alamb commented on a change in pull request #874:
URL: https://github.com/apache/arrow-rs/pull/874#discussion_r739658665
##########
File path: arrow/src/compute/kernels/comparison.rs
##########
@@ -477,6 +477,122 @@ pub fn nlike_utf8_scalar<OffsetSize:
StringOffsetSizeTrait>(
Ok(BooleanArray::from(data))
}
+/// Perform SQL `left ILIKE right` operation on [`StringArray`] /
+/// [`LargeStringArray`].
+///
+/// See the documentation on [`like_utf8`] for more details.
+pub fn ilike_utf8<OffsetSize: StringOffsetSizeTrait>(
Review comment:
I realize you are just following the pattern of nlike, but this function
is a lot of replication with the `like` kernel
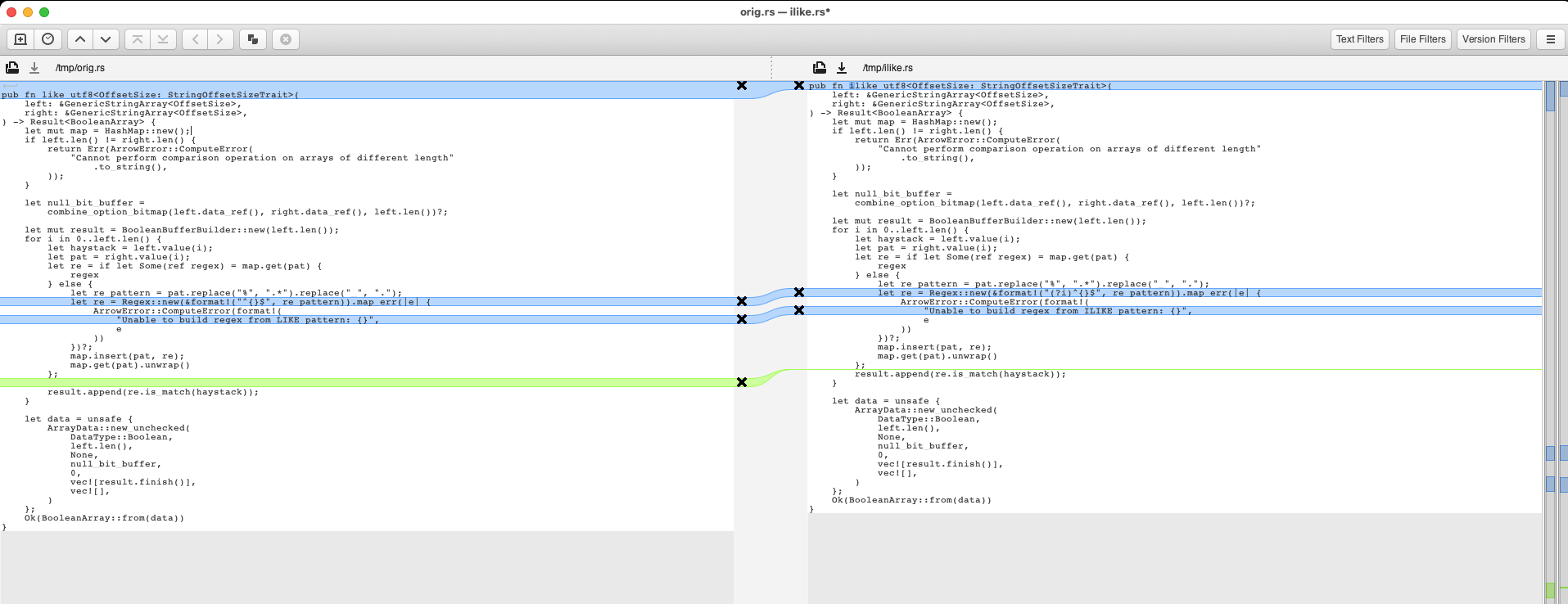
What do you think about refactoring so that the `like`, `nlike` and `ilike`
kernels all share most of the same common code?
Maybe something like this (untested)
```rust
fn regex_like<OffsetSize, F>(
left: &GenericStringArray<OffsetSize>,
right: &GenericStringArray<OffsetSize>,
) -> Result<BooleanArray>
where
OffsetSize: StringOffsetSizeTrait,
F: Fn(&str) -> Result<RegEx>
{
...
let re_pattern = pat.replace("%", ".*").replace("_", ".");
let re = F(&re_pattern)?;
...
}
```
And then ilike turns into
```rust
pub fn ilike_utf8<OffsetSize: StringOffsetSizeTrait>(
left: &GenericStringArray<OffsetSize>,
right: &GenericStringArray<OffsetSize>,
) -> Result<BooleanArray> {
regex_like(left, right, |re_pattern| {
Regex::new(&format!("(?i)^{}$", re_pattern)).map_err(|e| {
ArrowError::ComputeError(format!(
"Unable to build regex from ILIKE pattern: {}",
e
))
})
})
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}