TheNeuralBit commented on code in PR #23224:
URL: https://github.com/apache/beam/pull/23224#discussion_r1006249234
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -4092,13 +4271,22 @@ that are likely associated with that transaction (both
the user and product matc
"natural join" - one in which the same field names are used on both the
left-hand and right-hand sides of the join -
and is specified with the `using` keyword:
Review Comment:
Should this paragraph be in a language-java block? Similarly for the other
Java-only schema transforms - it seems theres a lot of language that needs to
be hidden when Python/Go are selected.
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -3815,6 +3863,14 @@ The following
purchasesByType.apply(Select.fieldNames("purchases{}.userId"));
{{< /highlight >}}
+{{< paragraph class="language-py" >}}
+Support for Nested fields hasn't been developed for python SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-go" >}}
+Support for Nested fields hasn't been developed for python SDK yet
Review Comment:
nit: in general can we make these paragraphs "Support for X hasn't been
developed for the {Python,Go} SDK yet."
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -3726,62 +3726,99 @@ a SQL expression.
Beam does not yet support Schema transforms natively in Go. However, it will
be implemented with the following behavior.
{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
#### 6.6.1. Field selection syntax
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
The advantage of schemas is that they allow referencing of element fields by
name. Beam provides a selection syntax for
referencing fields, including nested and repeated fields. This syntax is used
by all of the schema transforms when
referencing the fields they operate on. The syntax can also be used inside of
a DoFn to specify which schema fields to
process.
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
Addressing fields by name still retains type safety as Beam will check that
schemas match at the time the pipeline graph
is constructed. If a field is specified that does not exist in the schema, the
pipeline will fail to launch. In addition,
if a field is specified with a type that does not match the type of that field
in the schema, the pipeline will fail to
launch.
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
The following characters are not allowed in field names: . * [ ] { }
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
##### **Top-level fields**
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
In order to select a field at the top level of a schema, the name of the field
is specified. For example, to select just
the user ids from a `PCollection` of purchases one would write (using the
`Select` transform)
+{{< /paragraph >}}
{{< highlight java >}}
purchases.apply(Select.fieldNames("userId"));
{{< /highlight >}}
+{{< paragraph class="language-java" >}}
##### **Nested fields**
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
Individual nested fields can be specified using the dot operator. For example,
to select just the postal code from the
shipping address one would write
+{{< /paragraph >}}
{{< highlight java >}}
purchases.apply(Select.fieldNames("shippingAddress.postCode"));
{{< /highlight >}}
-
+
+<!-- {{< highlight py >}}
+input_pc = ... # {"user_id": ..., "shipping_address": "post_code": ...,
"bank": ..., "purchase_amount": ...}
+output_pc = input_pc | beam.Select(post_code=lambda item:
str(item["shipping_address.post_code"]))
+{{< /highlight >}} -->
+{{< paragraph class="language-java" >}}
##### **Wildcards**
+{{< /paragraph >}}
+{{< paragraph class="language-java" >}}
The * operator can be specified at any nesting level to represent all fields
at that level. For example, to select all
shipping-address fields one would write
+{{< /paragraph >}}
{{< highlight java >}}
purchases.apply(Select.fieldNames("shippingAddress.*"));
{{< /highlight >}}
+<!-- {{< highlight py >}}
+input_pc = ... # {"user_id": ..., "shipping_address": "post_code": ...,
"bank": ..., "purchase_amount": ...}
+output_pc = input_pc | beam.Select(shipping_address=lambda item:
str(item["shipping_address.*"]))
+{{< /highlight >}} -->
Review Comment:
```suggestion
<!--
{{< highlight py >}}
#TODO(https://github.com/apache/beam/issues/23275): Add support for
projecting nested fields
input_pc = ... # {"user_id": ..., "shipping_address": "post_code": ...,
"bank": ..., "purchase_amount": ...}
output_pc = input_pc | beam.Select("shipping_address.*"))
{{< /highlight >}} -->
```
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -4081,6 +4236,30 @@ The result of this aggregation will have the following
schema:
</tbody>
</table>
<br/>
+{{< /paragraph >}}
+
+{{< paragraph class="language-py" >}}
+The result of this aggregation will have the following schema:
+<table>
+ <thead>
+ <tr class="header">
+ <th><b>Field Name</b></th>
+ <th><b>Field Type</b></th>
+ </tr>
+ </thead>
+ <tbody>
+ <tr>
+ <td>key</td>
+ <td>ROW{userId:STRING}</td>
+ </tr>
+ <tr>
+ <td>value</td>
+ <td>ROW{num_purchases: INT64, total_spendcents: INT64, top_pdghurchases:
ARRAY[INT64]}</td>
Review Comment:
```suggestion
<td>ROW{num_purchases: INT64, total_spendcents: INT64, top_purchases:
ARRAY[INT64]}</td>
```
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -4092,13 +4271,22 @@ that are likely associated with that transaction (both
the user and product matc
"natural join" - one in which the same field names are used on both the
left-hand and right-hand sides of the join -
and is specified with the `using` keyword:
Review Comment:
If you'd rather not open that can of worms (there are a lot of schema
transforms...), we could also just edit the Select/GroupBy-relevant sections in
this PR, and leave the other ones as-is for now (and address in a follow-up PR).
