[
https://issues.apache.org/jira/browse/HDFS-16514?focusedWorklogId=744999&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-744999
]
ASF GitHub Bot logged work on HDFS-16514:
-----------------------------------------
Author: ASF GitHub Bot
Created on: 21/Mar/22 12:06
Start Date: 21/Mar/22 12:06
Worklog Time Spent: 10m
Work Description: liubingxing opened a new pull request #4088:
URL: https://github.com/apache/hadoop/pull/4088
JIRA: [HDFS-16514](https://issues.apache.org/jira/browse/HDFS-16514)
Recently, we used the [Standby Read] feature in our test cluster, and
deployed 4 namenode as follow:
node1 -> active nn
node2 -> standby nn
node3 -> observer nn
node3 -> observer nn
If we set ’dfs.client.failover.random.order=true‘, the client may failover
twice and wait a long time to send msync to active namenode.
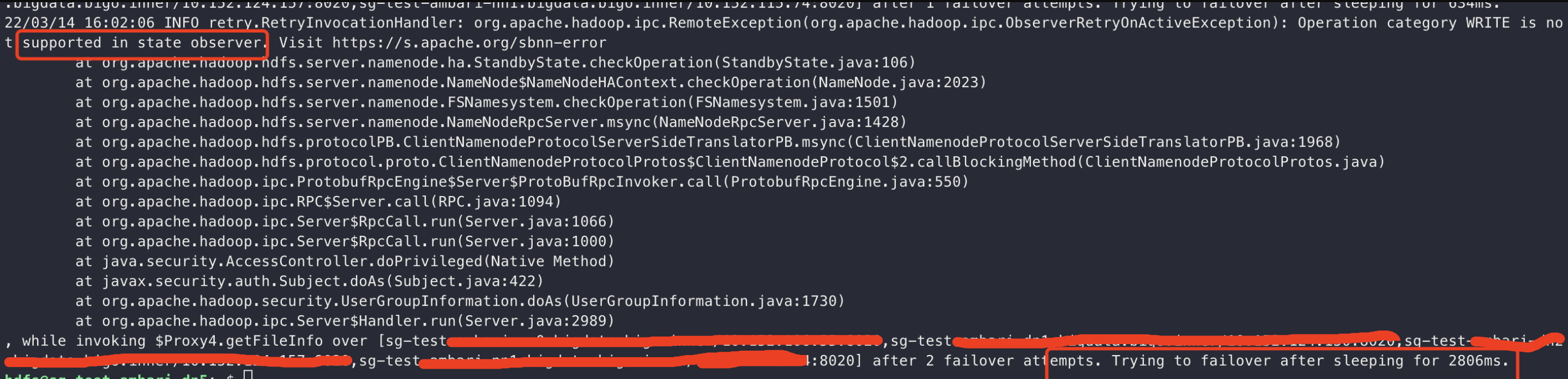
I think we can reduce the sleep time of the first several failover based on
the number of namenode.
For example, if 4 namenode are configured, the sleep time of first three
failover operations is set to zero.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
Issue Time Tracking
-------------------
Worklog Id: (was: 744999)
Remaining Estimate: 0h
Time Spent: 10m
> Reduce the failover sleep time if multiple namenode are configured
> ------------------------------------------------------------------
>
> Key: HDFS-16514
> URL: https://issues.apache.org/jira/browse/HDFS-16514
> Project: Hadoop HDFS
> Issue Type: Improvement
> Reporter: qinyuren
> Priority: Major
> Attachments: image-2022-03-21-18-11-37-191.png
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Recently, we used the [Standby Read] feature in our test cluster, and
> deployed 4 namenode as follow:
> node1 -> active nn
> node2 -> standby nn
> node3 -> observer nn
> node3 -> observer nn
> If we set ’dfs.client.failover.random.order=true‘, the client may failover
> twice and wait a long time to send msync to active namenode.
> !image-2022-03-21-18-11-37-191.png|width=698,height=169!
> I think we can reduce the sleep time of the first several failover based on
> the number of namenode
> For example, if 4 namenode are configured, the sleep time of first three
> failover operations is set to zero.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}