On 30/07/2025 08:56, Philipp Stanner wrote:
On Mon, 2025-07-28 at 12:14 +0100, Tvrtko Ursulin wrote:
On 28/07/2025 10:28, Pierre-Eric Pelloux-Prayer wrote:
Le 24/07/2025 à 16:19, Tvrtko Ursulin a écrit :
GPUs generally don't implement preemption and DRM scheduler definitely
does not support it at the front end scheduling level. This means
execution quanta can be quite long and is controlled by userspace,
consequence of which is picking the "wrong" entity to run can have a
larger negative effect than it would have with a virtual runtime based
CPU
scheduler.
Another important consideration is that rendering clients often have
shallow submission queues, meaning they will be entering and exiting the
scheduler's runnable queue often.
Relevant scenario here is what happens when an entity re-joins the
runnable queue with other entities already present. One cornerstone of
the
virtual runtime algorithm is to let it re-join at the head and depend on
the virtual runtime accounting to sort out the order after an execution
quanta or two.
However, as explained above, this may not work fully reliably in the GPU
world. Entity could always get to overtake the existing entities, or not,
depending on the submission order and rbtree equal key insertion
behaviour.
We can break this latching by adding some randomness for this specific
corner case.
If an entity is re-joining the runnable queue, was head of the queue the
last time it got picked, and there is an already queued different entity
of an equal scheduling priority, we can break the tie by randomly
choosing
the execution order between the two.
For randomness we implement a simple driver global boolean which selects
whether new entity will be first or not. Because the boolean is global
and
shared between all the run queues and entities, its actual effect can be
loosely called random. Under the assumption it will not always be the
same
entity which is re-joining the queue under these circumstances.
Another way to look at this is that it is adding a little bit of limited
random round-robin behaviour to the fair scheduling algorithm.
Net effect is a significant improvemnt to the scheduling unit tests which
check the scheduling quality for the interactive client running in
parallel with GPU hogs.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursu...@igalia.com>
Cc: Christian König <christian.koe...@amd.com>
Cc: Danilo Krummrich <d...@kernel.org>
Cc: Matthew Brost <matthew.br...@intel.com>
Cc: Philipp Stanner <pha...@kernel.org>
Cc: Pierre-Eric Pelloux-Prayer <pierre-eric.pelloux-pra...@amd.com>
---
drivers/gpu/drm/scheduler/sched_rq.c | 10 ++++++++++
1 file changed, 10 insertions(+)
diff --git a/drivers/gpu/drm/scheduler/sched_rq.c b/drivers/gpu/drm/
scheduler/sched_rq.c
index d16ee3ee3653..087a6bdbb824 100644
--- a/drivers/gpu/drm/scheduler/sched_rq.c
+++ b/drivers/gpu/drm/scheduler/sched_rq.c
@@ -147,6 +147,16 @@ drm_sched_entity_restore_vruntime(struct
drm_sched_entity *entity,
* Higher priority can go first.
*/
vruntime = -us_to_ktime(rq_prio - prio);
+ } else {
+ static const int shuffle[2] = { -100, 100 };
+ static bool r = 0;
+
+ /*
+ * For equal priority apply some randomness to break
+ * latching caused by submission patterns.
+ */
+ vruntime = shuffle[r];
+ r ^= 1;
I don't understand why this is needed at all?
I suppose this is related to how drm_sched_entity_save_vruntime saves a
relative vruntime (= entity rejoins with a 0 runtime would be impossible
otherwise) but I don't understand this either.
Two things (and a bit more) to explain here for the record. And as
agreed off-line I need to add some more code comments for this are in
the next respin.
First the saving of "vruntime - min_runtime" when entity exits the
run-queue.
That is a core CFS concept AFAIU which enables the relative position of
the entity to be restored once it re-enters the rq.
It only applies on the scenario when the picked entity was not the head
of the queue, due the actual head being not runnable due a dependency.
If the picked entity then leaves the queue and re-joins, this relative
vruntime is used to put it back where it was relative to the unready
entity (which may have became ready by now and so it needs to be picked
next and not overtaken so easily.)
I'm afraid I also don't get it completely. So you're saying that with
this jitter-mechanism we can preserve the relative order of entities?
But the actual patch title says that it's about breaking such patterns,
or isn't it? "Break submission patterns"
Maybe you can help improve my understanding by us reversing the
question:
If that jitter-mechanism is dropped, what will be the negative
consequence?
Some workloads would suffer. Or to better say, make smaller gains
compared to the current FIFO. With this they can bridge the gap to RR
much more.
Entities with similar vruntimes would always run in the same order,
correct? So the patch is not so much about GPU time fairness, but about
response / delay fairness.
Not similar vruntimes, but it is about the _identical_. This identical
case happens by CFS design when idle entity (re-)joins the run queue. It
inherits the current min vruntime of the rq and from then on CFS relies
on timeslicing (preemption) to balance them out. And because with GPUs
time slices are long, even controlled by userspace because preemption is
not universally present (not at all with DRM scheduler at the frontend
level), making a wrong choice of what to run first can hurt us much more
than in the CPU world.
So for example when two entities enter the rq 1ns apart, and the second
one was picked from head of the queue in its last activity period, the
new pick order is determined by the rbtree traversal order for nodes
with identical keys. Whether in practice or by contract that ends up
being FIFO. Ie. above entities which entered the rq 1ns apart will
always run in FIFO order.
And FIFO is quite bad with light to medium usage interactive clients
running in parallel to GPU hogs. Regardless if the hog as a queue depth
or more than one job deep, or just happened to submit its long single
job 1ns earlier than the interactive client.