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -3749,39 +3749,87 @@ the user ids from a `PCollection` of purchases one
would write (using the `Selec
purchases.apply(Select.fieldNames("userId"));
{{< /highlight >}}
+{{< highlight py >}}
+input_pc = ... # {"user_id": ...,"bank": ..., "purchase_amount": ...}
+output_pc = input_pc | beam.Select("user_id")
+{{< /highlight >}}
+
##### **Nested fields**
+{{< paragraph class="language-py" >}}
+Support for Nested fields hasn't been developed for python SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-go" >}}
+Support for Nested fields hasn't been developed for GO SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-java" >}}
Individual nested fields can be specified using the dot operator. For example,
to select just the postal code from the
shipping address one would write
+{{< /paragraph >}}
{{< highlight java >}}
purchases.apply(Select.fieldNames("shippingAddress.postCode"));
{{< /highlight >}}
-
+
+<!-- {{< highlight py >}}
+input_pc = ... # {"user_id": ..., "shipping_address": "post_code": ...,
"bank": ..., "purchase_amount": ...}
+output_pc = input_pc | beam.Select(post_code=lambda item:
str(item["shipping_address.post_code"]))
+{{< /highlight >}} -->
##### **Wildcards**
+{{< paragraph class="language-py" >}}
+Support for wildcards hasn't been developed for python SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-go" >}}
+Support for wildcards hasn't been developed for GO SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-java" >}}
The * operator can be specified at any nesting level to represent all fields
at that level. For example, to select all
shipping-address fields one would write
+{{< /paragraph >}}
{{< highlight java >}}
purchases.apply(Select.fieldNames("shippingAddress.*"));
{{< /highlight >}}
+<!-- {{< highlight py >}}
+input_pc = ... # {"user_id": ..., "shipping_address": "post_code": ...,
"bank": ..., "purchase_amount": ...}
+output_pc = input_pc | beam.Select(shipping_address=lambda item:
str(item["shipping_address.*"]))
+{{< /highlight >}} -->
##### **Arrays**
+{{< paragraph class="language-java" >}}
An array field, where the array element type is a row, can also have subfields
of the element type addressed. When
selected, the result is an array of the selected subfield type. For example
+{{< /paragraph >}}
+
+{{< paragraph class="language-py" >}}
+Support for Nested fields hasn't been developed for python SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-go" >}}
+Support for Nested fields hasn't been developed for GO SDK yet
+{{< /paragraph >}}
Review Comment:
```suggestion
{{< paragraph class="language-py" >}}
Support for Array fields hasn't been developed for python SDK yet
{{< /paragraph >}}
{{< paragraph class="language-go" >}}
Support for Array fields hasn't been developed for GO SDK yet
{{< /paragraph >}}
```
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -3815,6 +3863,14 @@ The following
purchasesByType.apply(Select.fieldNames("purchases{}.userId"));
{{< /highlight >}}
+{{< paragraph class="language-py" >}}
+Support for Nested fields hasn't been developed for python SDK yet
+{{< /paragraph >}}
+
+{{< paragraph class="language-go" >}}
+Support for Nested fields hasn't been developed for python SDK yet
Review Comment:
```suggestion
{{< paragraph class="language-py" >}}
Support for Map fields hasn't been developed for the Python SDK yet.
{{< /paragraph >}}
{{< paragraph class="language-go" >}}
Support for Map fields hasn't been developed for the Go SDK yet.
```
##########
website/www/site/content/en/documentation/programming-guide.md:
##########
@@ -4037,6 +4156,29 @@ The output schema of this is:
</tbody>
</table>
<br/>
+{{< /paragraph >}}
+
+{{< paragraph class="language-py" >}}
+<table>
+ <thead>
+ <tr class="header">
+ <th><b>Field Name</b></th>
+ <th><b>Field Type</b></th>
+ </tr>
+ </thead>
+ <tbody>
+ <tr>
+ <td>key</td>
+ <td>ROW{userId:STRING, bank:STRING}</td>
+ </tr>
+ <tr>
+ <td>values</td>
+ <td>ITERABLE[ROW[Purchase]]</td>
+ </tr>
+ </tbody>
+</table>
+<br/>
+{{< /paragraph >}}
Review Comment:
It looks like our paragraph shortcode doesn't work when it has a table in
it, both output schemas are shown:
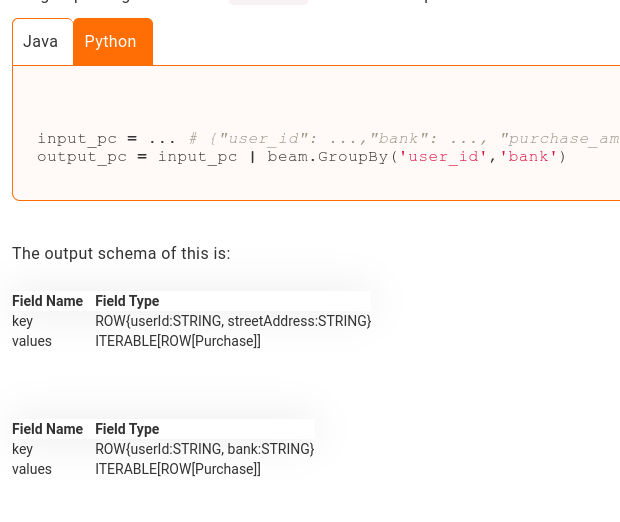
How about we just update the Java example to use "bank" instead of the
nested field? Then we can use the same output schema for both.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}