zhixingheyi-tian commented on PR #14353: URL: https://github.com/apache/arrow/pull/14353#issuecomment-1346200212
> Hi @zhixingheyi-tian, sorry this hasn't gotten reviewer attention for a while. Are you still interested in working on this? > > Would you mind rebasing and cleaning up any commented code? > > In addition, I noticed there aren't any benchmarks for binary or string types in either of these two benchmark files: > > * `src/parquet/arrow/reader_writer_benchmark.cc` > * `src/parquet/parquet_encoding_benchmark.cc` > > We'll want some benchmarks in order to evaluate the changes. If you add those, then you can compare benchmarks locally like so: > > ```shell > BUILD_DIR=cpp/path/to/build > > archery benchmark run $BUILD_DIR \ > --suite-filter=parquet-arrow-reader-writer-benchmark \ > --output=contender.json > > git checkout master # Or some ref that has benchmarks but not your changes > > archery benchmark run $BUILD_DIR \ > --suite-filter=parquet-arrow-reader-writer-benchmark \ > --output=baseline.json > > archery benchmark diff contender.json baseline.json > ``` Hi @wjones127 Good idea to show performance. How to add Binary/String benchmark in *benchmark.cc, I noticed currently Arrow benchmark testing had not support generating random binary data. In my local server end-2-end performance testing: `Generate one parquet file with dictionary-encoding (100M rows, 10 Cols) Run parquet with one thread on CentOS 7.6` 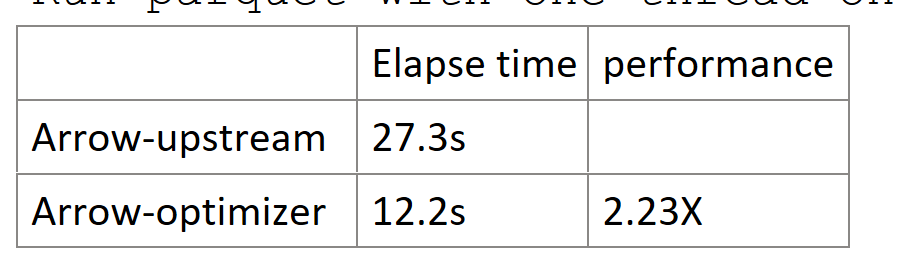 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}