[
https://issues.apache.org/jira/browse/BEAM-9434?focusedWorklogId=399637&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-399637
]
ASF GitHub Bot logged work on BEAM-9434:
----------------------------------------
Author: ASF GitHub Bot
Created on: 07/Mar/20 10:36
Start Date: 07/Mar/20 10:36
Worklog Time Spent: 10m
Work Description: ecapoccia commented on issue #11037: [BEAM-9434]
performance improvements reading many Avro files in S3
URL: https://github.com/apache/beam/pull/11037#issuecomment-596073078
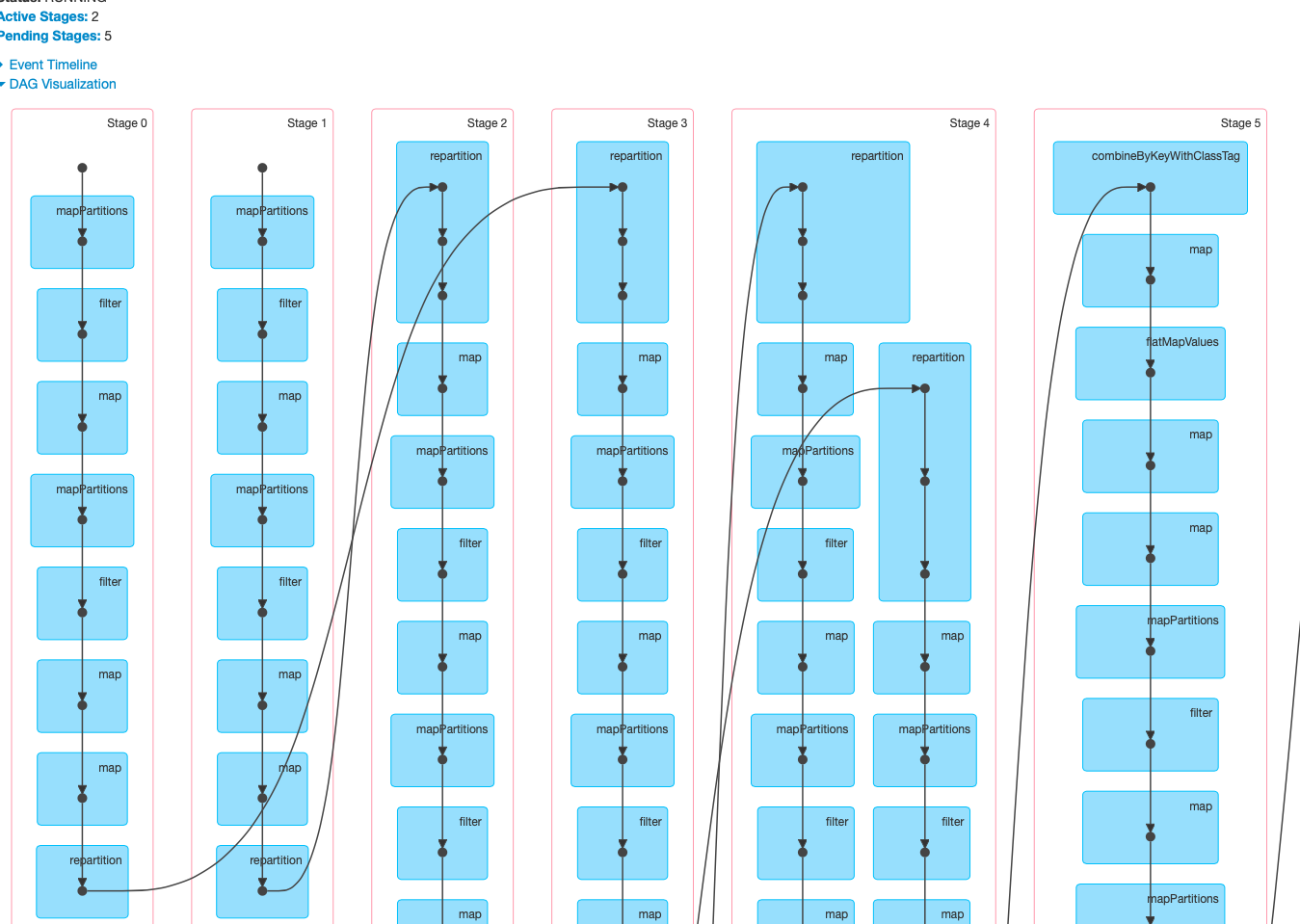
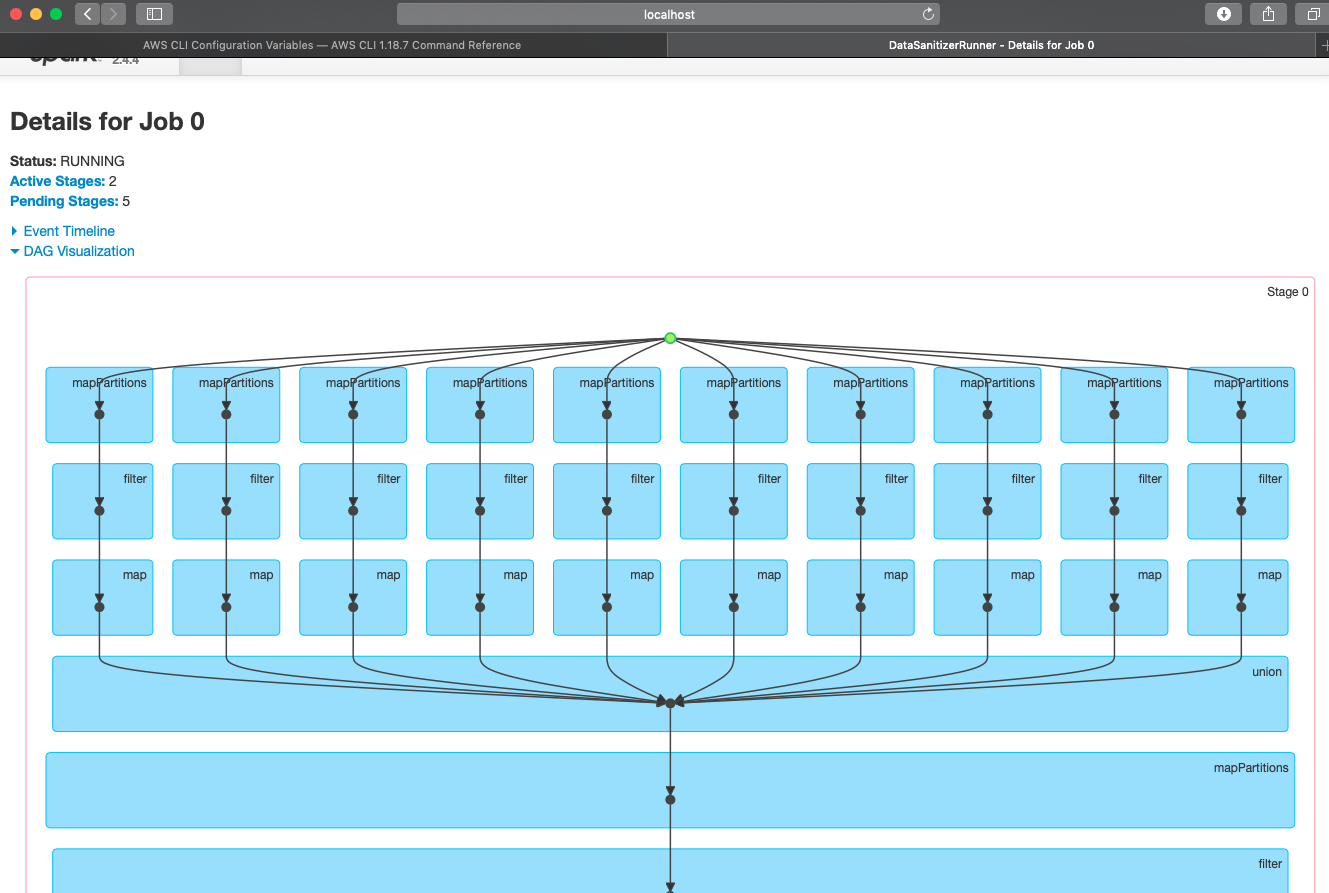
This is the fundamental difference between the base and the current PR.
Notice, in the base case there's only 2 tasks (the entire job is a join of two
independent readings) whereas when using 10 partitions there are 20 tasks for
doing the same work (the image is a detail of one of the two independent
readings, showing its 10 parallel partitions).
