[
https://issues.apache.org/jira/browse/BEAM-6693?focusedWorklogId=242901&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-242901
]
ASF GitHub Bot logged work on BEAM-6693:
----------------------------------------
Author: ASF GitHub Bot
Created on: 15/May/19 22:20
Start Date: 15/May/19 22:20
Worklog Time Spent: 10m
Work Description: Hannah-Jiang commented on pull request #8535:
[BEAM-6693] ApproximateUnique transform for Python SDK
URL: https://github.com/apache/beam/pull/8535#discussion_r284472831
##########
File path: sdks/python/setup.py
##########
@@ -125,6 +125,7 @@ def get_version():
'pyvcf>=0.6.8,<0.7.0; python_version < "3.0"',
'pyyaml>=3.12,<4.0.0',
'typing>=3.6.0,<3.7.0; python_version < "3.5.0"',
+ 'mmh3>=2.5.1; python_version >= "2.7"',
Review comment:
Thanks for asking this question. I was able to dig into more and found an
unexpected reason.
From 3.4, Python used SpiHash algorithm, before that, it used FNV algorithm.
Though SpiHash reduced collisions, I don't think it's noticeable from my test.
So I saw how hash values are distributed. Following graphs show how hash values
are distributed with different hash algorithm given exact the same data set.
Builtin hash function with Python 2 is not as uniformly distributed as other
hash functions (builtin hash function with Python 3 and mmh3). Though it's not
obvious from the graphs that hash values from mmh3 algorithms are more
uniformed distributed than the ones from builtin hash function with python 3,
test results shows that mmh3 has more uniformly distributed hash values.
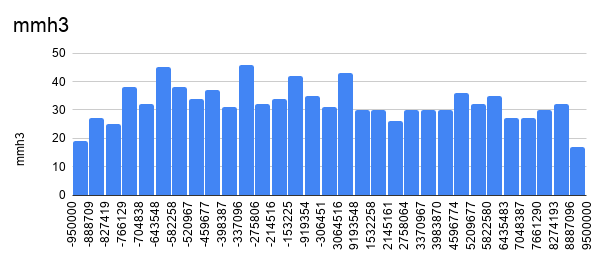
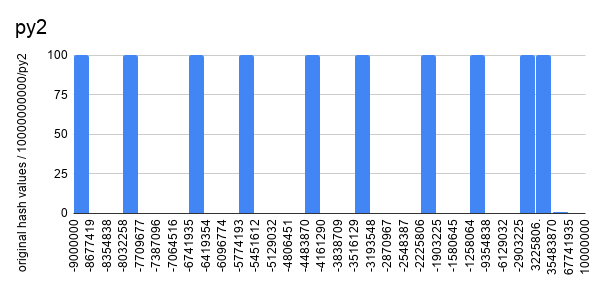
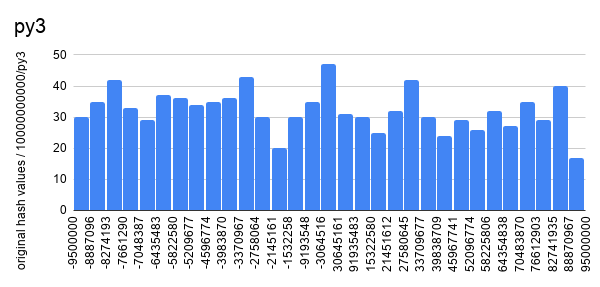
Why does it matter to approximate unique count? We are calculating sample
space with hash values and calculate population space from the sample space.
More uniformly distributed hash values give us more accurate sample space thus
we can calculate more accurate population space. The difference is more obvious
when we have more duplicate records with input.
A test case is generating 10000 elements within range of [0, 1000]. This
test consistently fails if we use builtin hash function with py2.7, and fails
sometimes with builtin hash function with py3 and hasn't fail with mmh3.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
Issue Time Tracking
-------------------
Worklog Id: (was: 242901)
Time Spent: 6h 20m (was: 6h 10m)
> ApproximateUnique transform for Python SDK
> ------------------------------------------
>
> Key: BEAM-6693
> URL: https://issues.apache.org/jira/browse/BEAM-6693
> Project: Beam
> Issue Type: New Feature
> Components: sdk-py-core
> Reporter: Ahmet Altay
> Assignee: Hannah Jiang
> Priority: Minor
> Time Spent: 6h 20m
> Remaining Estimate: 0h
>
> Add a PTransform for estimating the number of distinct elements in a
> PCollection and the number of distinct values associated with each key in a
> PCollection KVs.
> it should offer the same API as its Java counterpart:
> https://github.com/apache/beam/blob/11a977b8b26eff2274d706541127c19dc93131a2/sdks/java/core/src/main/java/org/apache/beam/sdk/transforms/ApproximateUnique.java
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}
{kind=link}
{kind=link}