Dandandan opened a new pull request #9834: URL: https://github.com/apache/arrow/pull/9834
I did some comparisons with different batch sized with TCP-H on SF=1 in memory / 16 partitions. We chose a higher batch_size earlier as DF had some problems with smaller batch sizes (in hash join, but also because it missed the CoalesceBatches node). Smaller batch sizes have some performance benefit: more (possible) parallelism for smaller tables, batches are available sooner (in `CoalesceBatches`), etc. Also, memory usage can be reduced. But now it seems a value around 8000 is the sweet spot, only query 1 is faster with a slightly smaller batch size. 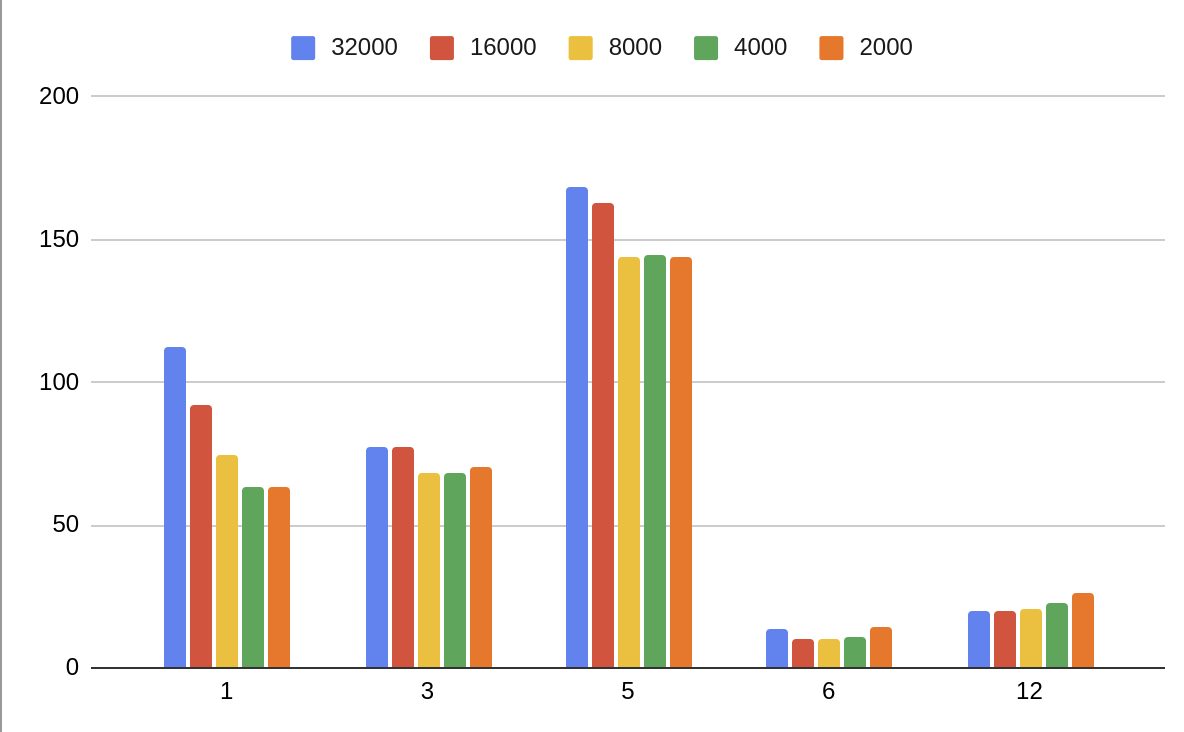 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}