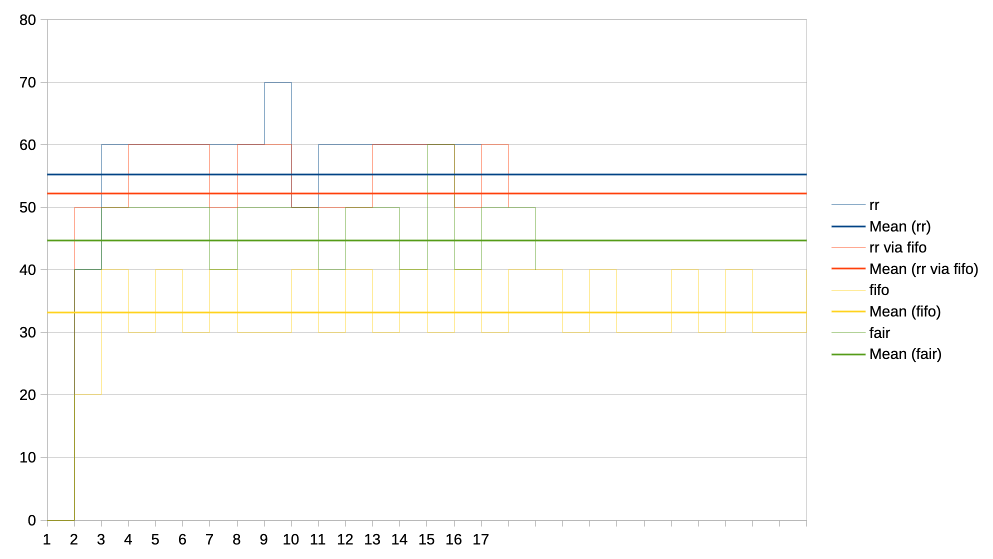
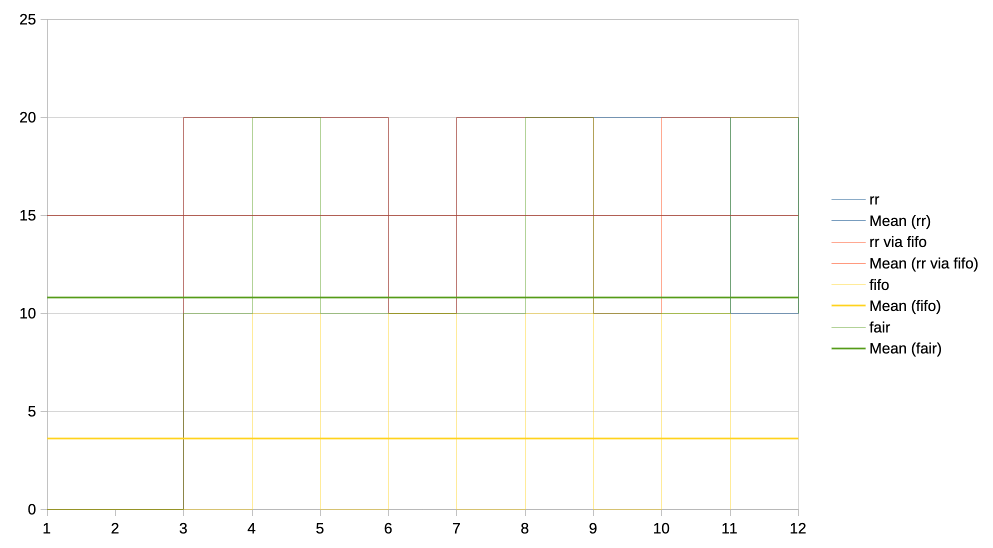
This patch therefore mixes things up a bit for this specific case and
that seems to work quite well in practice:
https://people.igalia.com/tursulin/drm-sched-fair/4-heavy-vs-interactive.png
https://people.igalia.com/tursulin/drm-sched-fair/4-very-heavy-vs-interactive.png
With two competing clients it ends up a bit like RR (again, for this
specific set of pre-requisites, not RR for everyone and everything),
where the two alternate as to who gets to run first.
With more than two clients it all becomes much more random (compared to
alternating) because the "randomizer" is a one bit toggle shared across
the whole system. So different GPU engines, different GPUs, different
entities, they all toggle it and combined with the time domain I think
is safer from any latching behaviour induced by submission timings,
patterns or interactions with the CPU scheduler.
Regards,
Tvrtko
It has to be the relative vruntime that is preserved, ie. entity which
re-enters cannot simply keep its previous vruntime, since by then that
could lag significantly behind the vruntime of other active entities,
which in turn would mean the re-joining entity could be head of the
queue for a long time.
Second part is the special case from the quoted patch and that only
applies to entities which are re-joining the queue after having been
picked from the head _and_ there is another entity in the rq.
By the nature of the CFS algorithm the re-joining entity continues with
the vruntime assigned from the current rq min_vruntime. Which puts two
entities with the same vruntime at the head of the queue and the actual
picking order influenced by the submit order (FIFO) and rbtree sort
order (did not check). But in any case it is not desirable for all the
description of GPU scheduling weaknesses from the commit text (this patch).
For this special case there are three sub-paths:
1. Re-joining entity is higher scheduling prio -> we pull its vruntime
a tiny bit ahead of the min_vruntime so it runs first.
2. Lower re-joining prio -> the opposite of the above - we explicitly
prevent it overtaking the higher priority head.
3. Equal prio -> apply some randomness as to which one runs first.
Idea being avoidance of any "latching" of the execution order based on
submission patterns. Which kind of applies a little bit of
round/random-robin for this very specific case of equal priority entity
re-joining at the top of the queue.
Regards,
Tvrtko
{kind=link}
{kind=link}