lidavidm commented on pull request #9656: URL: https://github.com/apache/arrow/pull/9656#issuecomment-828507033
I instrumented a bit of the scanner and took a look at pre-buffering's effect on local file performance, to see if I could figure out why it seems detrimental. Without pre-buffering locally, we're utilizing the CPU thread pool (nearly) fully. (I'm not sure why one thread seems to receive little/no work, but I didn't fully instrument the scanner and perhaps it's assembling the table or something like that.) 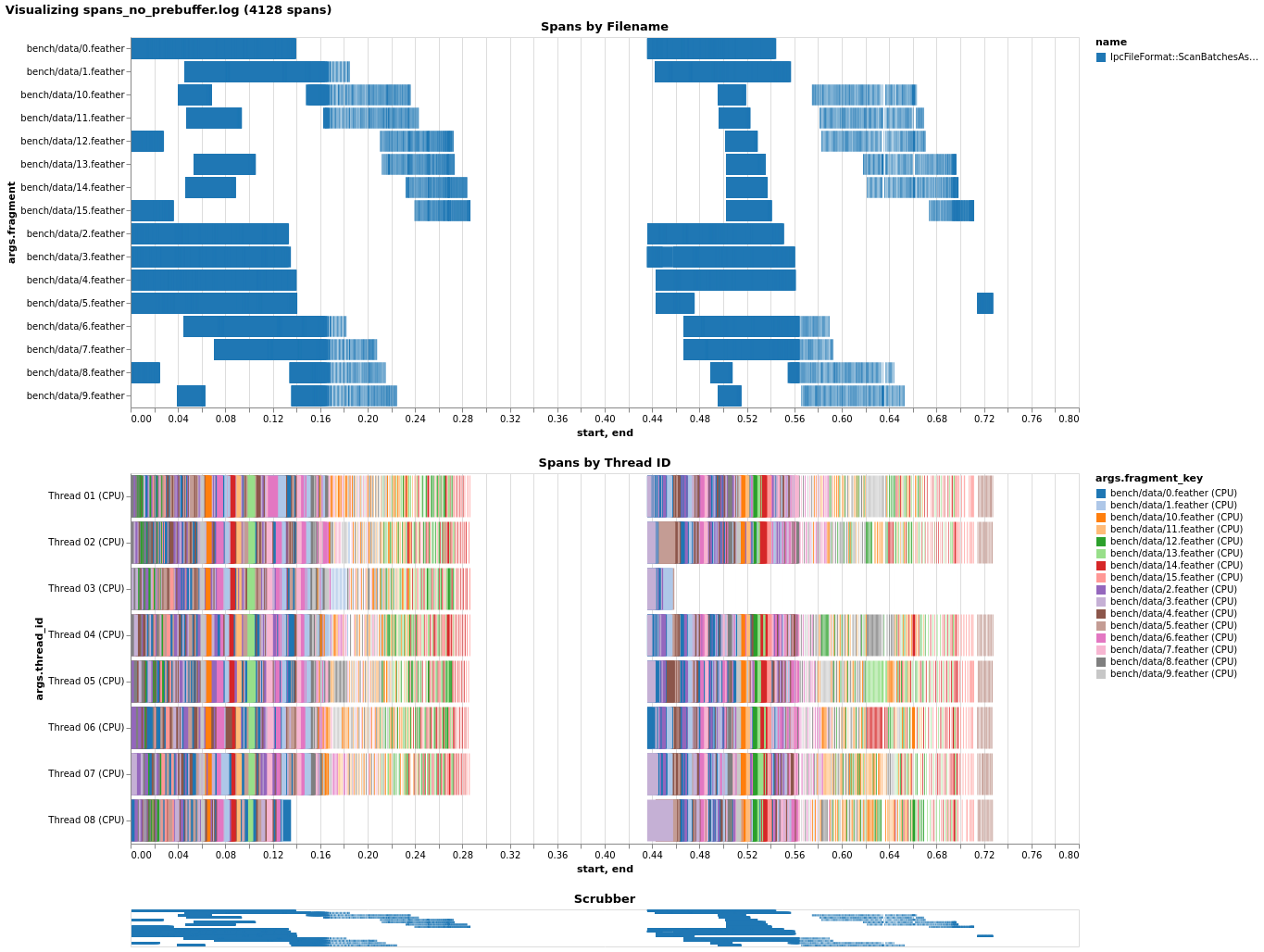 Just enabling pre-buffer causes a slowdown, as it appears nearly all work gets forced onto a single thread! 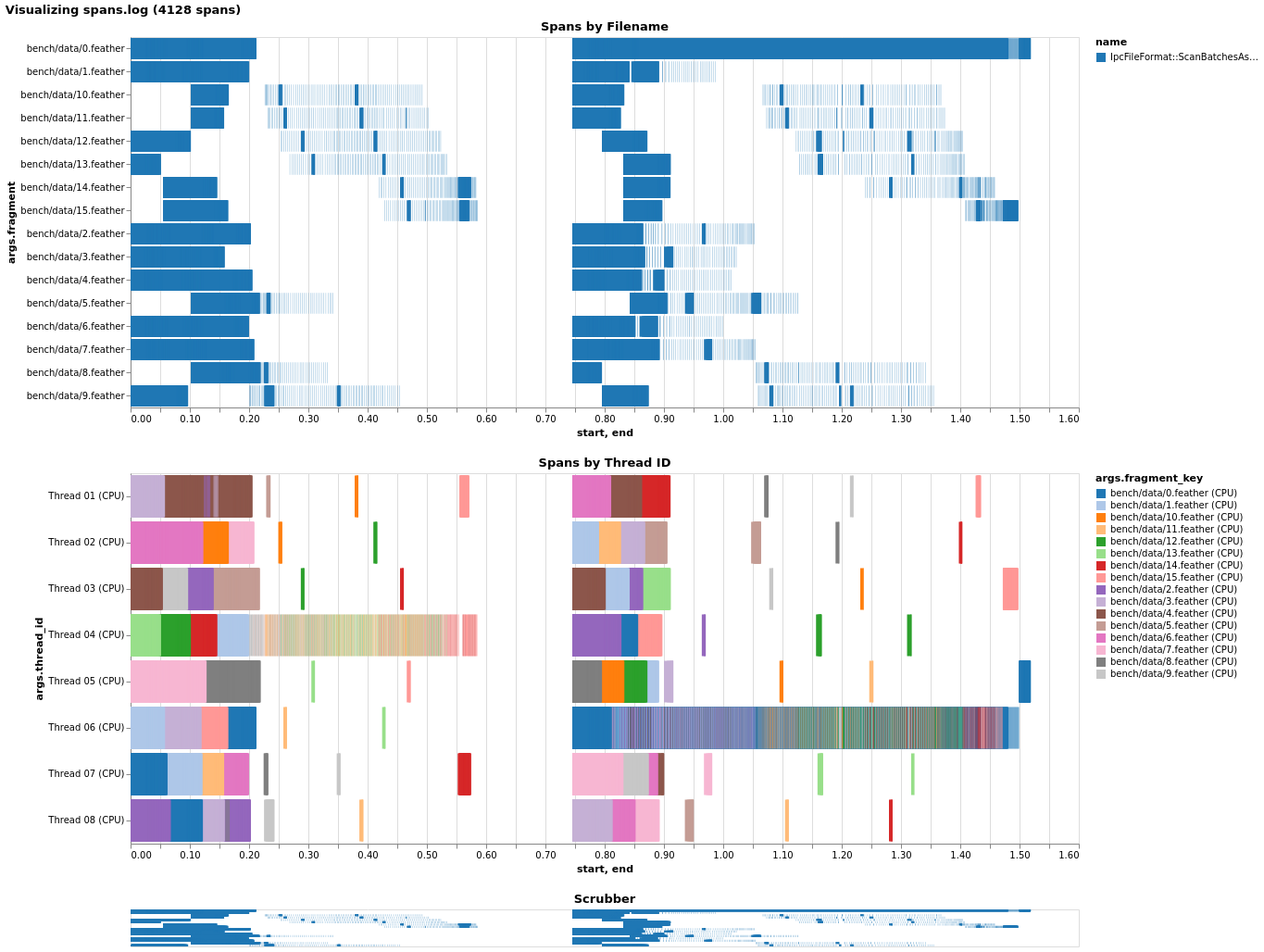 Before I saw that transferring the CPU task helped with this, and indeed, it does, though it doesn't quite get us on par. Also note I had to change the code to _force_ transfer by callling `Spawn` instead of just using `Transfer`. 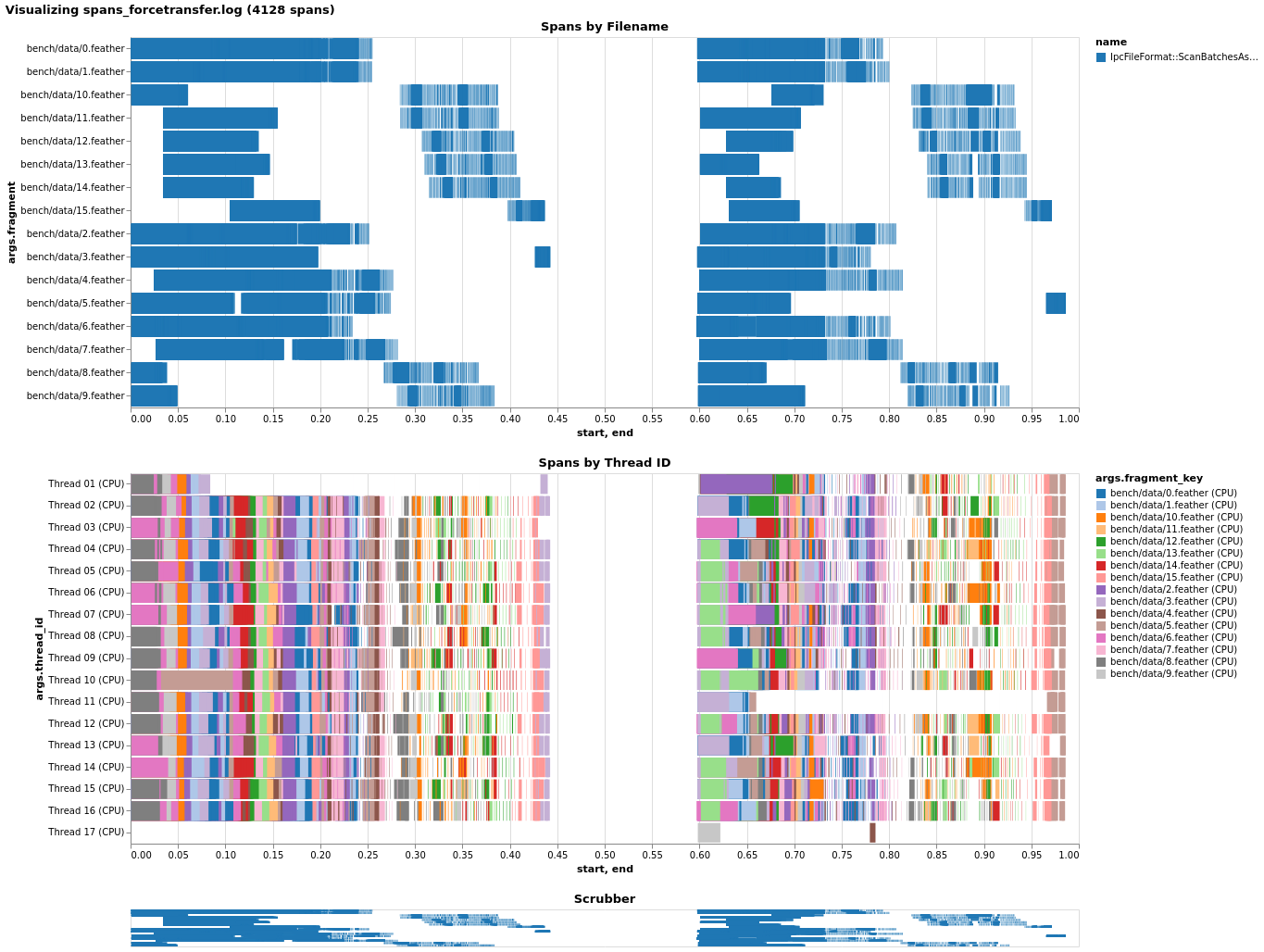 Given this, I'd guess what happens is as follows: with coalescing, since multiple record batches get mapped onto one I/O future, later requests to read a record batch will find an already-completed Future and will synchronously run all the callbacks inline, causing everything to pile onto the main thread. Forcing transfer alleviates this and better utilizes the thread pool, but the CPU-bound tasks are very fast (<< 1ms) and so we face the overhead of creating extra futures/spawning tasks instead. (Note that the non-pre-buffer case probably isn't even touching the CPU thread pool, because we don't transfer in that case - that's why you only see 16 threads (8 I/O + 8 CPU) in the last case.) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}