zeroshade commented on pull request #10716: URL: https://github.com/apache/arrow/pull/10716#issuecomment-896915175
@emkornfield Just to tack on here, another interesting view is looking at a flame graph of the CPU profile for the `BenchmarkMemoTableAllUnique` benchmark case, just benchmarking the binary string case where the largest difference between the two is that in the builtin Go Map based implementation I use a `map[string]int` to map strings to their memo index, whereas in the custom implementation I use an `Int32HashTable` to map the hash of the string to the memo index, with the hash of the string being calculated with the custom hash implementation. 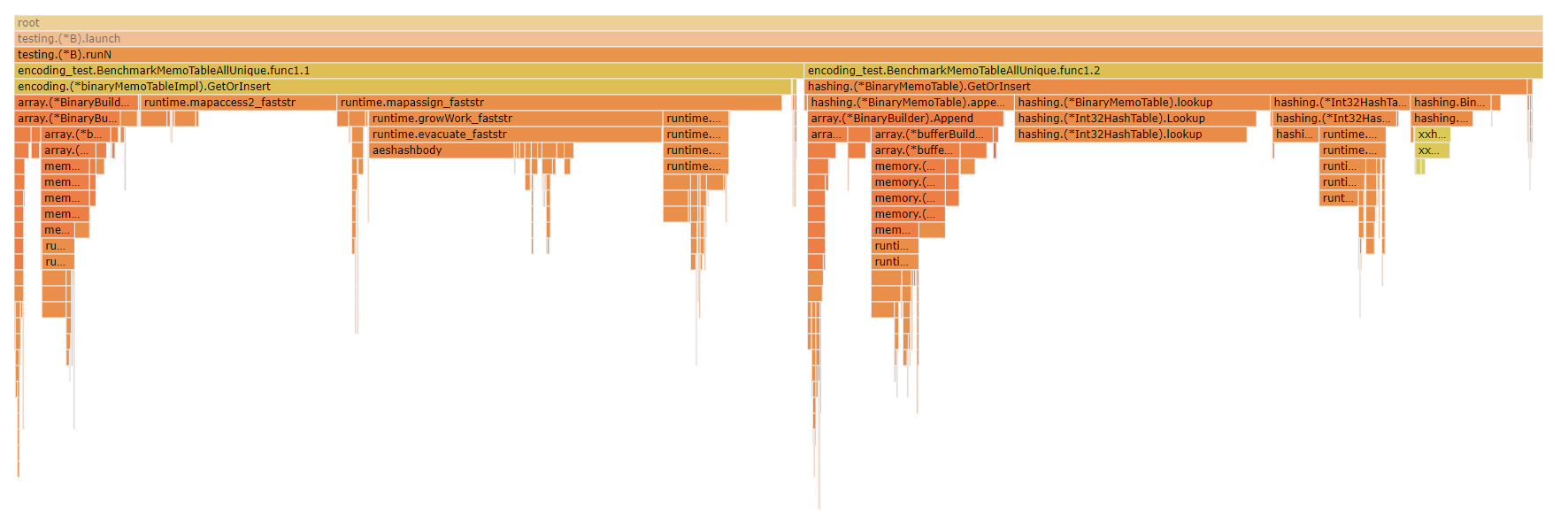 Looking at the flame graph you can see that a larger proportion of the CPU time for the builtin map-based implementation is spent in the map itself whether performing the hashes or accessing/growing/allocating vs adding the strings to the `BinaryBuilder` while in the xxh3 based custom implementation there's a smaller proportion of the time spent actually performing the hashing and the lookups/allocations. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}