RubenMartinez97 opened a new issue, #34664:
URL: https://github.com/apache/arrow/issues/34664
### Describe the usage question you have. Please include as many useful
details as possible.
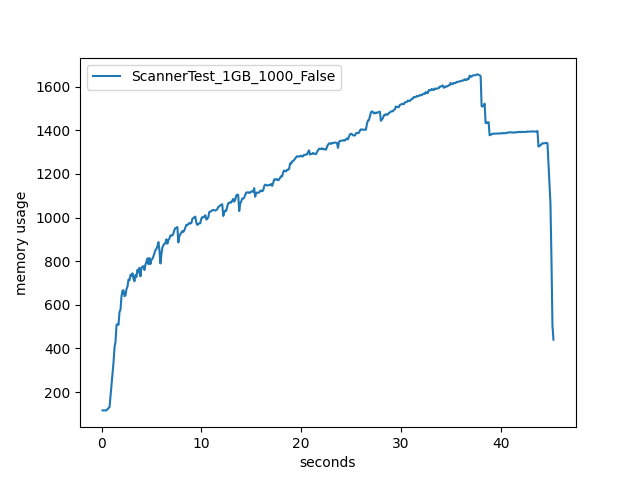
I am trying to create a table in duckdb using an arrow scanner on a dataset
of parquet files with a batch size of 1000 files, I realized that the more
files are processed, more memory is used and is not released until the end of
the scan, producing this certain memory problems if the dataset is very large.
I thought that only the part of the files scanned at that moment is loaded in
memory.
How can I solve this problem?
code:
```
con = duckdb.connect()
ds.dataset("parquet_folder")
my_arrow_dataset = ds.dataset('parquet_folder/')
arrow_scanner = ds.Scanner.from_dataset(my_arrow_dataset ,batch_size=1000)
con.execute("CREATE TABLE my_table AS SELECT * FROM arrow_scanner ")
```
### Component(s)
Python
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}