lordcheng10 opened a new issue #2984: URL: https://github.com/apache/bookkeeper/issues/2984
**BUG REPORT** ***Describe the bug*** The configuration is as follows: journalDirectories=/data1/bk-journal ledgerDirectories=/data2/bk-data,/data3/bk-data,/data4/bk-data data1~data4 are all physical disks. Online, we found that when read miss cache(At this time, data2~4 disks will have more reads.), At this time, the flush delay of the joint disk data1 has increased: 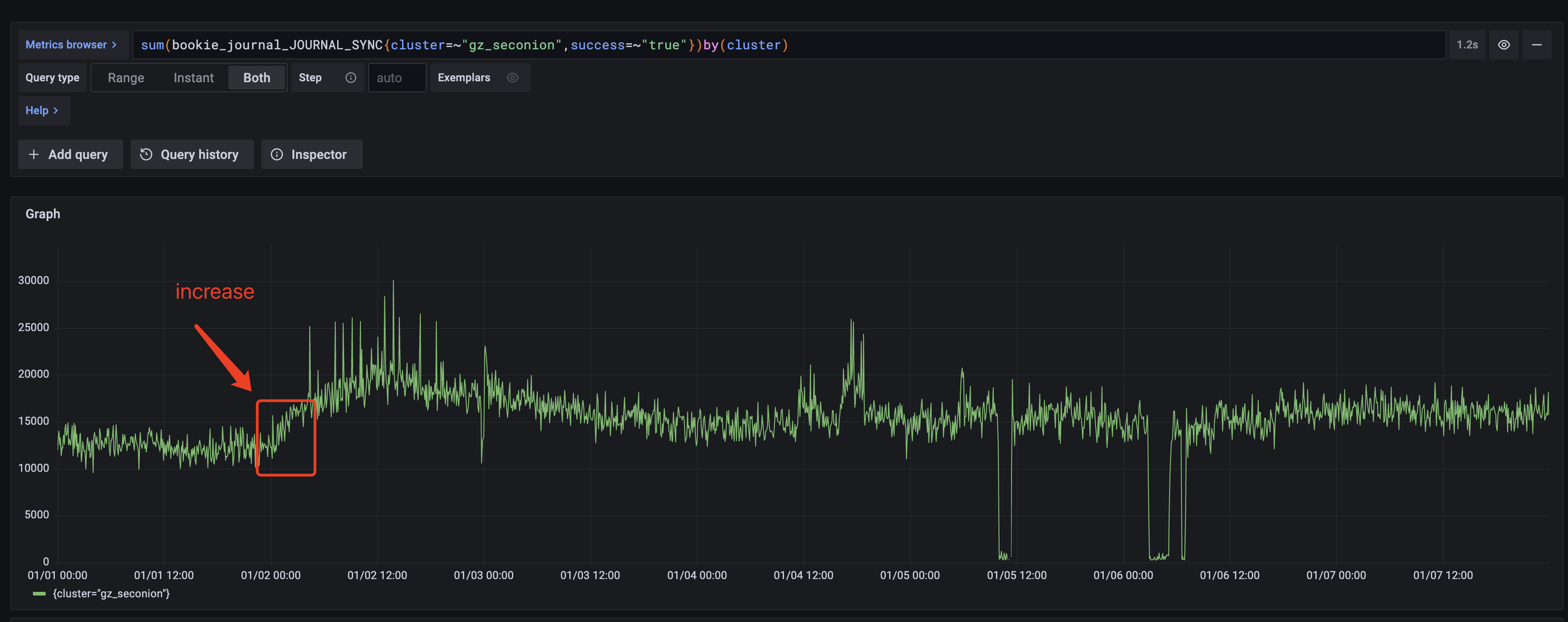 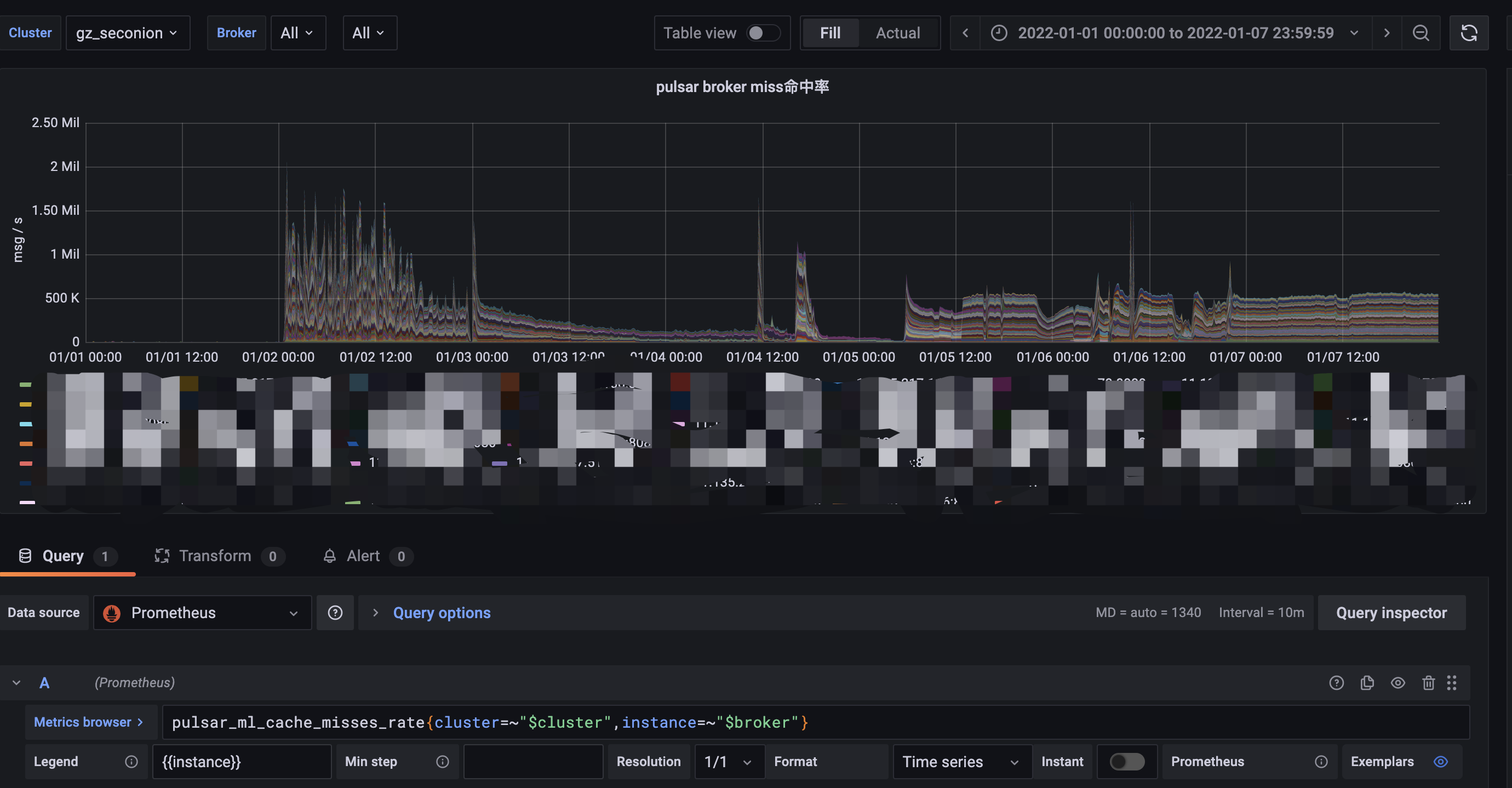 The indicator bookie_journal_JOURNAL_SYNC is mainly for the time-consuming statistics of the method org.apache.bookkeeper.bookie.JournalChannel#forceWrite: 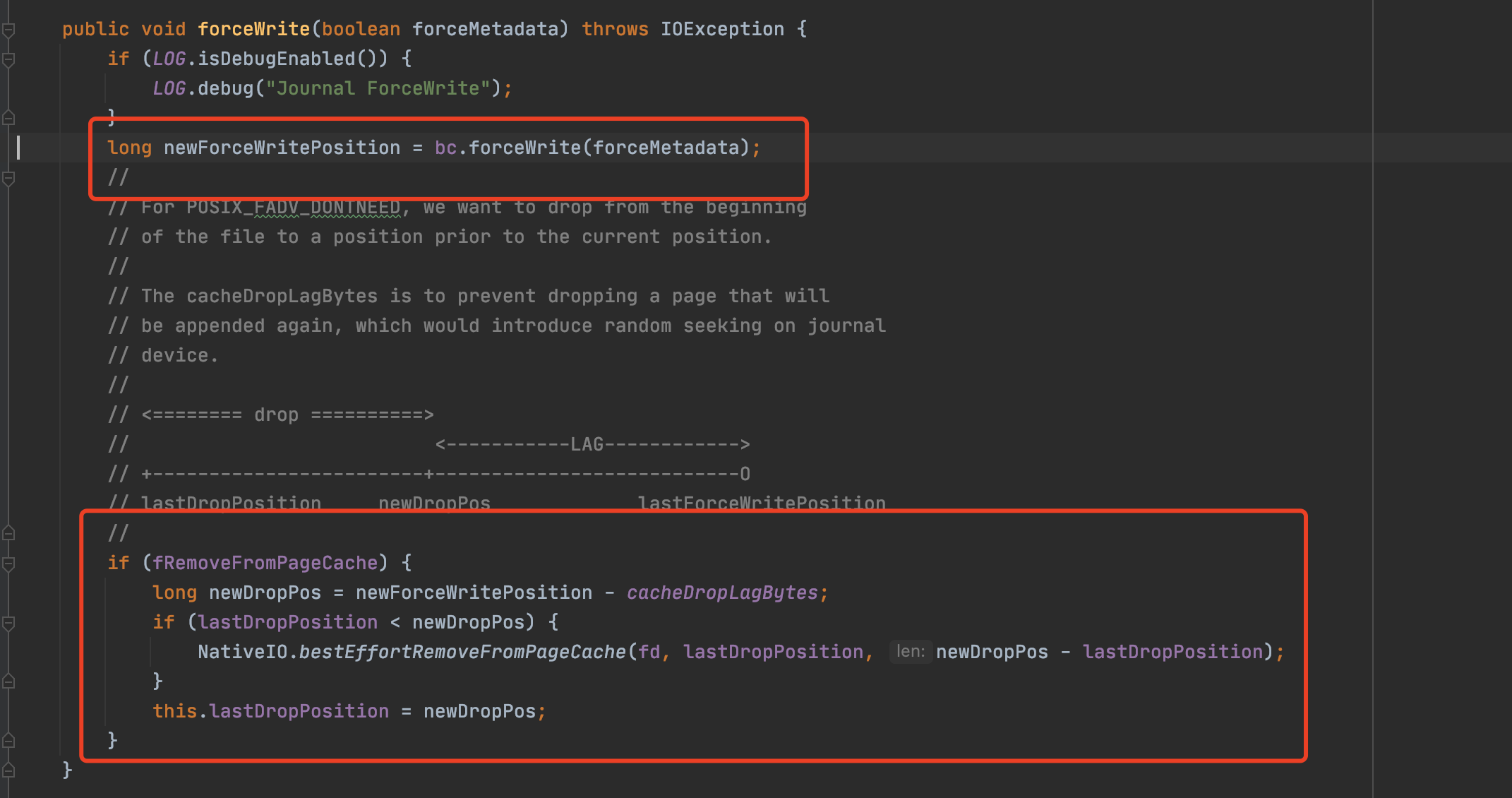 Since the journal disk is independent, the bc.forceWrite time-consuming should not be affected. So I suspect that NativeIO.bestEffortRemoveFromPageCache takes time to increase. I'm not particularly sure, but I have a guess: Due to a large amount of disk data being read, the pagecache is affected, which leads to an increase in the time required to call the bestEffortRemoveFromPageCache method here? So in order to prevent reads from affecting writes, should the default value of journalRemoveFromPageCache be set to false? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}