% GPU load in the format of 1x 1ms job
followed by a 9ms wait.
This simulates an interactive graphical client used on top of a relatively heavy
background load but no GPU oversubscription.
Graphs show the interactive client only and from now on, instead of looking at
the client's queue depth, we look at its "fps".
https://people.igalia.com/tursulin/drm-sched-fair/heavy-interactive.png
We can see that fair scheduler allows a higher fps for the interactive client
which is good.
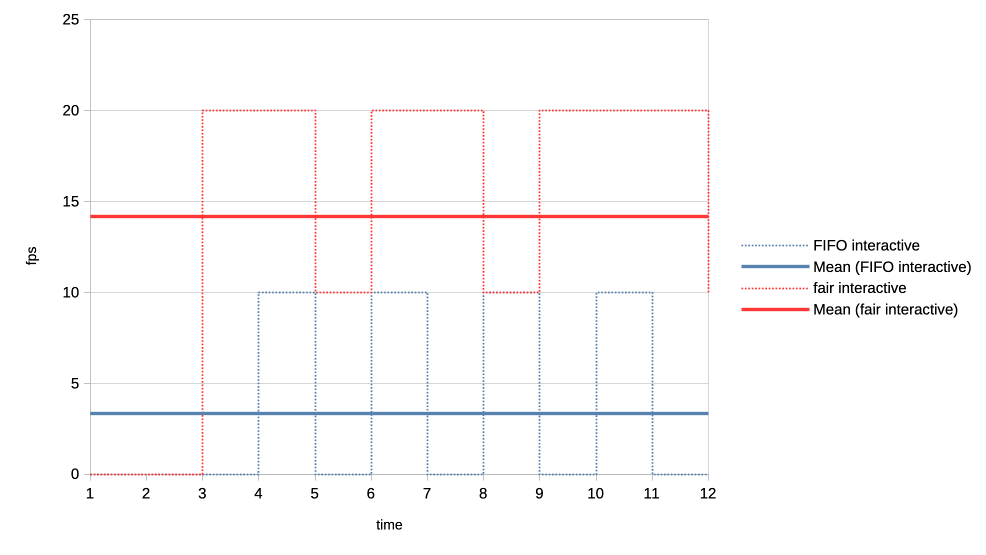
5. An even heavier load vs interactive client.
This one is oversubscribing the GPU by submitting 4x 50ms jobs and waiting for
only one microsecond before repeating the cycle. Interactive client is thje same
10% as above.
https://people.igalia.com/tursulin/drm-sched-fair/veryheavy-interactive.png
Here the difference is even more dramatic with fair scheduler enabling ~3x the
framerate for the interactive client.
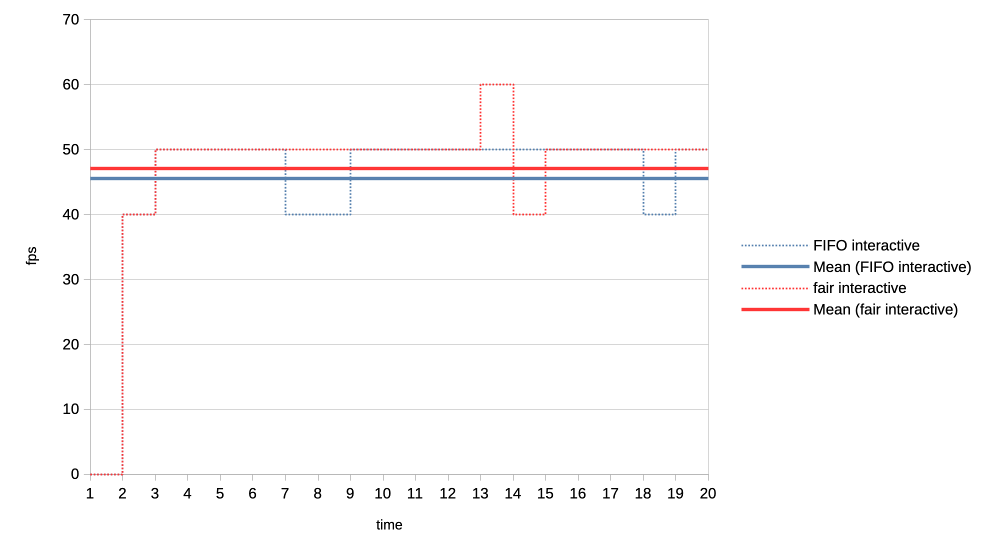
6. Low priority GPU hog versus heavy-interactive.
Low priority client: 3x 2.5ms jobs client followed by a 0.5ms wait.
