[
https://issues.apache.org/jira/browse/HDFS-16438?focusedWorklogId=714581&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-714581
]
ASF GitHub Bot logged work on HDFS-16438:
-----------------------------------------
Author: ASF GitHub Bot
Created on: 25/Jan/22 15:30
Start Date: 25/Jan/22 15:30
Worklog Time Spent: 10m
Work Description: tomscut opened a new pull request #3928:
URL: https://github.com/apache/hadoop/pull/3928
JIRA: [HDFS-16438](https://issues.apache.org/jira/browse/HDFS-16438).
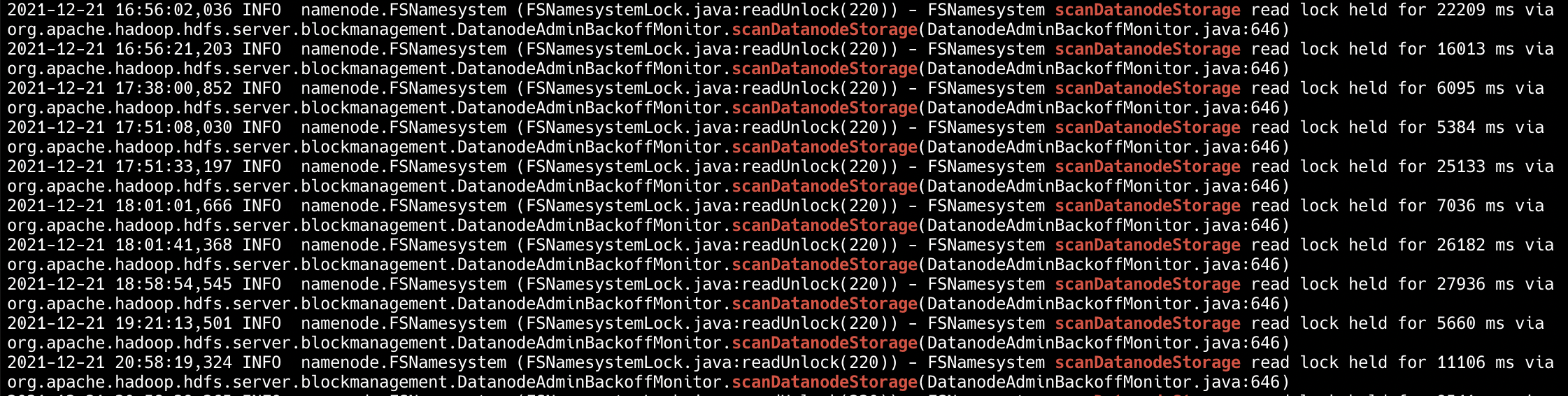
At the time of decommission, if use `DatanodeAdminBackoffMonitor`, there is
a heavy operation: `scanDatanodeStorage`. If the number of blocks on a storage
is large(more than 5 million), and GC performance is also poor, it may hold
**read lock** for a long time, we should optimize it.
```
2021-12-22 07:49:01,279 INFO namenode.FSNamesystem
(FSNamesystemLock.java:readUnlock(220)) - FSNamesystem scanDatanodeStorage read
lock held for 5491 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1032)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.readUnlock(FSNamesystemLock.java:222)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.readUnlock(FSNamesystem.java:1641)
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.scanDatanodeStorage(DatanodeAdminBackoffMonitor.java:646)
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.checkForCompletedNodes(DatanodeAdminBackoffMonitor.java:417)
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.check(DatanodeAdminBackoffMonitor.java:300)
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.run(DatanodeAdminBackoffMonitor.java:201)
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
java.lang.Thread.run(Thread.java:745)
Number of suppressed read-lock reports: 0
Longest read-lock held interval: 5491
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
Issue Time Tracking
-------------------
Worklog Id: (was: 714581)
Remaining Estimate: 0h
Time Spent: 10m
> Avoid holding read locks for a long time when scanDatanodeStorage
> -----------------------------------------------------------------
>
> Key: HDFS-16438
> URL: https://issues.apache.org/jira/browse/HDFS-16438
> Project: Hadoop HDFS
> Issue Type: Improvement
> Reporter: tomscut
> Assignee: tomscut
> Priority: Major
> Attachments: image-2022-01-25-23-18-30-275.png
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> At the time of decommission, if use {*}DatanodeAdminBackoffMonitor{*}, there
> will be a heavy operation: {*}scanDatanodeStorage{*}. If the number of blocks
> on a storage is large(more than 5 million), and GC performance is also poor,
> it may hold *read lock* for a long time, we should optimize it.
> !image-2022-01-25-23-18-30-275.png|width=764,height=193!
> {code:java}
> 2021-12-22 07:49:01,279 INFO namenode.FSNamesystem
> (FSNamesystemLock.java:readUnlock(220)) - FSNamesystem scanDatanodeStorage
> read lock held for 5491 ms via
> java.lang.Thread.getStackTrace(Thread.java:1552)
> org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1032)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.readUnlock(FSNamesystemLock.java:222)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.readUnlock(FSNamesystem.java:1641)
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.scanDatanodeStorage(DatanodeAdminBackoffMonitor.java:646)
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.checkForCompletedNodes(DatanodeAdminBackoffMonitor.java:417)
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.check(DatanodeAdminBackoffMonitor.java:300)
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminBackoffMonitor.run(DatanodeAdminBackoffMonitor.java:201)
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
> java.lang.Thread.run(Thread.java:745)
> Number of suppressed read-lock reports: 0
> Longest read-lock held interval: 5491 {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}