maartenbreddels commented on pull request #7449: URL: https://github.com/apache/arrow/pull/7449#issuecomment-645276441
I used valgrind/callgrind to see how where time spent: 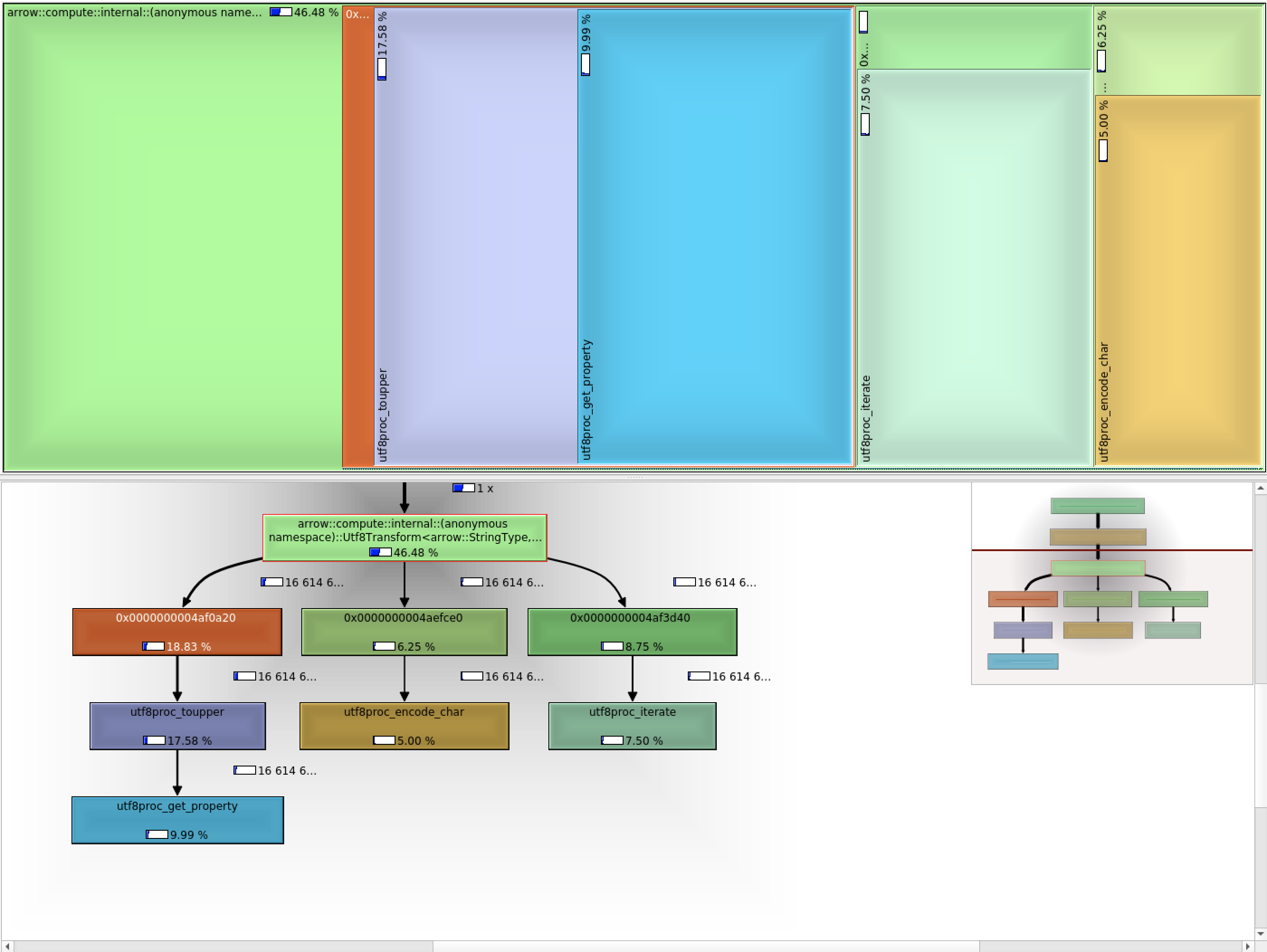 I wanted to compare that to unilib, but all calls get inlined directly (making that not visible). Using unilib, it's almost 3x faster now compared to utf8proc (disabling the fast ascii path, so it should be compared to the items_per_second =5M/s above): ``` Utf8Lower 74023038 ns 74000707 ns 9 bytes_per_second=268.173M/s items_per_second=14.1698M/s Utf8Upper 76741459 ns 76715981 ns 9 bytes_per_second=258.681M/s items_per_second=13.6683M/s ``` This is about 2x faster compared to Vaex (again, ignoring the fast ascii path). The fact that utf8proc is not inline-able (4 calls per codepoint) will explain part of the overhead already. As an experiment, I make sure the calls to unicode's encode/append are not inlined, and that brings back the performance to: ``` Utf8Lower 131853749 ns 131822537 ns 5 bytes_per_second=150.543M/s items_per_second=7.95445M/s Utf8Upper 134526167 ns 134487477 ns 5 bytes_per_second=147.56M/s items_per_second=7.79683M/s ``` Confirming call overhead plays a role. Also, utf8proc contains information we don't care about (such as which direction text goes), explaining probably why utf8proc is bigger (300kb vs 120kb compiled). ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}