Justin to be honest I am not 100% sure and don't have time to check the source code, but I believe the main difference with scroll requests is that the data nodes keep some resources around and keep track of which documents have been returned. It's not clear from the documentation what the interaction with the client nodes is in this case. I'm sure someone more knowledgeable can chime in here.
On Tuesday, 3 March 2015 17:55:54 UTC, Justin Zhu wrote: > > Graham, thanks for the info. Just to confirm, is this what happens for a > scroll request and not a paged search? > > On Monday, March 2, 2015 at 11:08:13 PM UTC-8, Graham Lenton wrote: >> >> Oops should have said: >> >> 407,500 * 15 * 1 == 6,112,500 >> >> .. but you get the idea .. >> >> G >> >> On Tuesday, 3 March 2015 07:01:19 UTC, Graham Lenton wrote: >>> >>> Justin - also keep an eye on your client nodes - they will be doing >>> quite a bit of garbage collection, which will only increase as paging gets >>> deeper. >>> >>> Bear in mind that your client node has to reduce (paging_depth * >>> number_of_shards * number_of_indices) down to number_of_hits required for >>> each and every request. >>> >>> So retrieving results 400,000 to 407,500 from a single index with 15 >>> shards will give the client node 400,000 * 15 * 1 == 6,000,000 results to >>> crunch down to your 7,500. That will result in a great deal of GC. >>> >>> If this is the case, possible strategies to improve matters are: >>> >>> - keep the client heap size as small as possible to make GC happen more >>> frequently - this depends on the type of requests and concurrency you have. >>> - reindex with less shards if possible - experiment with a single shard >>> with your data on a single node of your hardware to find how many docs >>> _you_ can fit in a shard before performance hits the wall. >>> - ensure your application uses all 3 client nodes to spread the load, >>> and increase the number of client nodes if possible >>> - have more than one index - if you can segment the query in a sensible >>> way e.g. time series data >>> >>> G >>> >>> On Tuesday, 3 March 2015 02:21:37 UTC, Justin Zhu wrote: >>>> >>>> Thanks Jörg. The query does no sorting or scoring. So the child/parent >>>> cost must be high -- any ideas on ways to improve look ups -- would >>>> docvalues or upgrading to 1.4 help? >>>> >>>> Thanks >>>> On Saturday, February 28, 2015 at 5:46:59 AM UTC-8, Jörg Prante wrote: >>>>> >>>>> No idea, except that it could be there is extensive sorting or scoring >>>>> at work. This would mean the whole result set has to be iterated/computed >>>>> to the point from where it should scroll. Also the parent/child structure >>>>> construction is expensive which may be not optimal for scan/scroll as you >>>>> already noted. >>>>> >>>>> Jörg >>>>> >>>>> On Sat, Feb 28, 2015 at 8:48 AM, Justin Zhu <[email protected]> >>>>> wrote: >>>>> >>>>>> Good question. The request has several filters on child types which >>>>>> may have dozens to hundreds of documents per parent document. >>>>>> >>>>>> It could just be the request is quite complex at calculating the >>>>>> documents. The odd factor, is the query is quick at the beginning then >>>>>> times out after about 500K documents. >>>>>> >>>>>> The query fetches 7500 documents each go (15 shards, 500 per shard). >>>>>> Typical timing >>>>>> 2s >>>>>> 3s >>>>>> 2s >>>>>> ... >>>>>> @400K docs scrolled >>>>>> 10s >>>>>> 12s >>>>>> @500K docs scrolled >>>>>> timeout (30 seconds) >>>>>> ... >>>>>> recovers >>>>>> 16s -- returns 6500 results instead. >>>>>> >>>>>> Any idea on why as you scroll deeper, the response time slows any why >>>>>> several shards might stop returning results? >>>>>> >>>>>> >>>>>> >>>>>> >>>>>> On Friday, February 27, 2015 at 8:43:26 AM UTC-8, Jörg Prante wrote: >>>>>>> >>>>>>> How does the scan/scroll request look like? >>>>>>> >>>>>>> Jörg >>>>>>> >>>>>>> On Fri, Feb 27, 2015 at 5:38 PM, Justin Zhu <[email protected]> >>>>>>> wrote: >>>>>>> >>>>>>>> We have a 15 node cluster, 9 data nodes with 18gb ram, 3 master, 3 >>>>>>>> client, 12 cpus running 1.3.2. When doing a scroll on an index of 20gb >>>>>>>> for >>>>>>>> 800K documents, each document is 1K we're seeing cpu jump to 30% to >>>>>>>> 90% on >>>>>>>> nodes with primary a shard. Index and other search quests are pretty >>>>>>>> low. >>>>>>>> >>>>>>>> Our scroll settings >>>>>>>> timeout: 30 seconds >>>>>>>> scroll size per shard: 500. >>>>>>>> >>>>>>>> -- Each scroll request returns 2500 results and takes 10-15 seconds >>>>>>>> per request. >>>>>>>> - iowait is 0.1% >>>>>>>> >>>>>>>> Any help appreciated. Details below: >>>>>>>> >>>>>>>> Hot threads dump >>>>>>>> >>>>>>>> 95.4% (476.9ms out of 500ms) cpu usage by thread >>>>>>>> 'elasticsearch[esd1][search][T#5]' >>>>>>>> 5/10 snapshots sharing following 37 elements >>>>>>>> org.apache.lucene.util.packed.MonotonicAppendingLongBuffer. >>>>>>>> get(MonotonicAppendingLongBuffer.java:70) >>>>>>>> org.apache.lucene.util.packed.AbstractAppendingLongBuffer. >>>>>>>> get(AbstractAppendingLongBuffer.java:102) >>>>>>>> org.apache.lucene.index.XOrdinalMap$2.get(XOrdinalMap. >>>>>>>> java:260) >>>>>>>> org.elasticsearch.index.fielddata.ordinals. >>>>>>>> GlobalOrdinalMapping.getGlobalOrd(GlobalOrdinalMapping.java:54) >>>>>>>> org.elasticsearch.index.fielddata.ordinals. >>>>>>>> GlobalOrdinalMapping.getOrd(GlobalOrdinalMapping.java:63) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> ChildrenConstantScoreQuery$ParentOrdCollector.collect( >>>>>>>> ChildrenConstantScoreQuery.java:269) >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> scoreAll(Weight.java:193) >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> score(Weight.java:163) >>>>>>>> org.apache.lucene.search.BulkScorer.score(BulkScorer. >>>>>>>> java:35) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:621) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:309) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> ChildrenConstantScoreQuery.createWeight(ChildrenConstantScoreQuery. >>>>>>>> java:120) >>>>>>>> org.apache.lucene.search.IndexSearcher. >>>>>>>> createNormalizedWeight(IndexSearcher.java:684) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> createNormalizedWeight(ContextIndexSearcher.java:132) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> CustomQueryWrappingFilter.getDocIdSet(CustomQueryWrappingFilter. >>>>>>>> java:72) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search. >>>>>>>> ApplyAcceptedDocsFilter.getDocIdSet(ApplyAcceptedDocsFilter.java: >>>>>>>> 46) >>>>>>>> org.apache.lucene.search.ConstantScoreQuery$ >>>>>>>> ConstantWeight.scorer(ConstantScoreQuery.java:157) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> RandomAccessFilterStrategy.filteredScorer(FilteredQuery.java:547) >>>>>>>> org.apache.lucene.search.FilteredQuery$1.scorer( >>>>>>>> FilteredQuery.java:136) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> RandomAccessFilterStrategy.filteredScorer(FilteredQuery.java:542) >>>>>>>> org.apache.lucene.search.FilteredQuery$FilterStrategy. >>>>>>>> filteredBulkScorer(FilteredQuery.java:504) >>>>>>>> org.apache.lucene.search.FilteredQuery$1.bulkScorer( >>>>>>>> FilteredQuery.java:150) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:618) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> search(ContextIndexSearcher.java:175) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:309) >>>>>>>> org.elasticsearch.search.scan.ScanContext.execute( >>>>>>>> ScanContext.java:52) >>>>>>>> org.elasticsearch.search.query.QueryPhase.execute( >>>>>>>> QueryPhase.java:119) >>>>>>>> org.elasticsearch.search.SearchService.executeScan( >>>>>>>> SearchService.java:237) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchScanScrollTransportHandl >>>>>>>> er.messageReceived(SearchServiceTransportAction.java:856) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchScanScrollTransportHandl >>>>>>>> er.messageReceived(SearchServiceTransportAction.java:845) >>>>>>>> org.elasticsearch.transport.netty.MessageChannelHandler$ >>>>>>>> RequestHandler.run(MessageChannelHandler.java:275) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.runWorker( >>>>>>>> ThreadPoolExecutor.java:1145) >>>>>>>> java.util.concurrent.ThreadPoolExecutor$Worker.run( >>>>>>>> ThreadPoolExecutor.java:615) >>>>>>>> java.lang.Thread.run(Thread.java:744) >>>>>>>> 3/10 snapshots sharing following 35 elements >>>>>>>> org.apache.lucene.search.FilteredDocIdSetIterator.nextDoc( >>>>>>>> FilteredDocIdSetIterator.java:59) >>>>>>>> org.apache.lucene.search.FilteredQuery$LeapFrogScorer. >>>>>>>> primaryNext(FilteredQuery.java:290) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> PrimaryAdvancedLeapFrogScorer.primaryNext(FilteredQuery.java:340) >>>>>>>> org.apache.lucene.search.FilteredQuery$LeapFrogScorer. >>>>>>>> nextDoc(FilteredQuery.java:285) >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> scoreAll(Weight.java:192) >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> score(Weight.java:163) >>>>>>>> org.apache.lucene.search.BulkScorer.score(BulkScorer. >>>>>>>> java:35) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:621) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:309) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> ChildrenConstantScoreQuery.createWeight(ChildrenConstantScoreQuery. >>>>>>>> java:120) >>>>>>>> org.apache.lucene.search.IndexSearcher. >>>>>>>> createNormalizedWeight(IndexSearcher.java:684) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> createNormalizedWeight(ContextIndexSearcher.java:132) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> CustomQueryWrappingFilter.getDocIdSet(CustomQueryWrappingFilter. >>>>>>>> java:72) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search. >>>>>>>> ApplyAcceptedDocsFilter.getDocIdSet(ApplyAcceptedDocsFilter.java: >>>>>>>> 46) >>>>>>>> org.apache.lucene.search.ConstantScoreQuery$ >>>>>>>> ConstantWeight.scorer(ConstantScoreQuery.java:157) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> RandomAccessFilterStrategy.filteredScorer(FilteredQuery.java:547) >>>>>>>> org.apache.lucene.search.FilteredQuery$1.scorer( >>>>>>>> FilteredQuery.java:136) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> RandomAccessFilterStrategy.filteredScorer(FilteredQuery.java:542) >>>>>>>> org.apache.lucene.search.FilteredQuery$FilterStrategy. >>>>>>>> filteredBulkScorer(FilteredQuery.java:504) >>>>>>>> org.apache.lucene.search.FilteredQuery$1.bulkScorer( >>>>>>>> FilteredQuery.java:150) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:618) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> search(ContextIndexSearcher.java:175) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:309) >>>>>>>> org.elasticsearch.search.scan.ScanContext.execute( >>>>>>>> ScanContext.java:52) >>>>>>>> org.elasticsearch.search.query.QueryPhase.execute( >>>>>>>> QueryPhase.java:119) >>>>>>>> org.elasticsearch.search.SearchService.executeScan( >>>>>>>> SearchService.java:237) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchScanScrollTransportHandl >>>>>>>> er.messageReceived(SearchServiceTransportAction.java:856) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchScanScrollTransportHandl >>>>>>>> er.messageReceived(SearchServiceTransportAction.java:845) >>>>>>>> org.elasticsearch.transport.netty.MessageChannelHandler$ >>>>>>>> RequestHandler.run(MessageChannelHandler.java:275) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.runWorker( >>>>>>>> ThreadPoolExecutor.java:1145) >>>>>>>> java.util.concurrent.ThreadPoolExecutor$Worker.run( >>>>>>>> ThreadPoolExecutor.java:615) >>>>>>>> java.lang.Thread.run(Thread.java:744) >>>>>>>> 2/10 snapshots sharing following 30 elements >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> score(Weight.java:163) >>>>>>>> org.apache.lucene.search.BulkScorer.score(BulkScorer. >>>>>>>> java:35) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:621) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:309) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> ChildrenConstantScoreQuery.createWeight(ChildrenConstantScoreQuery. >>>>>>>> java:120) >>>>>>>> org.apache.lucene.search.IndexSearcher. >>>>>>>> createNormalizedWeight(IndexSearcher.java:684) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> createNormalizedWeight(ContextIndexSearcher.java:132) >>>>>>>> org.elasticsearch.index.search.child. >>>>>>>> CustomQueryWrappingFilter.getDocIdSet(CustomQueryWrappingFilter. >>>>>>>> java:72) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search.XBooleanFilter. >>>>>>>> getDocIdSet(XBooleanFilter.java:83) >>>>>>>> org.elasticsearch.common.lucene.search. >>>>>>>> ApplyAcceptedDocsFilter.getDocIdSet(ApplyAcceptedDocsFilter.java: >>>>>>>> 46) >>>>>>>> org.apache.lucene.search.ConstantScoreQuery$ >>>>>>>> ConstantWeight.scorer(ConstantScoreQuery.java:157) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> RandomAccessFilterStrategy.filteredScorer(FilteredQuery.java:547) >>>>>>>> org.apache.lucene.search.FilteredQuery$1.scorer( >>>>>>>> FilteredQuery.java:136) >>>>>>>> org.apache.lucene.search.FilteredQuery$ >>>>>>>> RandomAccessFilterStrategy.filteredScorer(FilteredQuery.java:542) >>>>>>>> org.apache.lucene.search.FilteredQuery$FilterStrategy. >>>>>>>> filteredBulkScorer(FilteredQuery.java:504) >>>>>>>> org.apache.lucene.search.FilteredQuery$1.bulkScorer( >>>>>>>> FilteredQuery.java:150) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:618) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> search(ContextIndexSearcher.java:175) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:309) >>>>>>>> org.elasticsearch.search.scan.ScanContext.execute( >>>>>>>> ScanContext.java:52) >>>>>>>> org.elasticsearch.search.query.QueryPhase.execute( >>>>>>>> QueryPhase.java:119) >>>>>>>> org.elasticsearch.search.SearchService.executeScan( >>>>>>>> SearchService.java:237) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchScanScrollTransportHandl >>>>>>>> er.messageReceived(SearchServiceTransportAction.java:856) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchScanScrollTransportHandl >>>>>>>> er.messageReceived(SearchServiceTransportAction.java:845) >>>>>>>> org.elasticsearch.transport.netty.MessageChannelHandler$ >>>>>>>> RequestHandler.run(MessageChannelHandler.java:275) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.runWorker( >>>>>>>> ThreadPoolExecutor.java:1145) >>>>>>>> java.util.concurrent.ThreadPoolExecutor$Worker.run( >>>>>>>> ThreadPoolExecutor.java:615) >>>>>>>> java.lang.Thread.run(Thread.java:744) >>>>>>>> >>>>>>>> 58.8% (294.1ms out of 500ms) cpu usage by thread >>>>>>>> 'elasticsearch[esd1][search][T#3]' >>>>>>>> 3/10 snapshots sharing following 19 elements >>>>>>>> org.apache.lucene.search.FilteredDocIdSetIterator.nextDoc( >>>>>>>> FilteredDocIdSetIterator.java:60) >>>>>>>> org.apache.lucene.search.ConstantScoreQuery$ >>>>>>>> ConstantScorer.nextDoc(ConstantScoreQuery.java:257) >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> scoreAll(Weight.java:192) >>>>>>>> org.apache.lucene.search.Weight$DefaultBulkScorer. >>>>>>>> score(Weight.java:163) >>>>>>>> org.apache.lucene.search.BulkScorer.score(BulkScorer. >>>>>>>> java:35) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:621) >>>>>>>> org.elasticsearch.search.internal.ContextIndexSearcher. >>>>>>>> search(ContextIndexSearcher.java:175) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:581) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:533) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:510) >>>>>>>> org.apache.lucene.search.IndexSearcher.search( >>>>>>>> IndexSearcher.java:345) >>>>>>>> org.elasticsearch.search.query.QueryPhase.execute( >>>>>>>> QueryPhase.java:149) >>>>>>>> org.elasticsearch.search.SearchService.executeQueryPhase( >>>>>>>> SearchService.java:261) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchQueryTransportHandler. >>>>>>>> messageReceived(SearchServiceTransportAction.java:688) >>>>>>>> org.elasticsearch.search.action. >>>>>>>> SearchServiceTransportAction$SearchQueryTransportHandler. >>>>>>>> messageReceived(SearchServiceTransportAction.java:677) >>>>>>>> org.elasticsearch.transport.netty.MessageChannelHandler$ >>>>>>>> RequestHandler.run(MessageChannelHandler.java:275) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.runWorker( >>>>>>>> ThreadPoolExecutor.java:1145) >>>>>>>> java.util.concurrent.ThreadPoolExecutor$Worker.run( >>>>>>>> ThreadPoolExecutor.java:615) >>>>>>>> java.lang.Thread.run(Thread.java:744) >>>>>>>> 7/10 snapshots sharing following 10 elements >>>>>>>> sun.misc.Unsafe.park(Native Method) >>>>>>>> java.util.concurrent.locks.LockSupport.park(LockSupport. >>>>>>>> java:186) >>>>>>>> java.util.concurrent.LinkedTransferQueue.awaitMatch( >>>>>>>> LinkedTransferQueue.java:735) >>>>>>>> java.util.concurrent.LinkedTransferQueue.xfer( >>>>>>>> LinkedTransferQueue.java:644) >>>>>>>> java.util.concurrent.LinkedTransferQueue.take( >>>>>>>> LinkedTransferQueue.java:1137) >>>>>>>> org.elasticsearch.common.util.concurrent. >>>>>>>> SizeBlockingQueue.take(SizeBlockingQueue.java:162) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.getTask( >>>>>>>> ThreadPoolExecutor.java:1068) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.runWorker( >>>>>>>> ThreadPoolExecutor.java:1130) >>>>>>>> java.util.concurrent.ThreadPoolExecutor$Worker.run( >>>>>>>> ThreadPoolExecutor.java:615) >>>>>>>> java.lang.Thread.run(Thread.java:744) >>>>>>>> >>>>>>>> 