lidavidm commented on pull request #9620: URL: https://github.com/apache/arrow/pull/9620#issuecomment-854007519
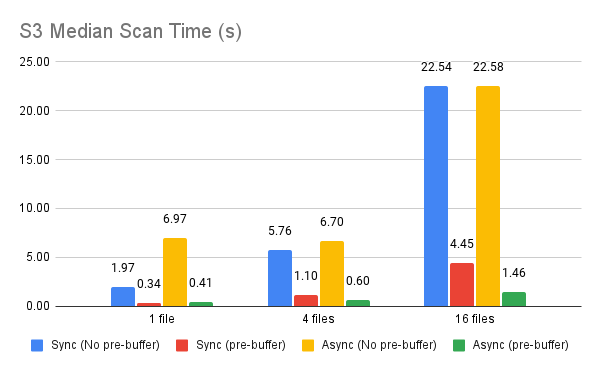 I re-tested S3 and also compared against the threaded reader with pre-buffering. I also corrected a logic error in file_parquet.cc that was leading to us needlessly spawning a thread. I also ran Conbench on the EC2 instance. It seems with that dataset, async doesn't make much of a difference. (Note that the bucket is in a different zone than my instance, though both are in the same region.) Threaded/pre-buffer: ``` "iterations": 10, "max": "10.805500", "mean": "10.117983", "median": "10.099560", "min": "9.663432", "q1": "9.919561", "q3": "10.197374", "stdev": "0.309781", ``` Async/pre-buffer: ``` "iterations": 10, "max": "10.660384", "mean": "9.774189", "median": "9.626739", "min": "9.297837", "q1": "9.391290", "q3": "10.127940", "run_id": "c3a226feb28e4025bc70fd2e90e405d4", "stdev": "0.460085", ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}