Igosuki commented on issue #1205: URL: https://github.com/apache/arrow-datafusion/issues/1205#issuecomment-956559960
@alamb Thanks, I definitely agree with @jorgecarleitao over the dataset I'm using, Spark has comparable performance for parquet and avro for this reason, it reads directly into the in memory columnar format. This is the flamegraph using my integration branch with the optimisation in the linked PR. 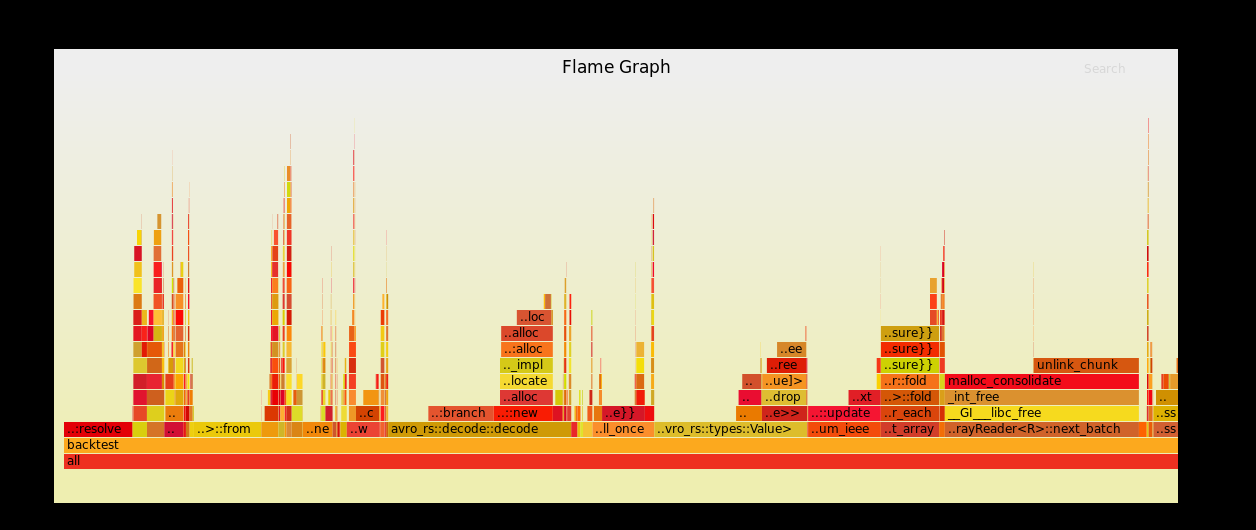 Mostly skewed by reading avro bytes, and dropping avro values, so decoding directly into arrow is the way to go. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}