houqp edited a comment on issue #1652: URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine. The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb. Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096): 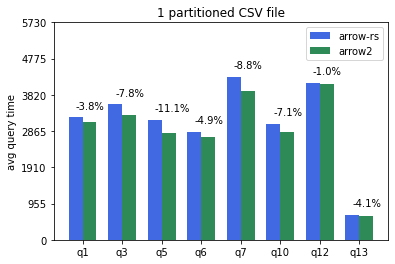 CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8): 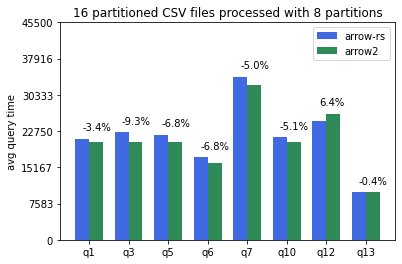 Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8): 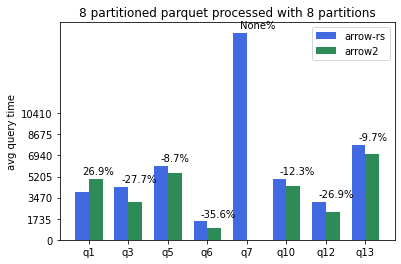 Note query 7 not able to complete with arrow2 due to OOM. Arrow2 parquet reader currently consumes almost double the memory is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768. Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?). I think both of these two regressions require deepdive before we merge arrow2 into master. Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}