zhangbutao commented on code in PR #3276:
URL: https://github.com/apache/hive/pull/3276#discussion_r957951934
##########
standalone-metastore/metastore-server/src/main/java/org/apache/hadoop/hive/metastore/dataconnector/jdbc/MySQLConnectorProvider.java:
##########
@@ -90,10 +90,20 @@ protected String getDataType(String dbDataType, int size) {
// map any db specific types here.
switch (dbDataType.toLowerCase())
{
+ case "bit":
+ return toHiveBitType(size);
default:
mappedType = ColumnType.VOID_TYPE_NAME;
break;
}
return mappedType;
}
+
+ private String toHiveBitType(int size) {
+ if (size <= 1) {
+ return ColumnType.BOOLEAN_TYPE_NAME;
+ } else {
+ return ColumnType.BIGINT_TYPE_NAME;
Review Comment:
> option 1 above not possible where we set the hive.sql.query to include
like a select bin(column_name) ... on the table containing bit type columns?
@nrg4878 I have tried set the hive.sql.query to include query like` select
bin(id) from testmysqlbit,` and it worked as expected. That is to say,
hive.sql.query can push down MySQL's native query to remote MySQL datasouce,
and we can get MySQL's bit datatype values using a visible hive's bigint type
or hive's string type.
Step to test:
1. create jdbc-mapping table with **hive.sql.query** in hive:
` CREATE EXTERNAL TABLE jdbc_testmysqlbit_with_query`
`(`
` id bigint`
`)`
`STORED BY 'org.apache.hive.storage.jdbc.JdbcStorageHandler'`
`TBLPROPERTIES (`
`"hive.sql.database.type" = "MYSQL",`
`"hive.sql.jdbc.driver" = "com.mysql.jdbc.Driver",`
`"hive.sql.jdbc.url" = "jdbc:mysql://localhost:3306/testdb",`
`"hive.sql.dbcp.username" = "user",`
`"hive.sql.dbcp.password" = "passwd",`
`"hive.sql.dbcp.maxActive" = "1",`
`"hive.sql.query" = "select bin(id) from testmysqlbit"`
`);`
2. `select * from jdbc_testmysqlbit_with_query;` using hive beeline:
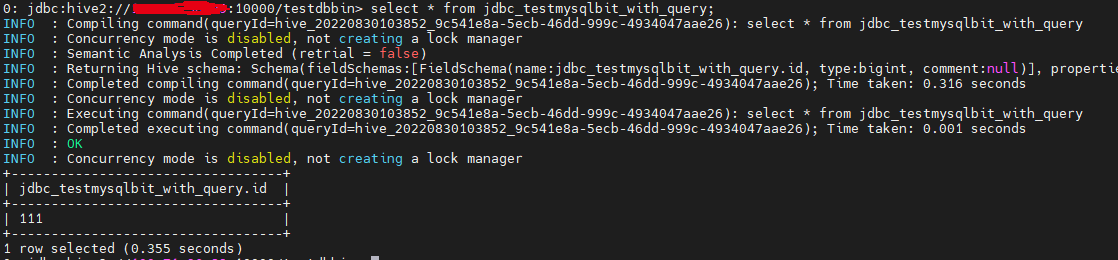
However, one concern is that the _**hive.sql.query**_ is a fixed values and
can not be rewrited with more optimized pushdown computation on top of the
table. As the doc descripted:
https://cwiki.apache.org/confluence/display/Hive/JDBC+Storage+Handler#JDBCStorageHandler-ComputationPushdown
> Computation pushdown will only happen when the jdbc table is defined by
“hive.sql.table”. Hive will rewrite the data source with a “hive.sql.query”
property with more computation on top of the table. In the above example, mysql
will run the query and retrieve the join result, rather than fetch both tables
and do the join in Hive.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}