[
https://issues.apache.org/jira/browse/ARTEMIS-2852?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17258743#comment-17258743
]
Francesco Nigro commented on ARTEMIS-2852:
------------------------------------------
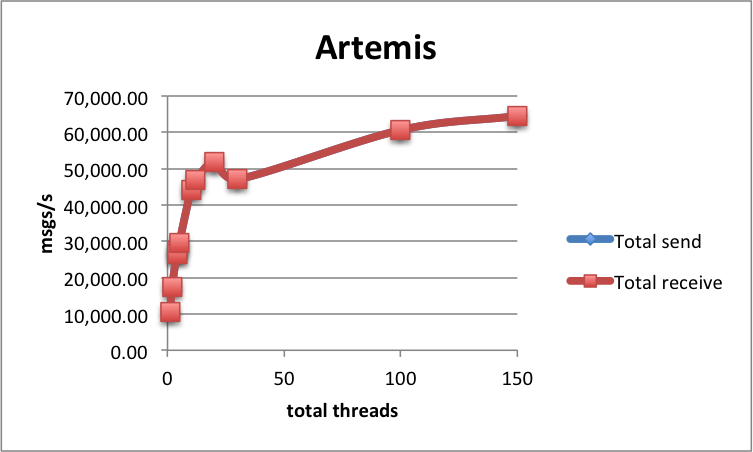
[~adamw1pl] I've looked at the new post on [https://softwaremill.com/mqperf/]
And it seems that the new behaviour shown on:
!https://softwaremill.com/user/pages/blog/mqperf/artemis.png?g-d425a3da|width=749,height=484!
Is different from the one on https://softwaremill.com/mqperf-2017/
!https://softwaremill.com/user/themes/softwaremill/assets/_old-website/uploads/2017/07/mqperf/artemis.png!
https://issues.apache.org/jira/browse/ARTEMIS-2877 should have already fixed
the scalability issue, but I see that
https://issues.apache.org/jira/browse/ARTEMIS-3045 could be a reasonable step
forward to improve the current behavior: I don't still get why 2.2.0 should
scale better then master itself, but I'll investigate on
https://issues.apache.org/jira/browse/ARTEMIS-3045 about it.
There is any chance you could check if
[https://github.com/franz1981/activemq-artemis/tree/batching_replication_manager]
is improving things?
I don't know how it works and if there are any chances to get the result on the
blog post updated at a certain point (before the next round); let me know...
> Huge performance decrease between versions 2.2.0 and 2.13.0
> -----------------------------------------------------------
>
> Key: ARTEMIS-2852
> URL: https://issues.apache.org/jira/browse/ARTEMIS-2852
> Project: ActiveMQ Artemis
> Issue Type: Bug
> Reporter: Kasper Kondzielski
> Assignee: Francesco Nigro
> Priority: Major
> Fix For: 2.16.0
>
> Attachments: Selection_433.png, Selection_434.png, Selection_440.png,
> Selection_441.png, Selection_451.png
>
>
> Hi,
> Recently, we started to prepare a new revision of our blog-post in which we
> test various implementations of replicated queues. Previous version can be
> found here: [https://softwaremill.com/mqperf/]
> We updated artemis binary to 2.13.0, regenerated configuration file and
> applied all the performance tricks you told us last time. In particular these
> were:
> * the {{Xmx}} java parameter bumped to {{16G (now bumped to 48G)}}
> * in {{broker.xml}}, the {{global-max-size}} setting changed to {{8G (this
> one we forgot to set, but we suspect that it is not the issue)}}
> * {{journal-type}} set to {{MAPPED}}
> * {{journal-datasync}}, {{journal-sync-non-transactional}} and
> {{journal-sync-transactional}} all set to false
> Apart from that we changed machines' type we use to r5.2xlarge ( 8 cores, 64
> GIB memory, Network bandwidth Up to 10 Gbps, Storage bandwidth Up to 4,750
> Mbps) and we decided to always run twice as much receivers as senders.
> From our tests it looks like version 2.13.0 is not scaling as well, with the
> increase of senders and receivers, as version 2.2.0 (previously tested).
> Basically is not scaling at all as the throughput stays almost at the same
> level, while previously it used to grow linearly.
> Here you can find our tests results for both versions:
> [https://docs.google.com/spreadsheets/d/1kr9fzSNLD8bOhMkP7K_4axBQiKel1aJtpxsBCOy9ugU/edit?usp=sharing]
> We are aware that now there is a dedicated page in documentation about
> performance tuning, but we are surprised that same settings as before
> performs much worse.
> Maybe there is an obvious property which we overlooked which should be turned
> on?
> All changes between those versions together with the final configuration can
> be found on this merged PR:
> [https://github.com/softwaremill/mqperf/commit/6bfae489e11a250dc9e6ef59719782f839e8874a]
>
> Charts showing machines' usage in attachments. Memory consumed by artemis
> process didn't exceed ~ 16 GB. Bandwidht and cpu weren't also a bottlenecks.
> p.s. I wanted to ask this question on mailing list/nabble forum first but it
> seems that I don't have permissions to do so even though I registered &
> subscribed. Is that intentional?
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
{kind=link}
{kind=link}