[
https://issues.apache.org/jira/browse/BEAM-13133?focusedWorklogId=671054&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-671054
]
ASF GitHub Bot logged work on BEAM-13133:
-----------------------------------------
Author: ASF GitHub Bot
Created on: 27/Oct/21 21:28
Start Date: 27/Oct/21 21:28
Worklog Time Spent: 10m
Work Description: TheNeuralBit commented on pull request #15818:
URL: https://github.com/apache/beam/pull/15818#issuecomment-953325521
I tested that this has the intended effect by running some Dataflow jobs
that do a `sample()` at the beginning of a series of DataFrame operations, both
with and without this change. Without the change:
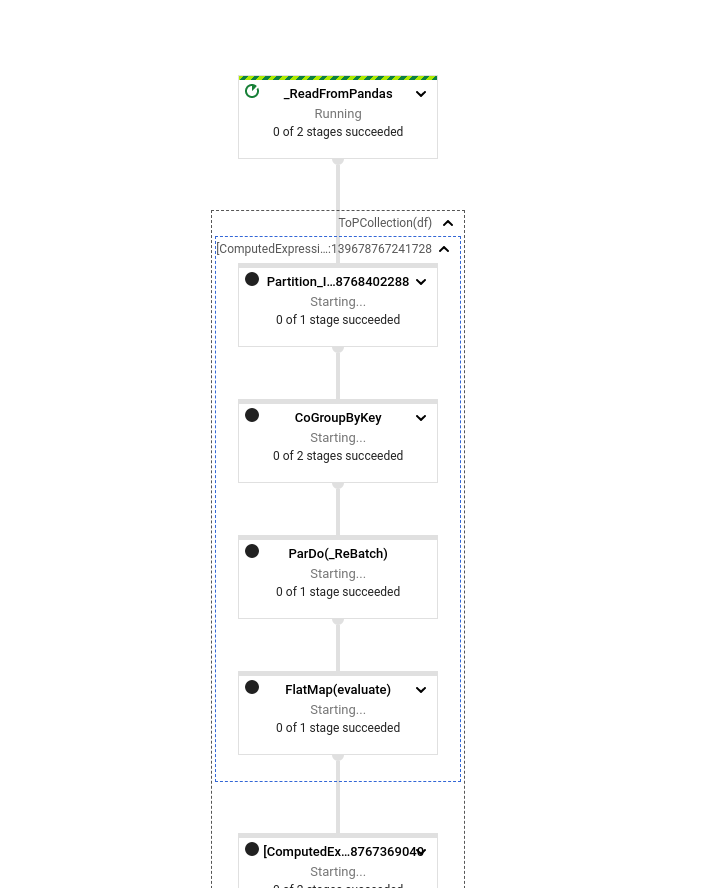
Note that we are assigning partitions and shuffling at the beginning of the
first stage, which is unnecessary.
With the change:
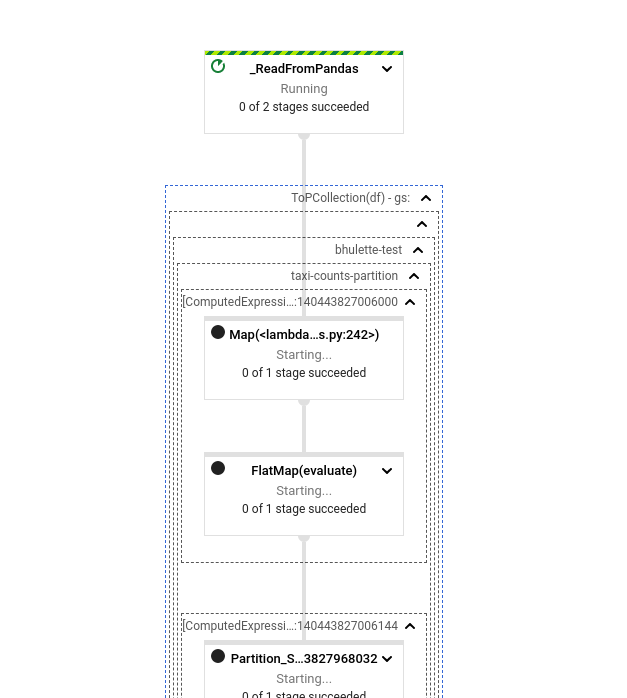
The first stage is executed _before_ the first shuffle (also it looks like
we need to do some escaping in the Python SDK? Including the file path in the
name has lead to some artificial composites)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
Issue Time Tracking
-------------------
Worklog Id: (was: 671054)
Time Spent: 1h (was: 50m)
> sample() imposes partitioning by index unnecessarily
> ----------------------------------------------------
>
> Key: BEAM-13133
> URL: https://issues.apache.org/jira/browse/BEAM-13133
> Project: Beam
> Issue Type: Bug
> Components: dsl-dataframe
> Reporter: Brian Hulette
> Assignee: Brian Hulette
> Priority: P2
> Fix For: 2.35.0
>
> Time Spent: 1h
> Remaining Estimate: 0h
>
> I noticed that sample() requires data to repartitioned when it's used at the
> beginning of a series of dataframe commands. In practice we should be able to
> sample within arbitrary partitions before combining the partitions to produce
> the final result.
> It looks like the root cause is that our sample expressions require
> partitioning by index, rather than arbitrary partitioning.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
{kind=link}
{kind=link}