Interactive client: 1x 0.5ms job followed by a 10ms wait.
https://people.igalia.com/tursulin/drm-sched-fair/lowhog-interactive.png
Slight win for the fair scheduler but could be just noise.
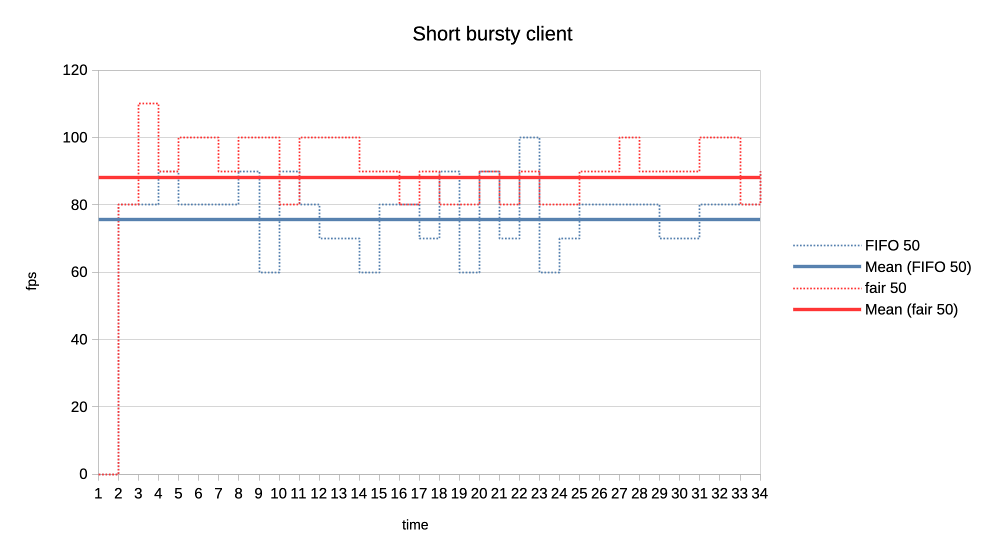
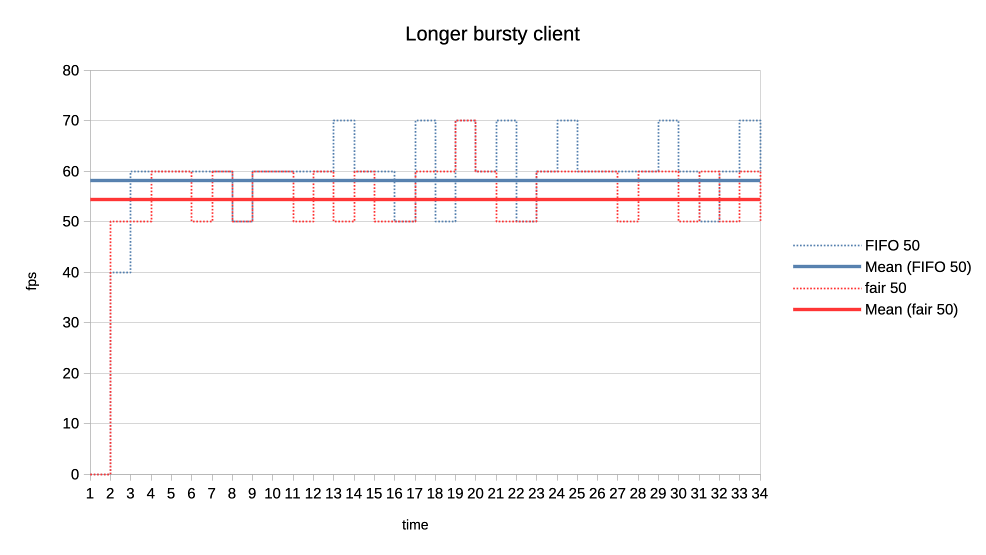
7. Last set of test scenarios will have three subgroups.
In all cases we have two interactive (synchronous, single job at a time) clients
with a 50% "duty cycle" GPU time usage.