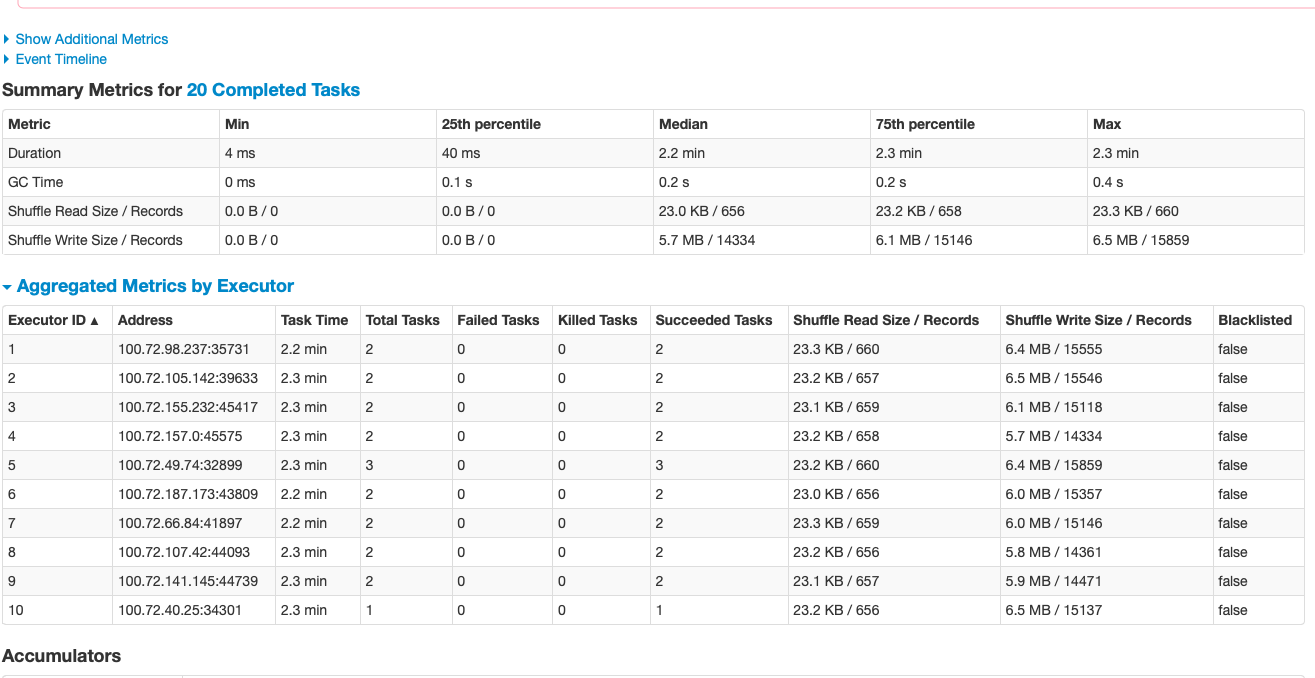
This is reflected in the executors being used and in the time to complete
(16 minutes with 2 tasks, 2.3 minutes with 20).
See below the comparison of execution data.
<img width="1461" alt="Screenshot 2020-03-07 at 10 33 25"
src="https://user-images.githubusercontent.com/8372724/76141746-24931500-605f-11ea-8c98-7b99587ae2a4.png";>
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
Issue Time Tracking
-------------------
Worklog Id: (was: 399637)
Time Spent: 1h 50m (was: 1h 40m)
> Performance improvements processing a large number of Avro files in S3+Spark
> ----------------------------------------------------------------------------
>
> Key: BEAM-9434
> URL: https://issues.apache.org/jira/browse/BEAM-9434
> Project: Beam
> Issue Type: Improvement
> Components: io-java-aws, sdk-java-core
> Affects Versions: 2.19.0
> Reporter: Emiliano Capoccia
> Assignee: Emiliano Capoccia
> Priority: Minor
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> There is a performance issue when processing a large number of small Avro
> files in Spark on K8S (tens of thousands or more).
> The recommended way of reading a pattern of Avro files in Beam is by means of:
>
> {code:java}
> PCollection<AvroGenClass> records = p.apply(AvroIO.read(AvroGenClass.class)
> .from("s3://my-bucket/path-to/*.avro").withHintMatchesManyFiles())
> {code}
> However, in the case of many small files, the above results in the entire
> reading taking place in a single task/node, which is considerably slow and
> has scalability issues.
> The option of omitting the hint is not viable, as it results in too many
> tasks being spawn, and the cluster being busy doing coordination of tiny
> tasks with high overhead.
> There are a few workarounds on the internet which mainly revolve around
> compacting the input files before processing, so that a reduced number of
> bulky files is processed in parallel.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
{kind=link}
{kind=link}
{kind=link}
{kind=link}