41.0% (204.8ms out of 500ms) cpu usage by thread >>>>>>>> 'elasticsearch[esd1][search][T#6]' >>>>>>>> 10/10 snapshots sharing following 10 elements >>>>>>>> sun.misc.Unsafe.park(Native Method) >>>>>>>> java.util.concurrent.locks.LockSupport.park(LockSupport. >>>>>>>> java:186) >>>>>>>> java.util.concurrent.LinkedTransferQueue.awaitMatch( >>>>>>>> LinkedTransferQueue.java:735) >>>>>>>> java.util.concurrent.LinkedTransferQueue.xfer( >>>>>>>> LinkedTransferQueue.java:644) >>>>>>>> java.util.concurrent.LinkedTransferQueue.take( >>>>>>>> LinkedTransferQueue.java:1137) >>>>>>>> org.elasticsearch.common.util.concurrent. >>>>>>>> SizeBlockingQueue.take(SizeBlockingQueue.java:162) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.getTask( >>>>>>>> ThreadPoolExecutor.java:1068) >>>>>>>> java.util.concurrent.ThreadPoolExecutor.runWorker( >>>>>>>> ThreadPoolExecutor.java:1130) >>>>>>>> java.util.concurrent.ThreadPoolExecutor$Worker.run( >>>>>>>> ThreadPoolExecutor.java:615) >>>>>>>> java.lang.Thread.run(Thread.java:744) >>>>>>>> >>>>>>>> >>>>>>>> Bigdesk graphs >>>>>>>> >>>>>>>> >>>>>>>> <https://lh5.googleusercontent.com/-czxx8fTd_Oo/VPCcfre2mcI/AAAAAAAAAe8/v3fk9toDaF8/s1600/Bigdesk.png> >>>>>>>> \ >>>>>>>> >>>>>>>> >>>>>>>> <https://lh4.googleusercontent.com/-au5U3a3Qjew/VPCcztClm_I/AAAAAAAAAfE/o5qnPrTYRxQ/s1600/Bigdesk.png> >>>>>>>> >>>>>>>> >>>>>>>> >>>>>>>> -- >>>>>>>> You received this message because you are subscribed to the Google >>>>>>>> Groups "elasticsearch" group. >>>>>>>> To unsubscribe from this group and stop receiving emails from it, >>>>>>>> send an email to [email protected]. >>>>>>>> To view this discussion on the web visit >>>>>>>> https://groups.google.com/d/msgid/elasticsearch/72fb97ee- >>>>>>>> a02f-48e3-b217-cd3e15cc24e3%40googlegroups.com >>>>>>>> <https://groups.google.com/d/msgid/elasticsearch/72fb97ee-a02f-48e3-b217-cd3e15cc24e3%40googlegroups.com?utm_medium=email&utm_source=footer> >>>>>>>> . >>>>>>>> For more options, visit https://groups.google.com/d/optout. >>>>>>>> >>>>>>> >>>>>>> -- >>>>>> You received this message because you are subscribed to the Google >>>>>> Groups "elasticsearch" group. >>>>>> To unsubscribe from this group and stop receiving emails from it, >>>>>> send an email to [email protected]. >>>>>> To view this discussion on the web visit >>>>>> https://groups.google.com/d/msgid/elasticsearch/9f8a64a8-5711-48d0-b2ad-d3472f442935%40googlegroups.com >>>>>> >>>>>> <https://groups.google.com/d/msgid/elasticsearch/9f8a64a8-5711-48d0-b2ad-d3472f442935%40googlegroups.com?utm_medium=email&utm_source=footer> >>>>>> . >>>>>> >>>>>> For more options, visit https://groups.google.com/d/optout. >>>>>> >>>>> >>>>> -- You received this message because you are subscribed to the Google Groups "elasticsearch" group. To unsubscribe from this group and stop receiving emails from it, send an email to [email protected]. To view this discussion on the web visit https://groups.google.com/d/msgid/elasticsearch/eb0322fb-64ec-4df5-a49d-e5635cc39fc7%40googlegroups.com. For more options, visit https://groups.google.com/d/optout.
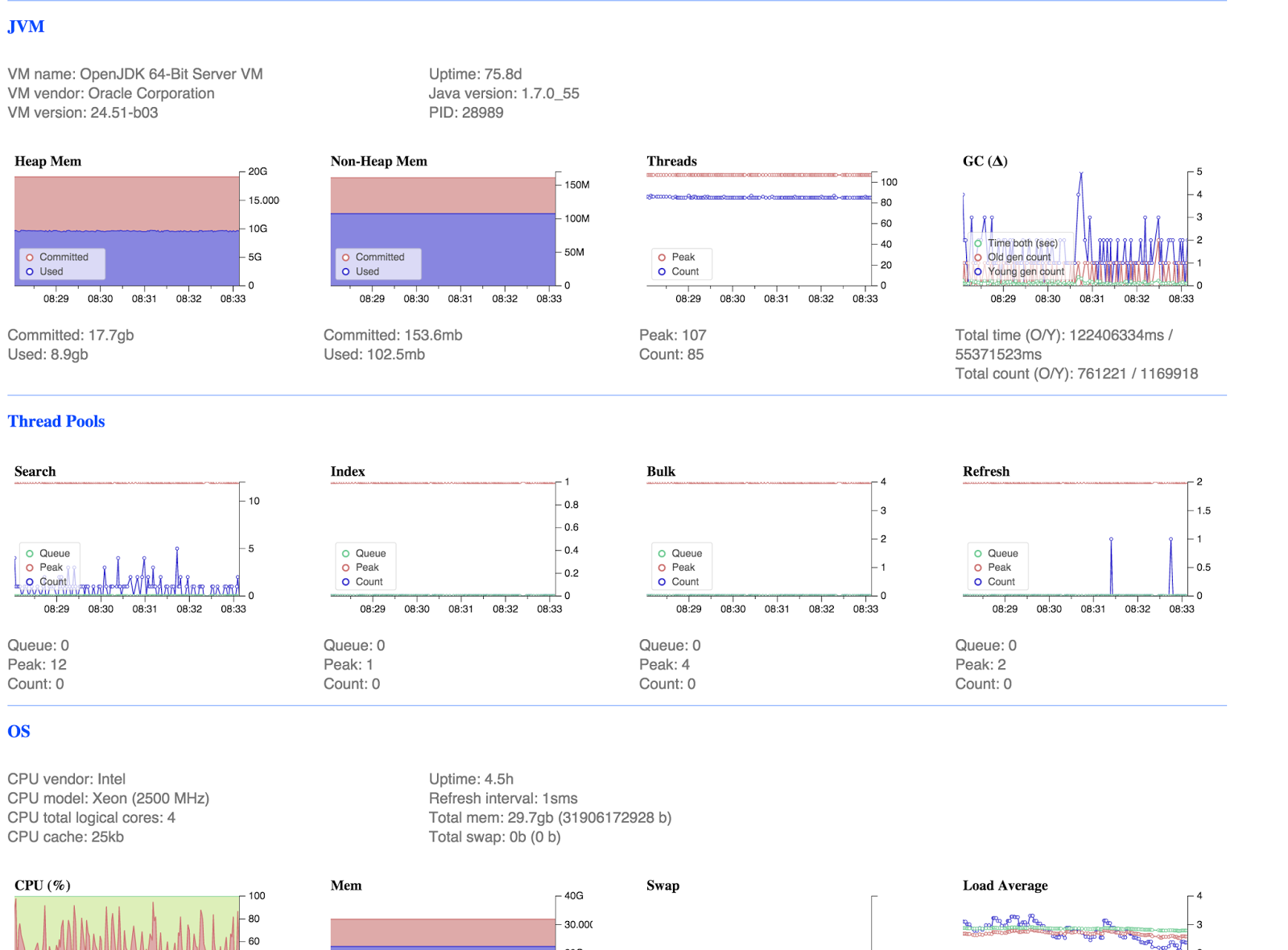{kind=link}
{kind=link}