Client 1: 1.5ms job + 1.5ms wait (aka short bursty)
Client 2: 2.5ms job + 2.5ms wait (aka long bursty)
a) Both normal priority.
https://people.igalia.com/tursulin/drm-sched-fair/5050-short.png
https://people.igalia.com/tursulin/drm-sched-fair/5050-long.png
Both schedulers favour the higher frequency duty cycle with fair giving it a
little bit more which should be good for interactivity.
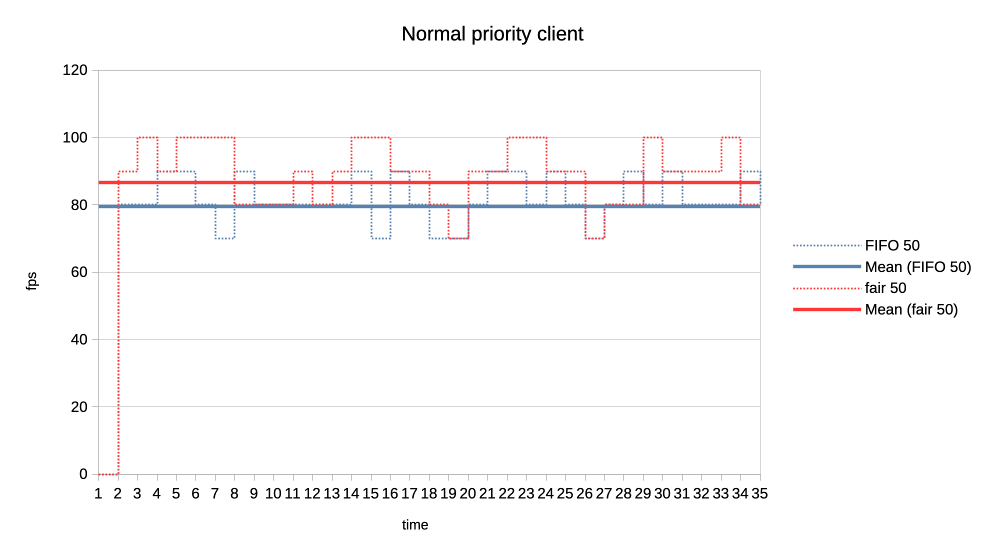
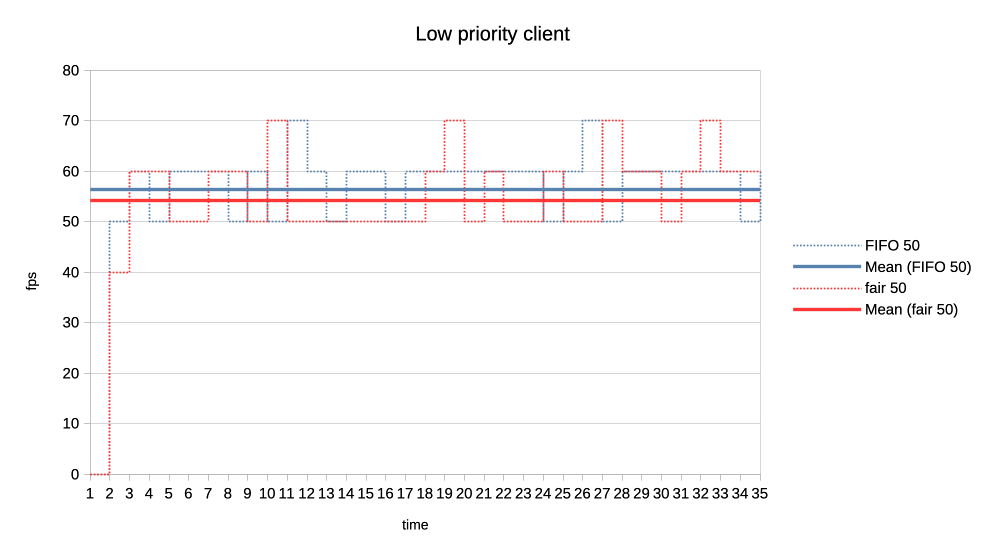
b) Normal vs low priority.
https://people.igalia.com/tursulin/drm-sched-fair/5050-normal-low-normal.png
https://people.igalia.com/tursulin/drm-sched-fair/5050-normal-low-low.png
Fair scheduler gives a bit more GPU time to the normal priority client which is
again good.
c) High vs normal priority.
https://people.igalia.com/tursulin/drm-sched-fair/5050-high-normal-high.png
https://people.igalia.com/tursulin/drm-sched-fair/5050-high-normal-normal.png
Again, fair scheduler gives a bit more share to the higher priority client.
As before, I am looking for feedback, ideas for what other kinds of submission
scenarios to test, testing on different GPUs and of course reviews.
v2:
* Fixed many rebase errors.
* Added some new patches.
* Dropped single shot dependecy handling.
v3:
* Added scheduling quality unit tests.
* Refined a tiny bit by adding some fairness.
* Dropped a few patches for now.
v4:
* Replaced deadline with fair!
* Refined scheduling quality unit tests.
* Pulled one cleanup patch earlier.
* Fixed "drm/sched: Avoid double re-lock on the job free path".
v5:
* Rebase on top of latest upstream DRM scheduler changes.
* Kerneldoc fixup.
* Improve commit message justification for one patch. (Philipp)
* Add comment in drm_sched_alloc_wq. (Christian)
Cc: Christian König <christian.koe...@amd.com>
Cc: Danilo Krummrich <d...@kernel.org>
CC: Leo Liu <leo....@amd.com>
Cc: Matthew Brost <matthew.br...@intel.com>
Cc: Philipp Stanner <pha...@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-pra...@amd.com>
Cc: Michel Dänzer <michel.daen...@mailbox.org>
Tvrtko Ursulin (16):
drm/sched: Add some scheduling quality unit tests
drm/sched: Add some more scheduling quality unit tests
drm/sched: De-clutter drm_sched_init
drm/sched: Avoid double re-lock on the job free path
drm/sched: Consolidate drm_sched_job_timedout
drm/sched: Consolidate drm_sched_rq_select_entity_rr
drm/sched: Implement RR via FIFO
drm/sched: Consolidate entity run queue management
drm/sched: Move run queue related code into a separate file
drm/sched: Free all finished jobs at once
drm/sched: Account entity GPU time
drm/sched: Remove idle entity from tree
drm/sched: Add fair scheduling policy
drm/sched: Remove FIFO and RR and simplify to a single run queue
drm/sched: Queue all free credits in one worker invocation
drm/sched: Embed run queue singleton into the scheduler
drivers/gpu/drm/amd/amdgpu/amdgpu_cs.c | 6 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_job.c | 27 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_job.h | 5 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_trace.h | 8 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_vm_sdma.c | 8 +-
drivers/gpu/drm/amd/amdgpu/amdgpu_xcp.c | 8 +-
drivers/gpu/drm/scheduler/Makefile | 2 +-
drivers/gpu/drm/scheduler/sched_entity.c | 121 +--
drivers/gpu/drm/scheduler/sched_fence.c | 2 +-
drivers/gpu/drm/scheduler/sched_internal.h | 120 ++-
drivers/gpu/drm/scheduler/sched_main.c | 566 +++---------
drivers/gpu/drm/scheduler/sched_rq.c | 214 +++++
drivers/gpu/drm/scheduler/tests/Makefile | 3 +-
.../gpu/drm/scheduler/tests/tests_scheduler.c | 815 ++++++++++++++++++
include/drm/gpu_scheduler.h | 27 +-
15 files changed, 1356 insertions(+), 576 deletions(-)
create mode 100644 drivers/gpu/drm/scheduler/sched_rq.c
create mode 100644 drivers/gpu/drm/scheduler/tests/tests_scheduler.c
--
2.48.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}